📢 OneCanvas: 3D Scene Understanding via Panoramic Reprojection
We extract features from video frames and reproject them into one occlusion-free view of the whole scene that a 2D VLM reads just like a normal image. We can center this view on any viewpoint, including an agent's own pose for situated reasoning.
The same projection lets us create spatial training tasks with no human annotation, solvable only by reasoning over the 3D positions of real object features placed on an otherwise empty canvas.
The result is a stock 2D VLM that reasons in 3D, setting a new state of the art across spatial benchmarks at far less compute.
🌐 https://t.co/ilo141614B
▶️ https://t.co/lANFmN5gNy
Great work by @baranowskibrt & @davech2y
Nine papers accepted at #ECCV'26 🥳🎉🔥
Super exciting research on world models, 3D Gaussians (GPT), feed-forward reconstruction, virtual humans, agentic generative models, and much more!
Super proud of all students & collaborators :)
See you all in Malmö 🇸🇪
FlexAvatar Code Release 📢📢
Now you can create your own 3D head avatars from any portrait image!
Code for custom avatar creation, rendering and interactive GUI available at:
👉 https://t.co/m3mLgd3qxA
#iSchoolUI PhD student Wei Cao and Asst. Prof. Yaoyao Liu received a Best Paper Award at the 4th Workshop on Generative Models for Computer Vision at #CVPR2026. "FreeOrbit4D" introduces a new way to generate free-viewpoint videos from a single camera. ▶️ https://t.co/lliar3q0dt
Yesterday at the CVPR AC workshop I gave a talk arguing that correspondence is the "dark matter" of representation learning.
Not prominent in benchmarks. Not in training objectives. Yet it drives downstream performance more than ImageNet accuracy does.
🧵
The internet is full of video. So why can't novel view synthesis just scale on it?
Real-world video is simultaneously unposed, messy, and dynamic, breaking self-supervised NVS.
We fixed that. RayDer learns static-scene NVS from dynamic internet video, scaling like an LLM. A🧵
I really think that autoregression and diffusion is a false dichotomy -- they can easily co-exist (e.g., diffusion forcing). The real one is between discrete and continuous tokens.
📢📢GenRecon: Bridging Generative Priors for Multi-View 3D Scene Reconstruction📢📢
Reconstructing high-fidelity 3D scenes from sparse RGB input is hard. It needs a strong 3D prior!
We reformulate multi-view scene reconstruction as conditional 3D generation over overlapping spatial chunks, lifting posed image features into a generative shape prior via 3D conditioning. As an example prior, we build on Trellis2, and train it such that its reconstruction is pixel aligned and matches from all views.
GenRecon achieves unprecedented reconstruction quality from any sparse RGB input sequence, even from a phone capture. The reconstruction also includes PBR materials which facilitates relighting and virtual object insertion.
https://t.co/1RMD40WRpz
https://t.co/u4IEi5PTtn
Amazing work by @katha_schmid, @nicolasvluetzow, Jozef, @angelaqdai
Excited to share HOI-PAGE, to appear at #ICML2026! 🚀
@craigleili generates 4D human-object interactions zero-shot from text
A part-affordance graph grounds interactions via LLM+video priors, enabling complex multi-person, multi-object interactions
👉https://t.co/o0UQrhMgmt
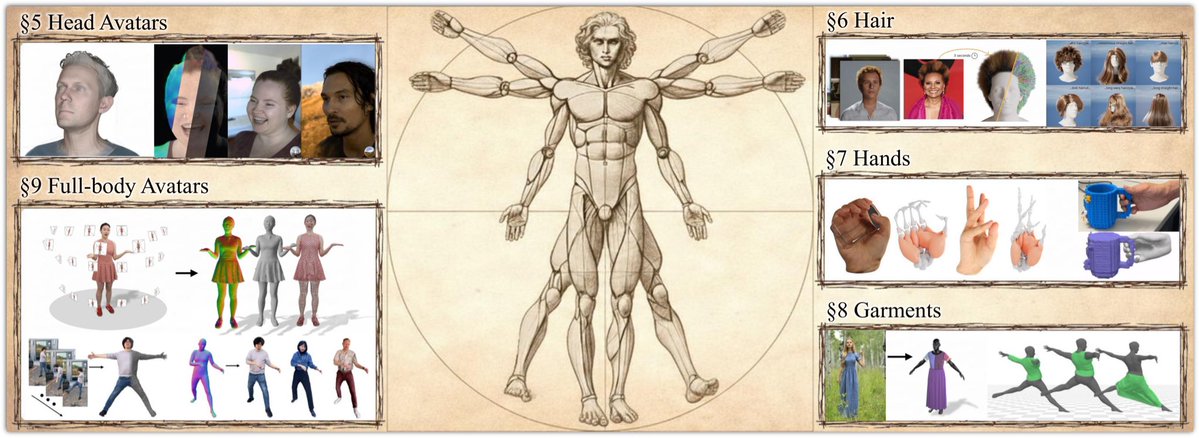
I am happy to share that our STAR has been accepted to Eurographics 2026:
“How to Build Digital Humans?”
