No one flaunts the acceptance of their parents' mortality, it is socially approved to wish their loved ones a long life.
But to want to live long is considered something bad, selfish, and accepting future death is considered wisdom.
From this we can draw the following conclusion: it is good to love others and wish them well; it is bad to love yourself and wish yourself well.
This is absurd. Of course, we should love ourselves and wish for ourselves everything that we wish for our loved ones. That is, prolongation of life and the absence of death in the longest possible perspective.
Yes, immortality is a goal. But if it's impossible, if the universe is doomed to a cold death, that doesn't devalue extending lifespan as much as possible.
We strive for immortality because every day we live is precious, which means we should live as many of them as possible.
Perhaps one of the reasons people don't want to acknowledge aging as a bad thing is that they fear ending up in a world where hundreds of thousands of people die every day for absolutely no reason.
Getting old shouldn't be viewed as inevitable, just because it happens to everyone. It's a disease that kills over 100,000 people a day, and hopefully it will be optional in the future.
@greek_scientist@PeterDiamandis@ParrishLiz What you're missing is the reason why the Hallmarks/Pillars are ever-expanding but the seven SENS categories are not. It's because the hallmarks are a classification of processes (of decline) while SENS classifies types of damage. That makes all the difference.
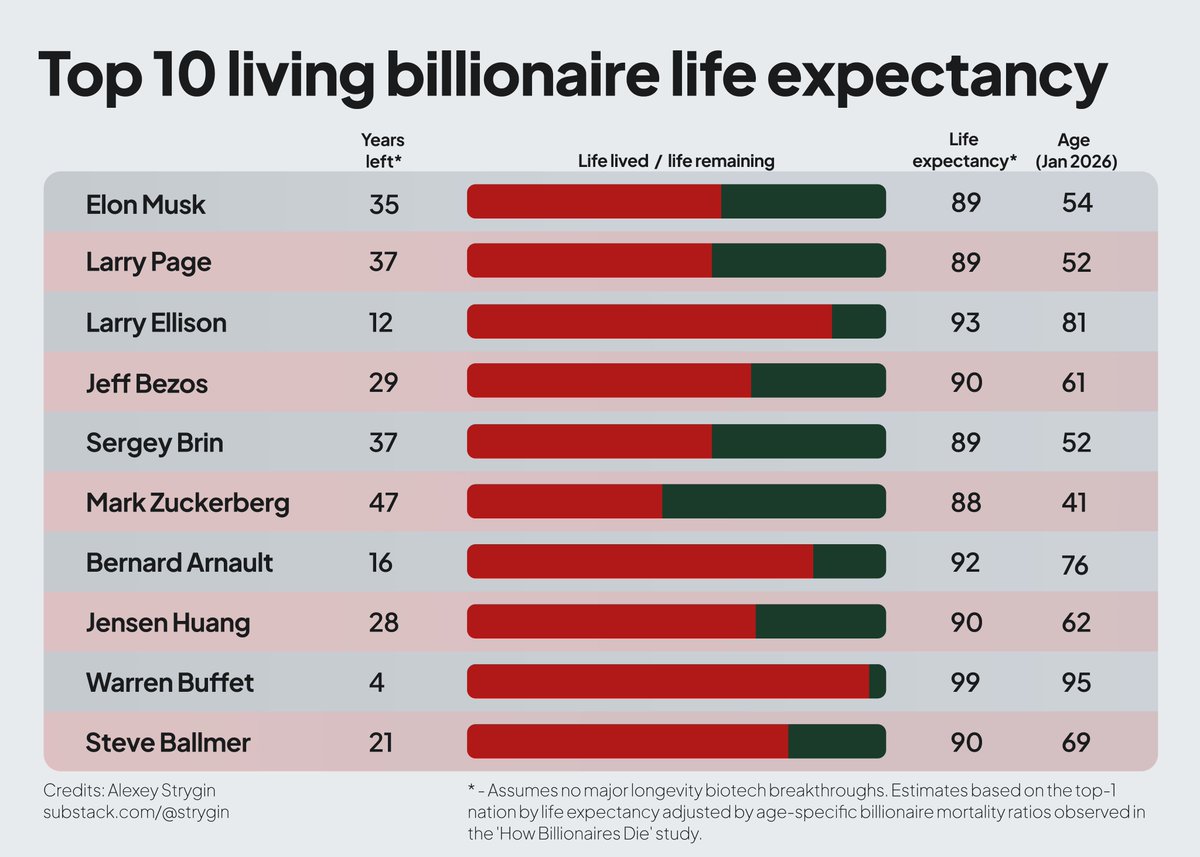
I calculated life expectancy for top billionaires based on my 'How Billionaires Die' research.
