Most RAG systems work like this:
→ User asks question
→ Retrieve similar chunks
→ Send to LLM
→ Generate answer
The problem: question-to-chunk similarity is often weak.
Example: “How do I reset my password?”
That may not semantically match a documentation paragraph talking about authentication flows, account settings, or credential recovery.
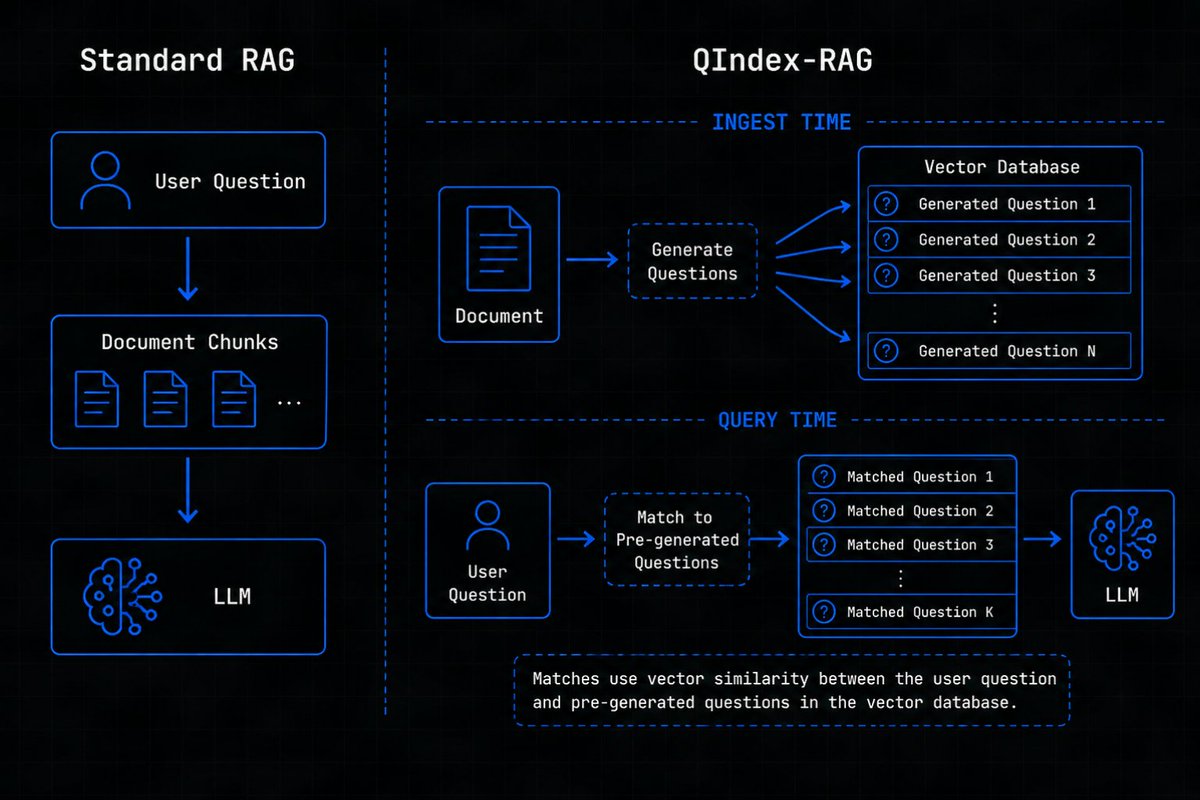
So I’m experimenting with a different retrieval approach:
At ingest time: generate possible questions each page can answer.
At query time: match question-to-question instead of question-to-chunk.
Early results:
→ significantly better retrieval relevance
→ fewer unnecessary tokens sent to the LLM
→ much cleaner context windows
Calling this approach: QIndex-RAG.
Still testing and refining it, but the retrieval quality improvement is already noticeable.
never store private keys in plain .env files
@PatrickAlphaC keeps saying this for a reason
but people still do it because the safer workflow is usually clunky
so i built vaultenv
a small npm package to store secrets encrypted locally, then load them into your shell only when needed
npm install -g codeswithroh/vaultenv
When you work with LLM APIs.
Before setting up the Response structure
Setup for request data, so LLM can get only the information that needed.
Otherwise
Garbage In, Garbage Out
Generating a simple tweet was costing us >>>>>>> 18,000+ tokens.
The prompt: ~400 tokens.
The tweet: 70 tokens.
So where did the other 17,500 go?
// GPT-5 Nano is a reasoning model. max_output_tokens doesn't just cap the output.
It caps reasoning + output combined.
The model was spending 17,000 tokens thinking before writing 70.
The fix wasn't a bigger cap.
It was a dynamic one:
>> inputTokens = ceil(promptChars / 4.5)
>> reasoning = max(4000, inputTokens × 5)
>> cap = outputBudget + reasoning
Why ×5?
Measured in production:
1,737 input → 7,273 reasoning tokens
That's x4.2, We use 5 for safety margin.
Short videos = small cap.
Long videos = large cap.
No waste. No truncation.
Reasoning models need reasoning budgets.
Not output limits.
@kirat_tw Yes, I'd faced same in this apis, when working in normal is fine, but when try to optimize to the best outcome, token limit, dynamic capping, prompt template - all are really a battle not all the things works like described in docs