Exploration is key for robots to generalize, especially in open-ended environments with vague goals and sparse rewards.
BUT, how do we go beyond random poking? Wouldn't it be great to have a robot that explores an environment just like a kid?
Introducing Imagine, Verify, Execute (IVE)!
IVE leverages Vision-Language models to
• extract semantic scene graphs,
• imagine novel scenes,
• predict their physical plausibility, and
• generate executable sequences.
IVE is a memory-guided agentic exploration framework that operates fully automatically, enabling more diverse and meaningful exploration.
@ICCVConference In "Camera-Ready Submission Instructions", it says "However, papers that are longer than 8 pages (not including references), will not be processed and will not appear in the conference proceedings or on IEEE Xplore." Does this "8 pages" also not include acknowledgment section?
Wild paper
They prove (!!) a transformer block (Attn + MLP) running on prompt
Outputs the same logits with no prompt
If MLP weights updated by vector:
W′ = W + ΔW
Calc from attn latent:
ΔW = (W·Δa) × (A(x)ᵀ / ‖A(x)‖²)
Given prompt:
Δa = A(C, x) − A(x)
Fucking fine tuning.
The use of AI in reviewing is a growing problem. Several of my ICCV papers have AI reviews -- one reviewer was so lazy that they left in the prompts!
A common refrain that I hear is that people have difficulty writing in English and need to use AI to clean up their review. Hogwash.
I took one of the reviews I wrote for ICCV and used Google Translate to translate it to German and then from German to Spanish, and back to English.
The original English review was rated as 99% human by an AI detector. After the multiple translations, this only dropped to 93% human.
So, if English is a problem, write in whatever language you like and use AI to translate it. This should be the only use of AI allowed by the rules.
Or, better yet, submit your review in whatever language you feel most comfortable with and have OpenReview automatically translate into whatever language the author wants.
So let's get rid of this "grammar argument" for using AI. People are using AI in reviewing to cheat the system. I can submit my own paper to an AI for a review if I want. You've added no value if you do the same.
What I want from a reviewer is their unique insight. If they don't understand my paper, that's important information for me. They represent my human audience. If they struggle with my submission, so with other humans. As long as my paper is written for humans, I need feedback from humans.
How different are the outputs of various LLMs, and in what ways do they differ?
Turns out, very very different, up to the point that a text encoding classifier could tell the source LLM with 97% accuracy.
This is classifying text generated by LLMs, between ChatGPT, Claude, Grok, Gemini, and DeepSeek.
Many PhD students ask me what to work on given academia’s compute constraints. 🤔🤔🤔
My answer: Focus on questions only fundamental research can solve.
Some ideas to share with everyone:
→ Why and how did LLMs have the reasoning capabilities? (Theory gaps ≠ scaling)
1/n
We are announcing Open Thoughts, our large-scale open-source effort to curate the best open reasoning datasets!
DeepSeek-R1 is amazing but we still don't have access to high-quality open reasoning datasets. These datasets are crucial if you want to build your reasoning models!
Bespoke Labs released a 17k reasoning dataset last Wednesday, and the reception has been phenomenal (it's trending on HF).
So we are joining forces with the Datacomp community to launch Open Thoughts --- an open data, open model, and open code initiative for creating the best open reasoning datasets and the associated models.
Along with this, we release OpenThoughts-114k reasoning dataset and the associated OpenThinker-7B model.
Links to the code, model, and data are below in 🧵.
Stanford CS234: Reinforcement Learning
These lectures look like a nice introduction to reinforcement learning (RL).
After the impact of RL in recent models like DeepSeek-R1 and o1, it's worth learning about RL today.
Foundations of LLMs
This amazing new LLM book just dropped on arXiv.
200+ pages!
It covers areas such as pre-training, prompting, and alignment methods.
It looks like a great intro to LLMs for devs and researchers.
.@ilyasut full talk at neurips 2024 "pre-training as we know it will end" and what comes next is superintelligence: agentic, reasons, understands and is self aware
The world doesn’t live on a pixel grid and neither should vision models!
Excited to share Moving off-the-Grid (MooG): a video model w/o grid-based representations. MooG learns detached “off-the-grid tokens” that bind to (and track) scene elements as camera & content move.
