Excited to share that I will be joining UCSD CSE as an assistant professor in January 2026!
I'll be recruiting PhD students from the 2024 application pool - if you're interested in anything ML Sys/efficiency/etc please reach out & put my name on your application!
Until then I'll be finishing up some requirements at Stanford (long story...) and hanging out at @togethercompute. Stay tuned for more!
MiniMax-M3 combines 1M context, native multimodality, and MiniMax Sparse Attention.
The next layer is serving it efficiently: KV-block-major sparse attention, paged MSA decode, optimized index scoring, and multimodal preprocessing before the GPU worker.
Together’s Inference and Kernel teams improved throughput by 81–125% across common agentic-shape traffic.
We go deeper in this deep dive from @ywangfirstlean, @zhyncs42, @realDanFu and the team.
We took the Hot Wings Challenge to NVIDIA GTC 🌶️
@realDanFu (VP of Kernels) and @sarung (VP of Customer Success) answered some questions around AI, one spicy wing at a time.
Some people sweat. Some people talk. Watch to see who did both.
We took the Hot Wings Challenge to NVIDIA GTC 🌶️
@realDanFu (VP of Kernels) and @sarung (VP of Customer Success) answered some questions around AI, one spicy wing at a time.
Some people sweat. Some people talk. Watch to see who did both.
The dominant story in AI has been the growing cloud: bigger clusters, larger models, more gigawatts.
We believe the future is in the opposite direction: on-device inference, smaller models, watts instead of gigawatts.
Today we're releasing @OpenJarvisAI v1.0: a personal AI assistant that lives, learns, and works on your device.
The dominant story in AI has been the growing cloud: bigger clusters, larger models, more gigawatts.
We believe the future is in the opposite direction: on-device inference, smaller models, watts instead of gigawatts.
Today we're releasing @OpenJarvisAI v1.0: a personal AI assistant that lives, learns, and works on your device.
Our inference stack, optimized for Blackwells, with a novel attention kernel and many new optimizations has started rolling out!
It's already charting on Artificial Analysis, eg: #1 speed and latency for @Kimi_Moonshot Kimi 2.6. #1 on latency on @MiniMax_AI, and miles ahead of other GPU endpoints.
https://t.co/Yx6rIcZPyk
https://t.co/AdORQ3GLu9
New in-depth blog post: "Dissecting ThunderKittens: Anatomy of a Compact DSL for High-Performance AI Kernels"
This post is my attempt to dissect ThunderKittens from the bottom up. I approached TK by asking what each abstraction is really buying us: which hardware detail it corresponds to, how it maps onto the underlying layouts the GPU actually wants, what boilerplate it removes, and which parts of the GPU programming model still remain visible to us as kernel authors.
The post walks through the tile abstractions TK provides: register, shared, and tensor memory tiles, global layouts, vector abstractions, warp/warpgroup compute, TMA, swizzling, Hopper WGMMA, Blackwell tcgen05, 2xSM MMA, tensor memory, Cluster Launch Control, TK’s pipeline templates, and static persistent tile scheduling.
At the end, I demonstrate TK’s lcf pipeline template by implementing a non-causal attention prefill kernel and benchmarking it against FlashAttention-2 and FlashAttention-3 on an H100 PCIe across different sequence lengths. The kernel beats FA2 across the sweep by ~1.55x on average, and closely tracks FA3, where FA3 is only ~1.05x-1.17x faster on the longer sequence lengths.
Blog link: https://t.co/t29Z6jVF87
Repo: https://t.co/3gsRd25QwL
I also put an extensive list of resources at the end, which I found very useful for interested readers.
Please note: this is my own independent writeup. I’m not affiliated with @HazyResearch, and any mistakes in the post are mine. If you spot any please reach out!
1 / xx
✈️ Flying out to Bellevue for #MLSys2026! My students and collaborators are presenting two papers, and I'll be around through Wednesday afternoon.
Come find me if you want to chat Parcae, looped models, kernels, kittens (Thunder-, Hip-, and more), OSS models, or anything else!
Congrats to the @cursor_ai team on Composer 2.5 — a huge milestone for agentic coding models.
Together AI, the AI Native Cloud, is proud to partner on this launch. Composer 2.5 is pushing the frontier for coding agents and turning heads for its speed and quality.