Pro-tip: fund longevity research today to live longer tomorrow
@elonmusk@JeffBezos@Forbes@davidasinclair@stats_feed
How amazing it is that we feel comfortable in our bodies.
Imagine you're a bunch of neurons in a bone-meat-skin shell that you control and fully sense, and you're comfortable right now.
The problem is that we have a lot of data on aging, and this creates the illusion that we have enough data to assemble a drug. We say: “Look, this thing changes with aging — let’s fix it, and aging will slow down.”
But the truth is that everything in the body changes with aging, there are a million such things, and we have no idea how they are connected to one another.
We have no solid causal map of aging.
We cannot say what the root causes of aging are — or even whether such root causes exist.
What kind of “anti-aging drug” can we talk about if we don’t even have an answer to the question: “What is aging?”
We lack an evolutionary understanding of aging.
In gerontology circles, the absurd idea dominates that aging is simply “in the shadow of natural selection.”
Seriously? Evolution detects the tiniest detail in a living system, but somehow ignores the elephant in the room.
Whenever “evolution needs it,” it instantly increases lifespan.
Why do closely related species differ so dramatically in lifespan?
When we talk about aging, it’s not even clear what we’re talking about.
Is it the accumulation of errors?
And what about the factors that determine the rate of error accumulation?
Is aging a single process or many?
Are there switches of aging?
Which nodes in the network give leverage in animals and in humans?
How are cellular aging and organismal aging connected?
And how significant is that connection at all?
How do energy metabolism → epigenetics → inflammation → ECM → immunity → stem cells → neuroendocrine circuits interact within one system?
Or is this very framing leading us in the wrong direction?
What do we need to know about the origin of life and the phenomenon of consciousness in order to control aging?
Can we view the evolution of life as the evolution of intelligent systems — and aging as a loss of goals?
What do we know about the hidden capacities of the organism?
We pay minimal attention to replacement as a method of life extension.
What is the minimal amount of tissue and organs that must be replaced in order to slow aging?
What is the maximum number of replacements a mammalian organism can endure without losing viability?
Even if we take aging from the perspective of the Hallmarks, how can we even compare principled strategies for choosing combinations?
We don’t even have a retrospective analysis of how combination-selection methods were chosen.
There is no methodological discussion at all.
People propose testing essentially random combinations based on arbitrarily selected facts.
Where is the list of facts that cannot be ignored when developing anti-aging therapies?
This is only part of the problem.
Geroscience is not ready to create an anti-aging drug, and it is not ready to understand where it currently stands.
Fundamental aging research is shrinking — without ever truly beginning — while money is diverted to people who promise to deliver an anti-aging drug in five years.
New essay: Animalcules and their Motors
A recent surge of research is revealing how flagella, the whip-like tails that bacteria use for locomotion, are not all created equal.
An E. coli flagellum spins around nearly 20,000 times per minute, whereas the flagellum in a microbe called Vibrio alginolyticus spins about five times faster, or slightly more than 100,000 times per minute. (For context, a Boeing 737 rotor has a maximum speed of 14,000 rpm.)
This extra rotary speed is because Vibrio cells must traverse the ocean, where ion gradients (used to drive the motors) are large and nutrients more spread out.
A microbe found in the human digestive system, Campylobacter jejuni, also has a flagellar motor that generates much more torque than the one in E. coli — about 3,600 piconewton-nanometers. It uses this higher torque to propel itself through the viscous environment of the human gut.
The flagellum is driven by stators, which are proteins embedded in the cell membrane (called MotA and MotB) through which protons flow from outside to inside. Every time a proton passes through this channel, MotA changes its shape ever so slightly, nudging a protein embedded in the rotor, called FliG. This happens around a million times each second, collectively spinning the tail tens of thousands of times per minute.
