We partnered with @FireworksAI_HQ to train open-source models for legal. Here's what we found:
1) Hybrid legal agents can beat frontier models on quality and cost by routing selectively to a frontier advisor.
We tested a hybrid setup where GLM 5.1 served as the primary worker, routing tasks to Opus 4.7 as an advisor when needed.
GLM invoked Opus sparingly, just 0.83 times per task on average.
The hybrid setup beat Opus on both quality and cost: 18% all-pass vs 14%, at $368 vs $954 across the same 100 tasks.
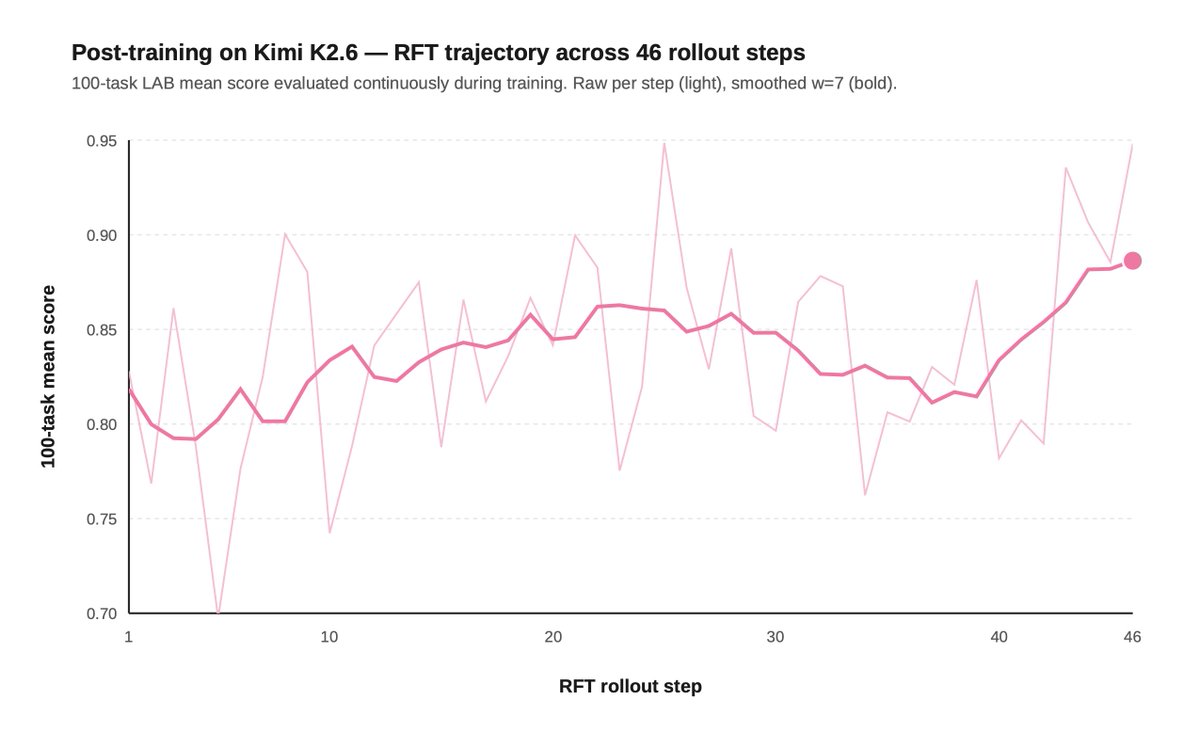
2) Post-training can push open models to frontier-level legal performance.
On a 100-task slice of our Legal Agent Benchmark (LAB), SFT moved Kimi 2.6's all-pass rate from 11% to 15%, beating Opus' 14%.
But the cost gap was even more striking: $84 vs $954 across the same 100 tasks, or ~11x cheaper.
We're excited to continue working with @FireworksAI_HQ on the next generation of open-source legal agents.
GLM-5.1 from @Zai_org is now live on OrcaRouter
• #1 open-source model on SWE-Bench Pro
• Beats closed source models on real-world repo repair benchmarks
• MIT licensed
• 200K context
• Built for long-horizon agentic coding
We’ve also seen strong results using GLM-5.1 inside OrcaRouter’s adaptive routing strategy as a fallback coding model.
