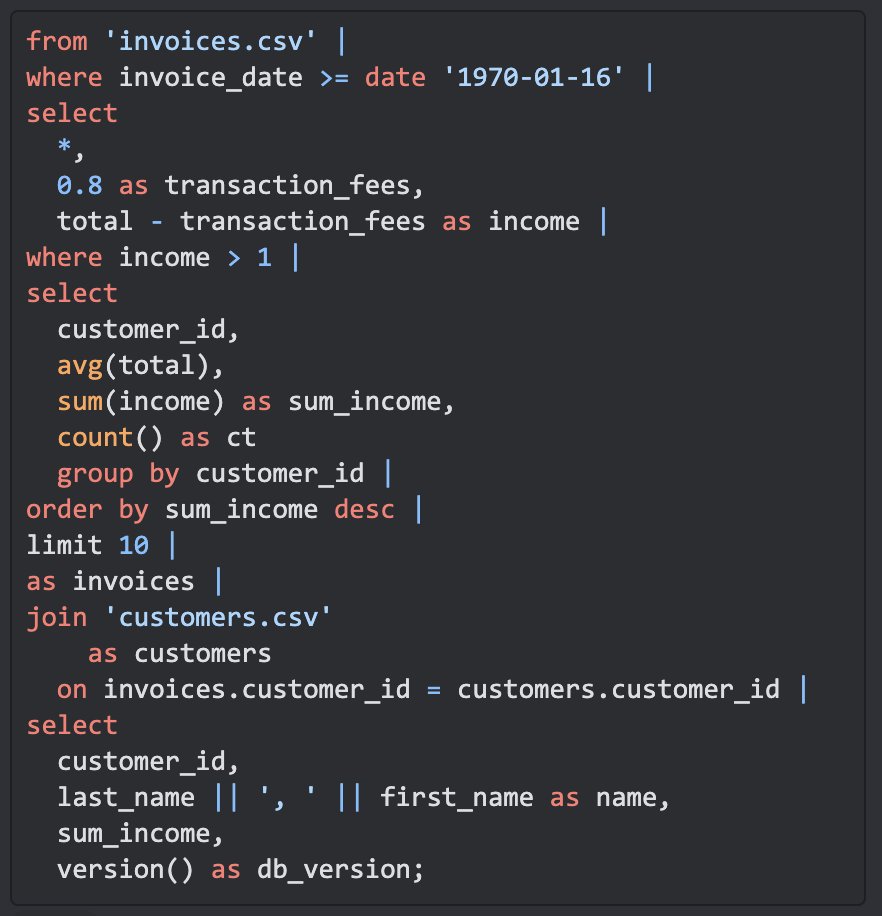
@cwi_da graduate & @duckdblabs CTO @mraasveldt gave a cool @duckdb lecture in @andy_pavlo's Advanced DB course: https://t.co/Lky7OY31wl
Details relevant @motherduck e.g.,: pluggable catalog+storage, WASM + (min44) pausable pipelines (for hybrid execution between cloud & local)
Elasticsearch and Lucene often take inspiration from academic work. This post shares strategies for implementing research papers, drawing on our experiences: https://t.co/iMkjyggQGo
Add icing to your data cake! Search petabytes of data stored on object stores like S3 within minutes using the frozen tier, now generally available. Learn more → https://t.co/K77HboQ7cs
The new frozen data tier decouples compute from storage, making it easier and cheaper to manage data at scale. Learn how search performance on the new frozen tier stacks up against other data tiers: https://t.co/A8VToSDXJh
You never outgrow good data. Make object stores like Amazon S3 fully searchable with the new frozen tier in Elasticsearch 7.12 → https://t.co/7dQjfcUyU1