It introduces a novel taxonomy and a concise overview of the full creation pipeline, from face and body to hands, garments, and hair.
https://t.co/E8YsdKpQGF
📢𝐁𝐈𝐆 𝐍𝐄𝐖𝐒: 𝐋𝐚𝐮𝐧𝐜𝐡𝐢𝐧𝐠 𝐄𝐜𝐡𝐨-𝟐 𝐓𝐨𝐝𝐚𝐲📢
My obsession with virtual environments started with childhood video games. But after years of research in 3D reconstruction and neural rendering, the bottleneck became obvious: we don't just need to generate better pixels. We needed a foundational model that natively understands space and the underlying physics.
That spatial grounding is exactly what you are seeing in the thread below.
Echo-2 enables a two-way flow of knowledge between reality and simulation. It is the bridge between capturing the physical world and building the high-fidelity simulations required to train tomorrow's robots.
"What I cannot create, I do not understand." — Richard Feynman.
🚀Echo-2 is here - our new world model!
These aren’t videos. These are 𝟑𝐃 𝐬𝐜𝐞𝐧𝐞𝐬. Generated from a single image.
- Stunning visual quality.
- Real-time rendering.
- Interactive camera control.
- Physically grounded.
🧵More details👇
Large foundation models have made enormous progress in modeling language, images, and video. These systems can generate highly realistic outputs and capture complex statistical structure in data. However, they still operate on projections of the world, text sequences and 2D pixel grids, rather than the world itself.
The real world is not a sequence of text tokens or frames; the real world is inherently anchored in 3D metric space, and dynamics across time. Objects occupy space and persist over time. They interact according to physical laws. Any model that aims to support real-world intelligence, e.g., for robotics, simulation, design, or spatial computing, must capture this structure.
This is where current approaches fall short. While most video models can generate visually plausible frames, they often lack a consistent notion of the underlying scene due to limited context windows. As a result, geometry drifts, scale is ambiguous, objects appear and disappear, and interactions are not physically grounded. The model produces superficial appearance without a persistent world representation.
For many downstream applications, this is not enough.
The first step toward addressing this is modeling 3D space and keeping it consistent. A model should recover a coherent spatial representation of the scene, including layout, geometry, and scale. This not only allows the environment to be rendered from new viewpoints but also, more critically, reasoned about in metric space. If a model cannot produce a stable 3D representation, it is not grounded in the physical world, and it will fail to model the world due to its inefficient contextual memory.
However, 3D is only the beginning.
A truly useful world model must also be temporally and physically consistent. It should not only reconstruct a scene, but also simulate it, predicting how it evolves, how objects interact, and what happens under intervention. Eventually this requires moving beyond static representations toward models that capture dynamics and causality.
I believe that generative approaches are highly compelling in this context, as they can be trained on large-scale data in a self-supervised fashion. In particular, comprehensive 3D world modeling is a highly-promising path forward, since richer environmental representations directly enable deeper and more effective learning of physical reality. Crucially, such generation enforces consistency: for instance, to generate a scene across viewpoints, a model must implicitly recover its underlying 3D structure. To generate it over time, it must capture its dynamics. This forces the model to internalize the latent state of the world, including geometry, scale, materials, motion, and physical behavior.