🧵
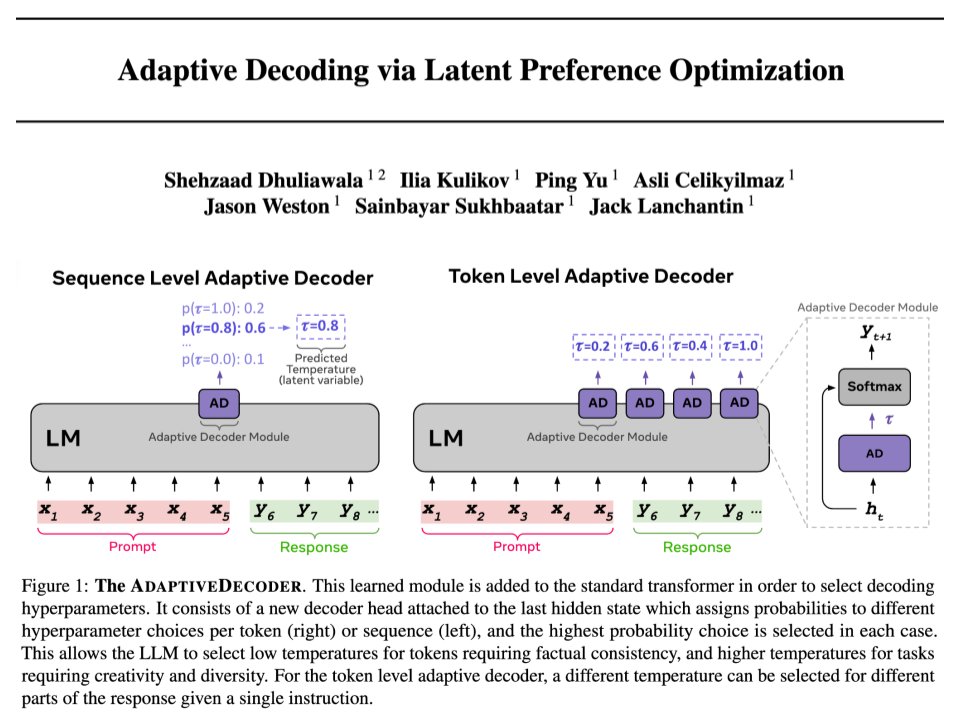
Excited to share work from my internship at @AIatMeta!
LLM devs often tweak decoding temperature: low for analytical tasks, and high for creative ones.
Why not learn this from the data?
Introducing the AdaptiveDecoder! (1/3)🧵
Had a fun time delivering language agent tutorial (https://t.co/UlDj9S4BfC) with @ysu_nlp@Diyi_Yang@taoyds@emnlpmeeting !
Thanks for joining and asking good qs!
😄I did a brief intro of RLHF algorithms for the reading group presentation of our lab. It was a good learning experience for me and I want to share the github repo here holds the slides as well as the list of interesting papers: https://t.co/YFiQfLAO1A
Would love to hear about the interesting papers that I missed🤔
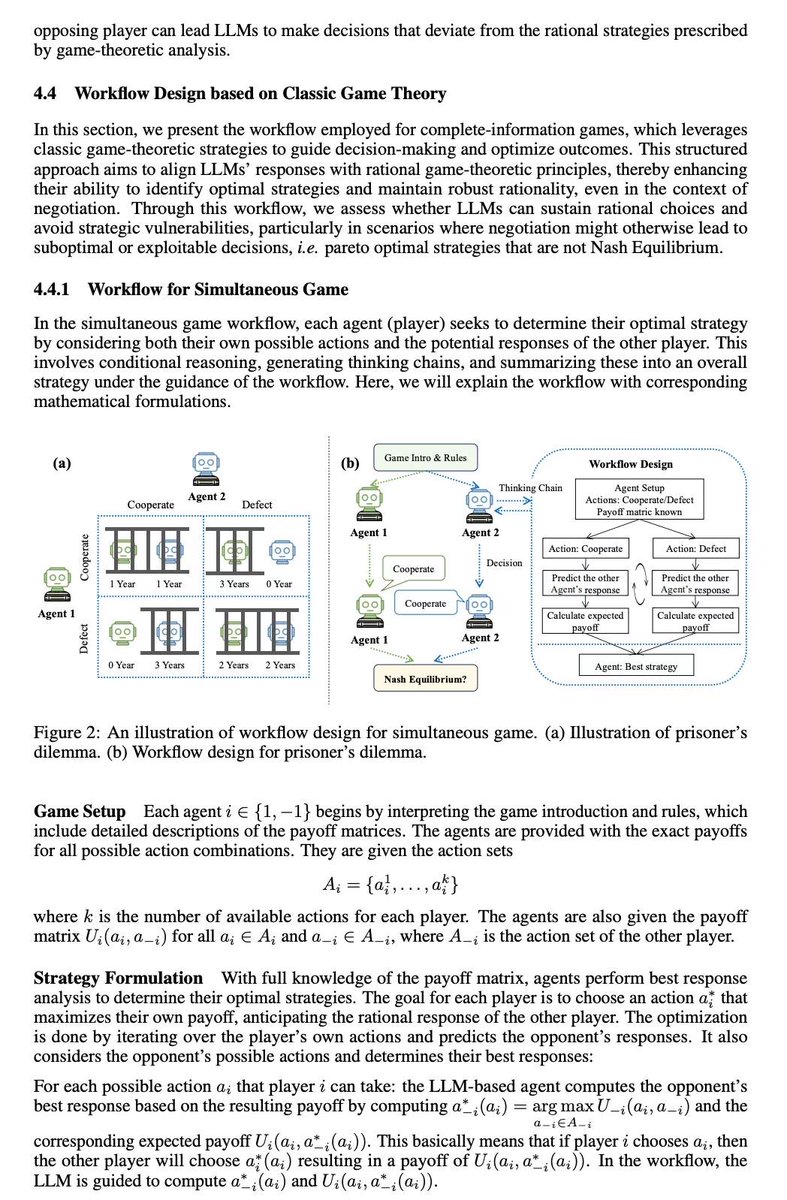
🌟🎲🎲How to create a rational LLM-based agent? using game-theoretic workflow!
Game-theoretic LLM: Agent Workflow for Negotiation Games 😊
paper link: https://t.co/atfdfU8LSB
github link: https://t.co/pTzXRJYBIj
😼 This paper aims at observing and enhancing the performance of agents in interactions guided by self-interest maximization
😼 😼 We chose game theory as the foundation, with rationality and Pareto optimality as the two basic evaluation metrics: whether an individual is rational and whether a globally optimal solution is developed based on individual rationality.
❣️ Complete information games
They are classic games such as Prisoner's Dilemma. We selected 5 simultaneous games and 5 sequential games. We found that, except for o1, other LLM generally lack a robust ability to compute Nash equilibria, meaning they are not very rational. They are not robust to noise, perturbations, or random talks among them.
Therefore, based on classical game theory methods (Iterative Elimination of Dominated Strategy & Backward Induction), we designed two workflows to guide large models step-by-step in computing Nash equilibria during inference time.
❣️ Incomplete information games
We used the classic "Deal or No Deal" resource allocation game with private valuation, where agents do not know the opponent's valuation of resources. Game theory does not provide a solution for this, and previous work has been based on reinforcement learning.
