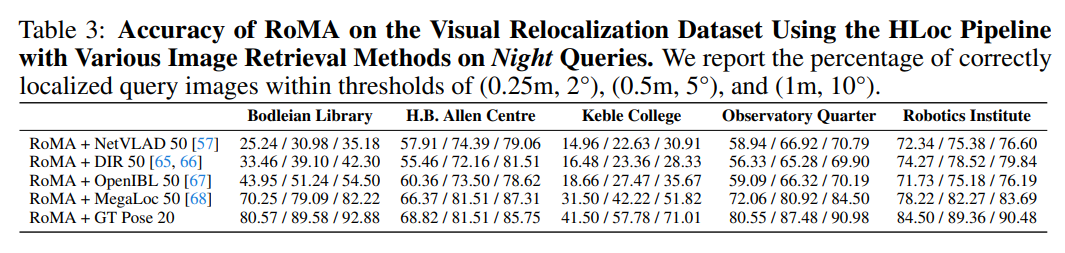
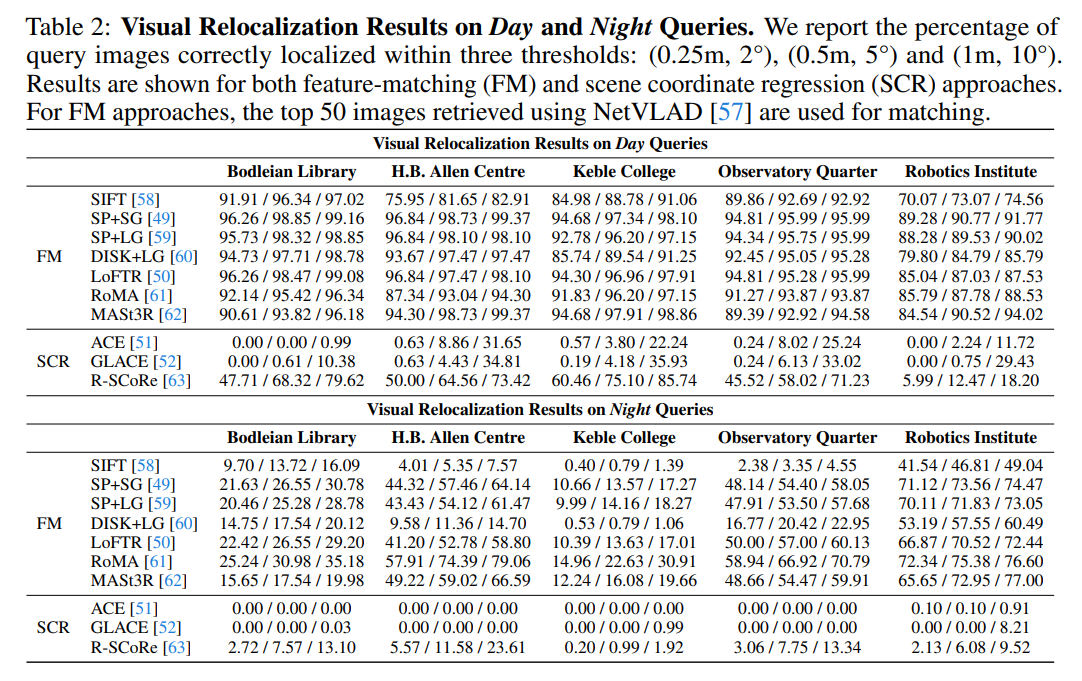
Excited to share that our Oxford Day-and-Night dataset has been accepted to the NeurIPS 2025 Dataset track! See you in San Diego!
