Everyone talks about 1M context. The harder part is making 1M context actually usable. Serving MiniMax M3 required optimizing for long-context, multimodal, and agentic workloads simultaneously. Excited to see what developers build with it. 🚀
MiniMax-M3 combines 1M context, native multimodality, and MiniMax Sparse Attention.
The next layer is serving it efficiently: KV-block-major sparse attention, paged MSA decode, optimized index scoring, and multimodal preprocessing before the GPU worker.
Together’s Inference and Kernel teams improved throughput by 81–125% across common agentic-shape traffic.
We go deeper in this deep dive from @ywangfirstlean, @zhyncs42, @realDanFu and the team.
MiniMax-M3 combines 1M context, native multimodality, and MiniMax Sparse Attention.
The next layer is serving it efficiently: KV-block-major sparse attention, paged MSA decode, optimized index scoring, and multimodal preprocessing before the GPU worker.
Together’s Inference and Kernel teams improved throughput by 81–125% across common agentic-shape traffic.
We go deeper in this deep dive from @ywangfirstlean, @zhyncs42, @realDanFu and the team.
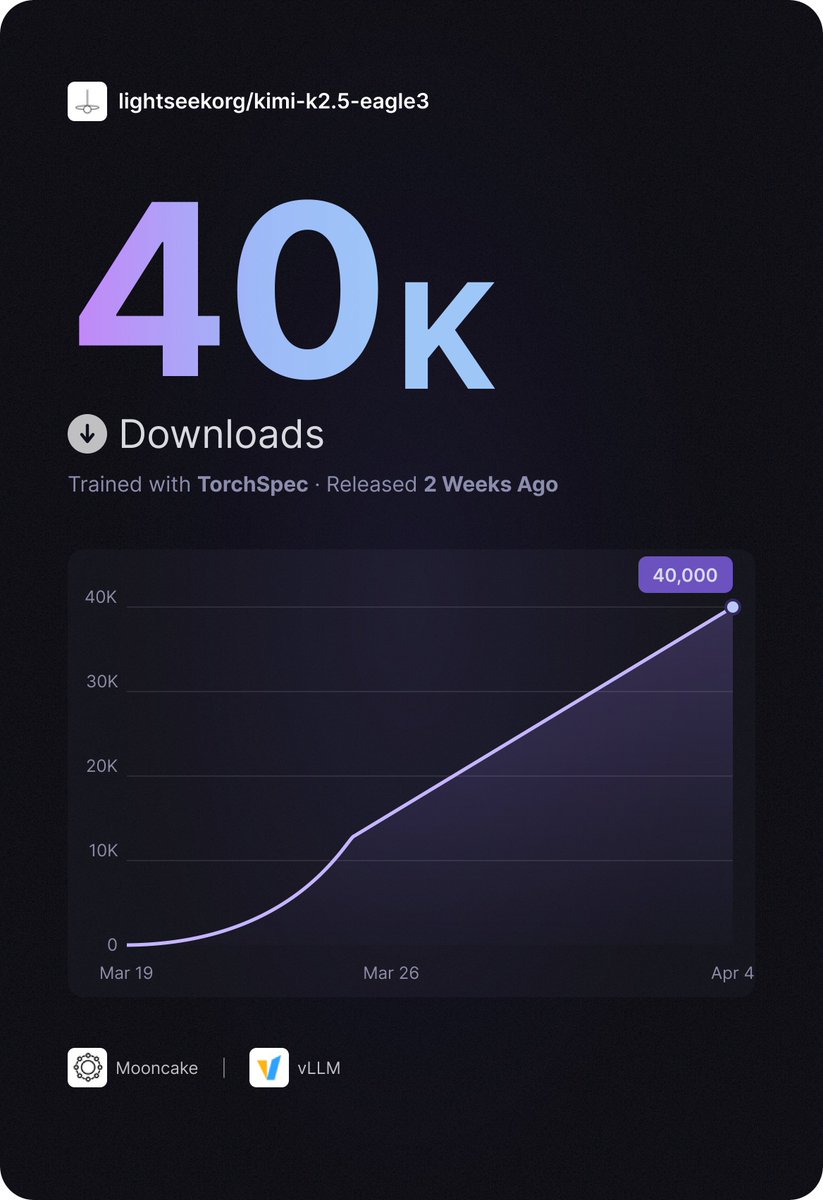
🚀TorchSpec has been live for 2 weeks — and kimi-k2.5-eagle3 just hit 40K downloads on HuggingFace!
Thanks to @KT_Project_AI Team and @vllm_project Team for the amazing collaboration.
Links in comments.