These stators are incredibly energy efficient, too. It takes about 50 protons to power one revolution of a stator, with more than 90 percent of available energy being converted into mechanical work. To put that into context, a typical combustion engine converts only 20-30 percent of the chemical energy stored in gasoline into mechanical work at the crankshaft. The rest is lost to heat and friction. The cell as a whole swims far less efficiently, though. Only about 0.2 percent of energy is transferred into forward motion, because much is lost to the drag of water at microscopic scales.
Earlier this year, a detailed structure of the high-torque C. jejuni motor was resolved for the first time. The structure revealed that the C. jejuni flagellum has 17 stators compared to the 11 in E. coli. These stators are also positioned further away from the central driveshaft, or axle, by a large, newly-evolved scaffold structure, which enables them to exert more leverage.
This paper is remarkable, in my view, because it reveals how Darwin’s admiration of evolution’s “endless forms most beautiful” also applies at the molecular scale. The flagellum is not a single design but a spectrum of mechanical solutions to the same problem: how to best move a cell.
Read & subscribe: https://t.co/jXzbza4jJW
I finally read the Kosmos "AI Scientist" paper from FutureHouse. Here is a bit about what they did and what I think about it.
> The general idea behind this paper, and others like it, is that science follows a series of steps and that much of these steps can be automated. Those steps are:
- Search the literature. Read stuff.
- Use your reading to come up with new hypotheses. Try to draw connections between things.
- Analyze data to draw conclusions. Write up your results.
- Repeat.
Kosmos uses two separate agents — one for data analysis and another for literature searches — to go out and do these tasks while sharing information with each other. The agents can see what the other agents have learned, in other words, which is super useful. They exist within a single "world model." A single run of Kosmos can execute up to 42,000 lines of code across 166 different data analysis agents, and also read 1,500 scientific papers using 36 literature review agents. Each run takes up to 12 hours.
So that’s the gist. You spin this thing up, give it a huge prompt, and then let it cook. In this preprint, they report seven discoveries that they say were made by Kosmos; “three discoveries made by Kosmos reproduce findings from preprinted or unpublished manuscripts,” which are not in its training dataset, “while the remaining four make novel contributions to the scientific literature.”
FutureHouse handed Kosmos to researchers around the world, working in myriad fields (electronics, neurology, materials, etc.), and let them test it out. Here are some of the “discoveries” they reported:
1. By feeding Kosmos some mouse brain metabolomics data, it suggested that cooling the brain’s temperature might activate nucleotide-salvage pathways, which basically preserves neurons during hypothermia. This had been shown in an unpublished paper and was later re-confirmed.
2. Using environmental sensor data from a recent arXiv paper, it identified a linear relationship between the solvent vapor on a solar cell and that cell’s current. In other words, humidity matters a lot? Not sure if this is surprising or not, as I have no background in this field. But again, it was a sort of “re-discovery” to see if Kosmos could find results that humans had already identified (but had not yet published.)
3. Higher levels of an enzyme, called superoxide dismutase 2, in the blood may reduce myocardial fibrosis. Published papers had previously identified a correlation between SOD2 and myocardial fibrosis, but Kosmos re-pointed at it and humans followed up to show it’s causal.
Here are my quick thoughts:
1. Many other AI scientists (both at nonprofits and for-profits, which have not yet been released) are trying to do the same thing. We clearly need better benchmarks to know what is real and what is fake. It seems like Kosmos is real, but how does this compare to Google etc?
2. I’m not wholly convinced that the idea of extremely long runs will be palatable to most biology researchers. My take is that researchers are looking for more of a real-time collaborator, where you’re constantly prompting and getting immediate feedback, rather than just delegating huge, open-ended tasks to agents. If a “general user” tests out Kosmos, pays the large price tag, and is disappointed by the results, will they keep using it? The wait time is a huge barrier, as is the price (even though academics get generous access.) Also difficult to prompt engineer?
3. This paper tries to quantify “the time it would take for a human scientist to complete the work that Kosmos performs in an individual run,” but I find it a bit hand-wavy. They say it takes a typical researcher 15 minutes to read a paper and 2 hours to write a Jupyter notebook for data analysis and, since Kosmos can read 1,500 papers per run, it offers a huge time savings.
But human scientists don’t need to read hundreds of papers to make a discovery! The best scientists have an innate ability to “triangulate to innovation;” to find the right combo of papers and discussions that enable them to make conceptual advances. This seems difficult to replicate.
I'd like to have more discussions about AI Scientists, if any of you are interested.