📦 Dataset: https://t.co/FGOKTaKv5W
🌐 Project Page: https://t.co/VDbGYgKq5z
Seeing in the Dark: Benchmarking Egocentric 3D Vision with the Oxford Day-and-Night Dataset
@ziruiwang_, @wenjing_bian, @li_xinghui, @Yifu_Tao, Jianeng Wang, @MauriceFallon, Victor Adrian Prisacariu
tl;dr: egocentric dataset with GT 3D and lighting variation for benchmarking NVS and visual relocalization
https://t.co/jq2KGfVQlz
Just in time: the Best Paper Award in Robot Learning #ICRA2026 uses 3D camera pose to improve policy learning.
Pretty straightforward: robots live in a 3D world.
Image credit: @CSProfKGD
1/ 🧠Humans are the best robot data source!
2/ 👓Human egocentric video is rich in quantity, but poor in quality.
3/ Beyond scaling data, smarter representation and architecture matter just as much.
4/ Want an open-source framework to train your own learn-from-human-data robot policy?
🚀We introduce HumanEgo: Zero-Shot Robot Learning
from Minutes of Human Egocentric Videos⬇️
✦ Zero-Shot Human-to-Robot Transfer
✦ Robot-Data-Free
✦ Just 30 min of data per task
✦ Collect by Anyone, Anytime, Anywhere
✦ Deploy on Any Robot, Any Camera, Any Environment
✦ Open-Source & Easy-to-Implement
Let's squeeze every bit of signal out of human data!
🌐 Website: https://t.co/JfsW8x6wtq
📄 Paper: https://t.co/tsaIiatmNi
💻 Code: https://t.co/jZjghCcjh2
📹 Video: https://t.co/QWmJmQ9GgQ
🧵 1/n
Excited to share that our synthetic evaluation benchmark is now integrated into @Voxel51.
Huge thanks to Harpreet Sahota and the @Voxel51 team for making this happen!
Check it out 👉: https://t.co/NY4zzckZTt
📣📣 Introducing Reflect3r @3DVconf
✅ Single-view to 3D reconstruction by using mirror reflections as an auxiliary view
✅ A synthetic evaluation dataset containing 16 fully customizable Blender scenes.
This is a joint work with @ziruiwang_, Iro Laina, and @viprad
🌐 Project Page: https://t.co/9X66b0dIrH
📄 Paper: https://t.co/nk5NWyKOUv
👩💻 Code: https://t.co/Jv3JxE2aER
🤗 Huggingface: https://t.co/VEji2srAru
Introducing Particulate: a feed-forward model for 3D object articulation 💻✂️👓🧳
Particulate gives you a fully articulated 3D object, including part segmentation, kinematic structure & motion constraints, in a single forward pass in ~10secs.
🏅SOTA performance!
💡GenAI compatible: Turns AI-generated 3D meshes into fully articulated models!
Project page: https://t.co/8yYFpYdEkY
Code: https://t.co/CUuubxqbdY
@gabriberton Thanks, glad you enjoyed it! We were also impressed by how well MegaLoc handled those extreme lighting conditions the first time we saw it!