This also highlights a limitation of purely abstract representations. High-level embeddings or action-centric models can be effective for specific tasks, but without the ability to model and simulate the world, they will eventually remain incomplete. They compress observations, but do not fully model the underlying process that generates them.
The next generation of AI systems should therefore move beyond text and pixels, and toward physically-grounded world models: models that represent space, maintain consistency over time, and enable simulation and interaction.
This is the missing layer between the physical and digital world, which will ultimately enable AI systems not just to observe the world, but to understand and operate within it.
Introducing Omni, one unified model can support any-to-any multimodal modeling, including multimodal understanding, image/video generation and editing, world modeling and 3D reconstruction. All in one that adopts standard mixture-of-experts arch with only 3B activations.
📢Face Anything: 4D Face Reconstruction from Any Image Sequence
Transformer model for 4D face reconstruction and dense tracking:
- predict canonical facial coordinates per pixel
- tracking as reconstruction in canonical space
- geometry + correspondences in one forward pass
Key idea: a shared canonical space across frames
- correspondences as nearest neighbors
- no motion or deformation estimation
Stable geometry and tracking, even under large expressions and viewpoint changes - check out our results!
🌐 https://t.co/VRF2UFYo6Y
▶️ https://t.co/qMv8IKpy6R
Great work by @UmutKocasa4344, @SGiebenhain, @richard_o_shaw
🎉 After one year of teamwork, we are excited to release our 3D foundation model — LingBot-Map!
Unlike DA3/VGGT, LingBot-Map is a purely autoregressive model for streaming 3D reconstruction ⚡
It achieves ~20 FPS on 518×378 resolution over sequences exceeding 10,000 frames — and beyond 🚀
Two key insights behind LingBot-Map:
🔑 Keep SLAM's structural wisdom: build Geometric Context Attention with long-context modeling while maintaining a compact streaming state
🔑 Make everything end-to-end learnable — no optimization, no post-processing
Let's check out our demos 👇
🚀Announcing NeRSemble 3D Head Avatar Benchmark v2
Version 2 of the NeRSemble 3D Head Avatar Benchmark systematically evaluates several aspects of 3D head avatar creation. Our goal is to drive progress toward more realistic, robust, and generalizable avatar methods.
🔬Benchmark Tasks
The NeRSemble Benchmark v2 features three core challenges:
- Dynamic Novel View Synthesis
- Monocular FLAME-driven Avatar Creation (updated)
- Single-view 3D Face Reconstruction (new)
👉Explore the online leaderboard and submission system: https://t.co/dUdsFWzELp
🆕What's new?
1. New Task: Single-view 3D Face Reconstruction
Given a single portrait image, reconstruct an accurate 3D mesh either showing the input expression or a fully neutral one. Unlike prior benchmarks, the NeRSemble benchmark emphasizes diverse and challenging facial expressions, better reflecting real scenarios. For technical details, see the Pixel3DMM paper.
2. Updated task: Monocular FLAME-driven Avatar Creation
We have improved the FLAME tracking that is used for both avatar creation from the monocular videos and avatar driving on the hidden test sequences. The updated benchmark task has:
- more stable torso tracking
- more expressive lip closures during speech
- Improved mouth tracking for challenging facial expressions
We hope that these improvements to the benchmark help drive the field forward.
🏆 CVPR 2026 Workshop & Prizes
The NeRSemble benchmark will be featured at the CVPR 2026 Workshop on Photo-realistic 3D Head Avatars.
Participants in the new and updated tasks have the opportunity to win:
- 🎁RTX 5080 GPUs (sponsored by NVIDIA)
- 🎤15-minute oral presentation at the workshop
⏰ Submission Deadline
- May 26, 2026
Reach out to the amazing @TobiasKirschst1 and @SGiebenhain for more details :)
Got a paper on generative models accepted at CVPR 2026?
Share it with us at the 4th Workshop on Generative Models for Computer Vision!
https://t.co/zwzwRvD4o8
You can simply submit your accepted CVPR paper, no need to reformat!
Deadline: April 30 (AoE)
Excited to announce that FlexAvatar has been accepted to #CVPR26! 🥳
FlexAvatar can create a detailed and animatable 3D head avatar from any single portrait image.
Also check out the updated paper with more experiments:
https://t.co/jbMBCMpvli