Open-source coding models are getting scary good. https://t.co/a0WruoaJSc
We built TERMS-Bench, a three-tier benchmark for LLM agents in real-world economic negotiation. No LLM-as-judge, no outcome rubrics: the environment itself is the verifier.
🏆Among frontier models, @AnthropicAI Claude Opus 4.6 #1, @Zai_org GLM 5.1 #2.
✨Surprisingly strong: @GoogleDeepMind@googlegemma Gemma 4 31B — best open-weight, holds up as negotiations get harder.
🔗 https://t.co/XajAyaZRct
BREAKING: The results are in for Slides Arena... @AnthropicAI and @Zai_org models continue to lead the way in soft-verifiable domains
1st: Opus 4.7 by @AnthropicAI
2nd: Opus 4.7 (Thinking) by @AnthropicAI
3rd: GLM 5.1 by @Zai_org
Huge congrats to @AnthropicAI and @Zai_org for establishing the SOTA for Agentic Slides
GLM models are now live on @tensorix_ai
We’re partnering to bring cost-efficient frontier AI models to developers, startups, and enterprises across Europe and beyond — and to back the Sovereign AI ecosystem with serious inference muscle.
Four GLM models are now available
• GLM-5.1 → SOTA open-source performance advancing long-horizon AI agents to new levels
• GLM-5 → New generation language base model
• GLM-5-Turbo → agent-ready, built for coding and agentic use cases
• GLM-5v-Turbo → multimodal reasoning across code, images, documents, and diagrams
Go build something cool.
Build with GLM on Tensorix: https://t.co/1izv1MJa2D
GLM-5V-Turbo Tech Report: Toward a Native Foundation Model for Multimodal Agents
This report summarizes the main improvements behind GLM-5V-Turbo across model design, multimodal training, reinforcement learning, toolchain expansion, and integration with agent frameworks. These developments lead to strong performance in multimodal coding, visual tool use, and framework-based agentic tasks.
https://t.co/5mCu2VHZlI
Technical highlights:
CogViT Vision Encoder
- Built with dual-teacher distillation: SigLIP2 for semantics, DINOv3 for texture. A two-stage recipe, masked modeling, then contrastive pretraining, with QK-Norm for attention stability at scale.
Multimodal Multi-Token Prediction (MMTP)
- Three ways to pass image tokens into the MTP head were compared. The chosen approach uses a shared <image> token, removing the need to propagate visual embeddings across pipeline stages and improving training stability.
Broad Training Across Perception, Reasoning, and Agent Capability
- Vision and language are fused from pre-training onward, with emphasis on multimodal code. Joint RL across 30+ task categories yields consistent gains with weaker cross-domain interference than SFT.
Multimodal RL at Scale
- Infrastructure rebuilt along four axes: unified task and reward abstraction, full-pipeline asynchrony, fine-grained memory management for vision modules, and topology-aware partitioning for variable-length visual inputs.
As models, contexts, and workloads grow, hidden assumptions in inference infrastructure can surface as output anomalies. Reliability requires more than throughput, latency, and availability. It also requires preserving the correctness of model state behind every generation.
Scaling laws push model capability forward. But whether that capability becomes reliable in production depends on how we handle Scaling Pain.
https://t.co/81QCQw941P
In our latest blog, we share how we debugged GLM-5 serving at scale: reproducing rare garbled outputs, repetition, and rare-character generation; tracing and eliminating KV Cache race conditions; fixing HiCache synchronization issues; and introducing LayerSplit for up to 132% throughput improvement.
We hope these lessons help the community avoid similar pitfalls and build more robust inference infrastructure.
After fixing correctness issues, we turned to the next bottleneck: Prefill throughput and GPU memory pressure in long-context Coding Agent serving.
To address this, we introduced LayerSplit, a layer-wise KV Cache storage scheme. Instead of duplicating all layers on every GPU, each GPU stores only a subset of layers. With communication overlapped by computation, LayerSplit improved throughput by up to 132%.