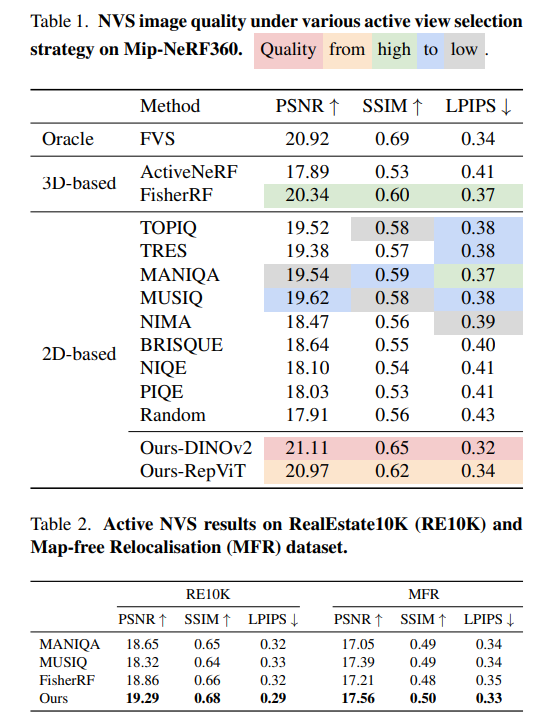
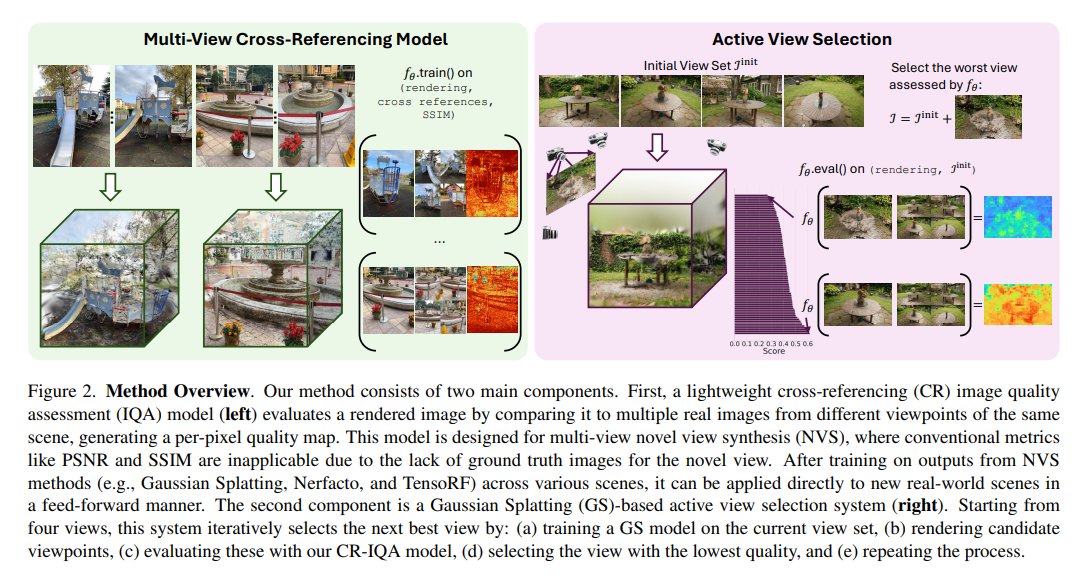
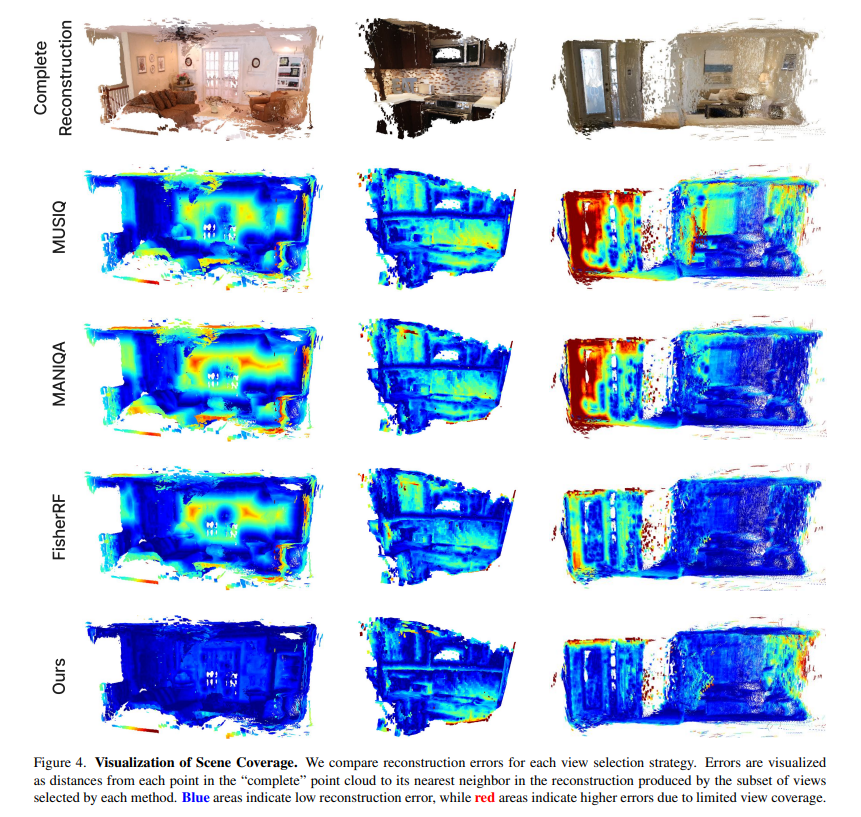
Active View Selector: Fast and Accurate Active View Selection with Cross Reference Image Quality Assessment
@ziruiwang_, @ysbhalgat, @RayLi234, @viprad
tl;dr: CrossScore helps active NVS
https://t.co/HXSZHVYtWd
Seeing in the Dark: Benchmarking Egocentric 3D Vision with the Oxford Day-and-Night Dataset
@ziruiwang_, @wenjing_bian, @li_xinghui, @Yifu_Tao, Jianeng Wang, @MauriceFallon, Victor Adrian Prisacariu