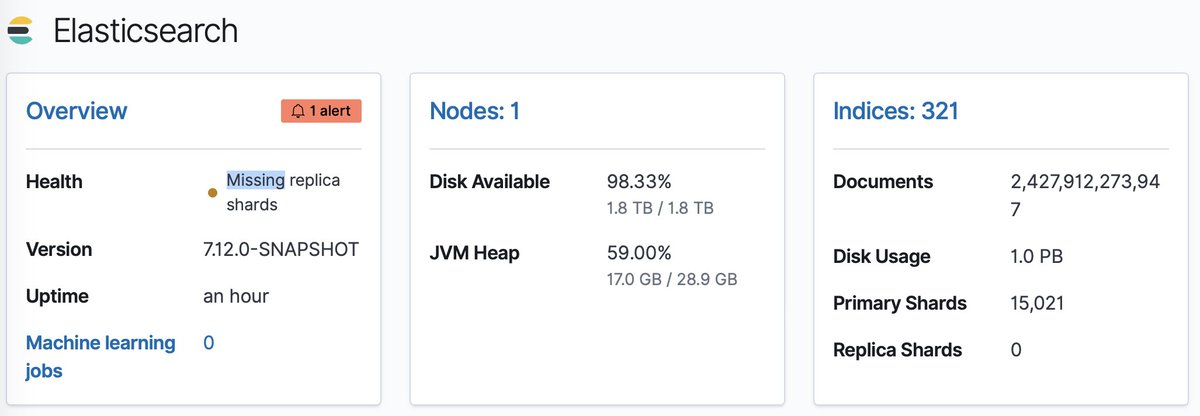
How about querying a petabyte-scale data set on S3 using a single #Elasticsearch node? The upcoming experimental release of searchable snapshots for the frozen tier in #Elasticsearch 7.12 has you covered → https://t.co/HlqLOD0uGH
+ https://t.co/ISOYjaOFLn
Since version 7.0, Elasticsearch successively moved points, stored fields and terms off-heap. Memory usage for segments will be 7x smaller with Elasticsearch 7.7 than it was in 7.0 with the geonames dataset. https://t.co/5dIBbABlIa
After 20 years, Apache #Lucene is still an important #opensource project with a thriving community. Take a look at some of the highlights of 2019 – including new committers, new PMC members, new features, and new improvements → https://t.co/PPjmpFA3RY
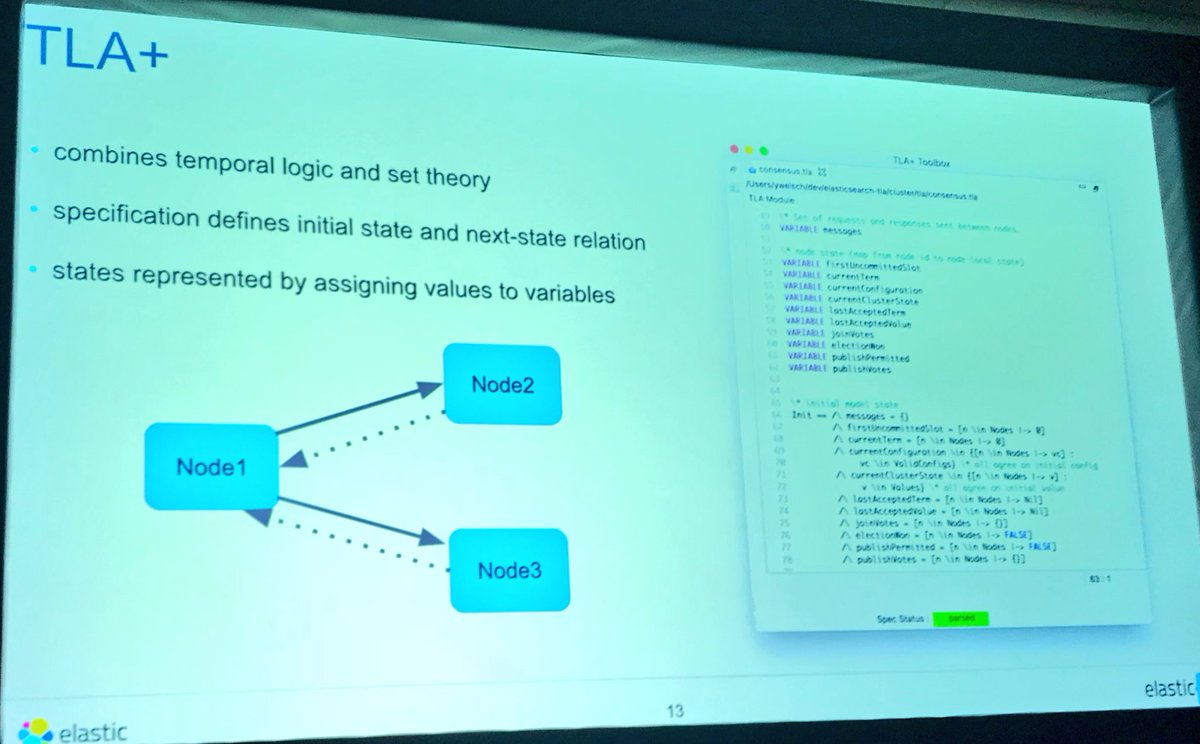
#tlaplus conf 2019: "Using TLA+ for fun and profit in the development of Elasticsearch" by @ywelsch https://t.co/Who9MlRbdP https://t.co/exnt6qy6eb
/cc @strangeloop_stl