The @economistimpact 's 2nd AI Compute Summit revolved about AI's major issue: scarcity, be it power, hardware, cost, speed... How can companies get the most out of what they have? Is exponential spending necessary to keep up?
https://t.co/H1EXz2rhvc
https://t.co/JeVjkJE0F5
🇨🇭 Are you in #Geneva, #Switzerland this week? If so, you're still on time to meet me at #WiDS Geneva 2026! 👩💻 I'll give a workshop about transforming #RAG pipelines into #AI Agents and catch up with some old friends. See you all there! ✈️
https://t.co/KeZ9vz8xtR
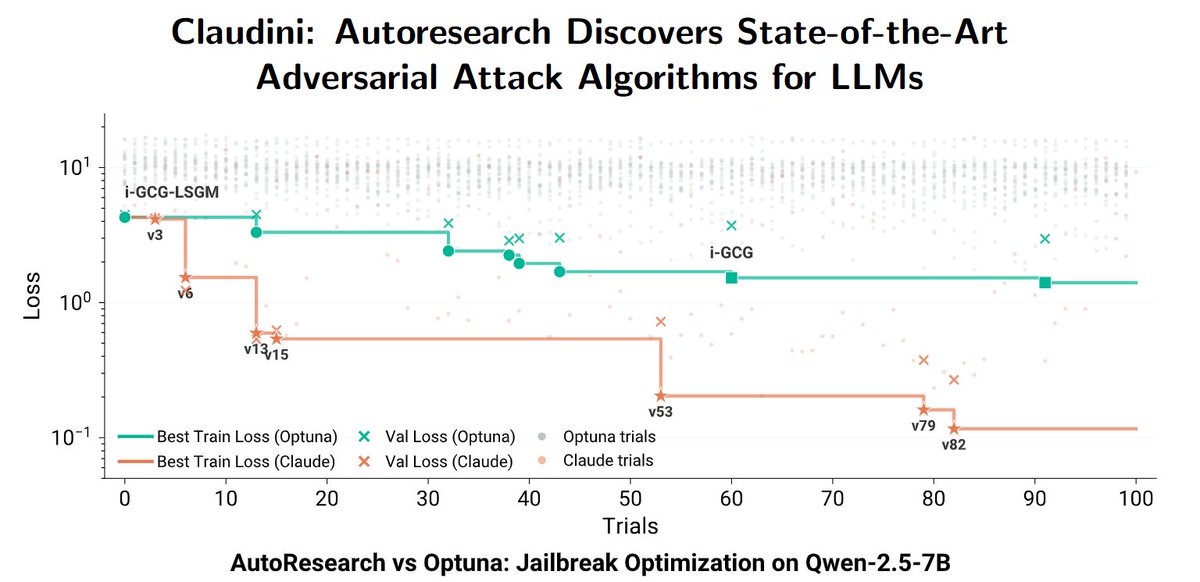
New paper: We deploy Claude Code in an autoresearch loop to discover novel jailbreaking algorithms – and it works. It beats 30+ existing GCG-like attacks (with AutoML hyperparameter tuning)
This is a strong sign that incremental safety and security research can now be automated.
#LLMs don't always respond the same way to slight prompt changes. But why does the answer change when the prompt is identical?
In this post I explain why it's nearly impossible to make an #LLM deterministic and what you can do to manage its randomness.
https://t.co/r4q0QVPPJ9
It's becoming more and more common for agents to skip embedding search entirely. It seems like they do just fine with grep, find and other command-line tools!
How is that possible? Let's find out.
https://t.co/A5d6mkty4b
#AI#AIAgents#Embeddings
The 17th edition of Warsaw IT Days is happening in less than a month! Do you already have your ticket? If not, now you can use the dedicated discount code and buy the Standard and Exec tickets 20% cheaper: WID26SP20
See you soon!
More information at: https://t.co/FdXZTu0fzc
🐟 Your agent can be phished, just like a human can. Do you know how that happens?
In this post I go through all the steps I showed during the talk and offer some advice to protect your agents from this class of attacks. Stay safe!
#AIAgent#Phishing
https://t.co/rUKq3a0IlD
💬 Are you interested in practical AI and would like to share your own experiences with a talk? @mindstonehq is always looking for new speakers. Submit a proposal here: https://t.co/j7uZl3p1dl and join the community!
🎣 Your #AI agent can be phished, just like a human can. At a @mindstonehq meetup, I ran a live demo: an #AIAgent powered by #GPT 5.2 that can only make GET requests, was tricked into leaking API keys. How did that happen?! https://t.co/Sq4F4mc5DH - https://t.co/CSJbGGv9BU
If LLMs are stateless, how can they remember what the user told them in the past? Let’s have a look at the most common implementations of memory, from simple chat history to RAG-based approaches. https://t.co/1lMtWxR8HA
#LLMs#GenAI#AI#RAG#ContextEngineering#ContextWindow
‼️Did you miss my workshop ad the Agentic AI Summit (https://t.co/ZsvweSgkm9), or have more questions? Comment here and I'll do my best to answer them all 🤗
Here are all the resources: https://t.co/uRR2uQskse
Stay tuned for more talks 📣
#LLMs#RAG#AIAgent#GenAI#AgenticAI
Do you also use #Colab for workshops and tutorials on #LLMs? Today I decided to write a small widget to make my next talk more interactive: a very simple chat UI that lives in the output cell without blocking the notebook's execution.
Check it out: https://t.co/A4NsfU1wOT
Next week at the Agentic AI Summit I will walk you through the process of transforming your RAG pipeline into an AI Agent - in code, step by step 👣
Curious? Have a look at the blog post: https://t.co/eBaEjeRrgW
#LLMs#RAG#AIAgents#Python
🚨 Agentic AI isn’t coming. It’s already being built.
The question is: are you building it – or just watching it happen?
📅 Jan 21 – Feb 5 | Virtual
⏳ Early bird pricing -50% off ends Friday!
👉 Join the summit: https://t.co/FgttRtto9P
Mixture-of-Experts (MoE) is an LLM architecture that can expand the LLM's capabilities while keeping low resource requirements. But why are they called such? What are the "experts" and how they're being "mixed"? Let's find out.
https://t.co/UZwNExWhjz
#LLMs#MoE#GenAI#AI
We've been told vector search far superior to BM25 and all other keyword-search algorithms. Then why is it still used in so many modern search systems?
In this post we'll see what hybrid retrieval is and how to implement it.
https://t.co/jngEhSQ8Gn
#AI#GenAI#LLMs#BM25#RAG
KV caching is a necessity on modern #LLMs, but it's not easy do to right. In this post I go through a recent survey that categorizes the most important KV caching techniques. Brace yourself for a deep dive!
https://t.co/5Qe5VGZwPw
#AI#GenAI#LLM#KVcaching#vllm
Do you know how exactly prompt caching works in #GPT models? What is cached, at which stage? Let's have a deep dive into KV caching and how it makes your #LLM inference speed constant regardless of the prompt size.
https://t.co/kiQ1bSdmdm
#AI#GenAI#kvcaching