👉 Sonnet and o1 perform better than humans in terms of negotiation success rate and results
👉 Opus and 4o are far behind.
👉 We designed an algorithmic workflow based on the rational actor assumption, allowing agents to infer the opponent's valuation based on their reactions to various resource allocation schemes.
The workflow is very effective, reducing the possible estimated valuations from an initial 1000 possibilities to 2-3 within 5 rounds of dialogue, and always including the opponent's true valuation.
🌟🌟Based on the estimated valuation of opponent's resource, we guide the agents in each step to calculate and propose an allocation proposal that maximizes their own interests while having a non-zero probability of being envy-free, ensuring that both parties are relatively satisfied and the negotiation can proceed.
🌟🌟 But very interestingly, we found that if only one agent uses this workflow during negotiation, it will be exploited. Although the workflow improves the overall negotiation outcome and brings more benefits to the individual agent, the benefits will always be less than the opponent's.
🔥In the future, we will need a meta-strategy to choose which workflows to use!
After working at OpenAI for almost 7 years, I decide to leave. I learned so much and now I'm ready for a reset and something new.
Here is the note I just shared with the team. 🩵
I'm excited to share our new work, VistaDream, which generates a 3D Gaussian field from a single-view image. The codes have already been released.
Project page: https://t.co/pCY1HXQX7r (with interactive demos)
Code: https://t.co/W3hkaIHudB
Paper: https://t.co/yoq2xbCrJH
Google Deepmind trained a grandmaster-level transformer chess player that achieves 2895 ELO,
even on chess puzzles it has never seen before,
with zero planning,
by only predicting the next best move,
if a guy told you "llms don't work on unseen data", just walk away
A reminder that I made a template for ML research project pages!
It uses modern web dev technologies like Tailwind CSS and Astro, and it's easier to use than forking the Nerfies website. (1/4)