Excited to keep building with the Cursor team!
Congrats to the @cursor_ai team on Composer 2.5 — a huge milestone for agentic coding models.
Together AI, the AI Native Cloud, is proud to partner on this launch. Composer 2.5 is pushing the frontier for coding agents and turning heads for its speed and quality.
Excited to keep building with the Cursor team!
This is pretty cool - LLM inference that generates @prlnet coins during the forward pass, so you can subsidize inference cost. Excited to see how this changes inference tokenomics!
A milestone for Pearl Research Labs: our first major enterprise partnership is live with Together AI.
@togethercompute’s inference platform is an ideal demonstration of @prlnet's value proposition — One of the world’s most advanced hyperscalers running AI workloads on Pearl’s 2-for-1 Cuda kernels, turning inference into ¶PRL coins, and reducing consumer LLM price per token. Excited for what we’ll build together.
A milestone for Pearl Research Labs: our first major enterprise partnership is live with Together AI.
@togethercompute’s inference platform is an ideal demonstration of @prlnet's value proposition — One of the world’s most advanced hyperscalers running AI workloads on Pearl’s 2-for-1 Cuda kernels, turning inference into ¶PRL coins, and reducing consumer LLM price per token. Excited for what we’ll build together.
Introducing Gemma-4-31B-it-Pearl on Together AI, Pearl Research Labs’ instruction-tuned checkpoint of Gemma 4 31B powered by @prlnet Proof of Useful Work protocol.
AI natives can now use this Pearl model as a serverless inference endpoint on Together AI, at a 25%+ discounted pricing.
Join us Tue 5/5: #DeepSeek-V4's hybrid attention + sparse MoE reduces KV cache up to 90%, enabling 1M-token context.
We'll cover why that makes it great for agentic workflows, what it took to serve at scale, and how to build with it. Hear from @realDanFu@JueWANG26088228@ZainHasan6 and @zhyncs42 → https://t.co/9mkBnymJoQ
If you're at #ICLR2026 and interested in Parcae - I'm giving a keynote (via Zoom) at the Latent and Implicit Thinking Workshop at 1:30 local time today!
@hayden_prairie will be at the workshop all day and presenting Parcae at the poster sessions - stop by!
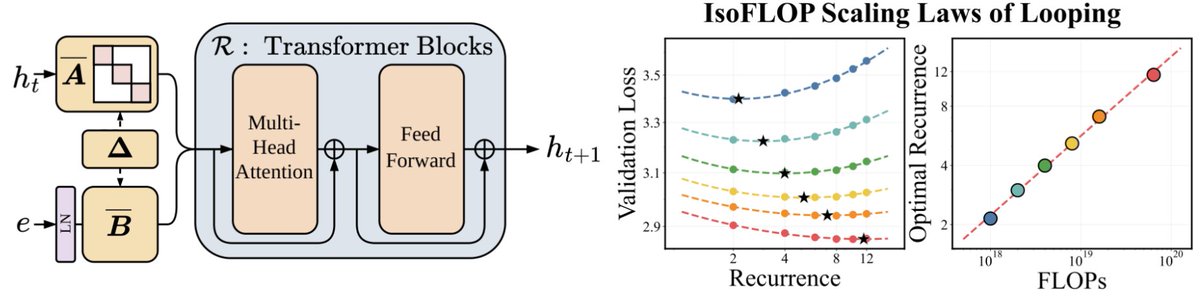
We’ve been thinking a lot about scaling laws, wondering if there is a more effective way to scale FLOPs without increasing parameters.
Turns out the answer is YES – by looping blocks of layers during training. We find that predictable scaling laws exist for layer looping, allowing us to use looping to achieve the quality of a Transformer twice the size.
Our scaling laws suggest that for a fixed parameter budget, data and looping should be increased in tandem!
🧵👇
Introducing DeepSeek V4 Pro, a long-context model with hybrid attention, three reasoning modes, and SOTA coding performance.
AI natives can now use DeepSeek V4 Pro on Together AI and benefit from reliable inference for long-horizon coding and agentic workflows.
Introducing DeepSeek V4 Pro, a long-context model with hybrid attention, three reasoning modes, and SOTA coding performance.
AI natives can now use DeepSeek V4 Pro on Together AI and benefit from reliable inference for long-horizon coding and agentic workflows.