tl;dr: egocentric dataset with GT 3D and lighting variation for benchmarking NVS and visual relocalization
https://t.co/jq2KGfVQlz
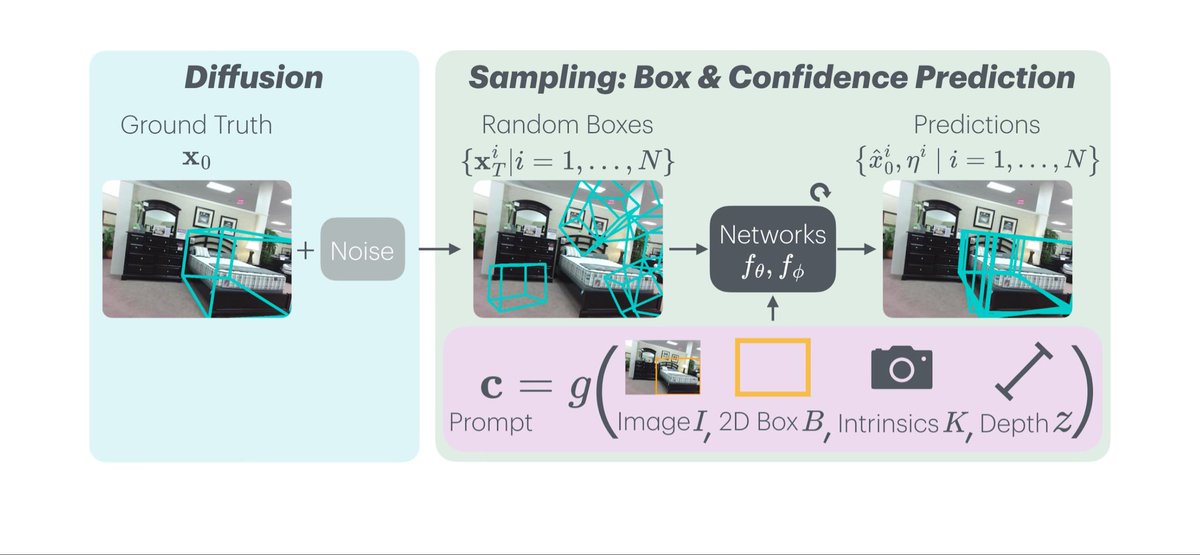
CatFree3D: Category-agnostic 3D Object Detection with Diffusion
TL;DR: A diffusion-based 3DOD pipeline boosting accuracy & generalization, plus a new evaluation metric
📄 https://t.co/GAkEhUGYPT
w/ @ziruiwang_, Andrea Vedaldi
Look forward to the oral presentation at #3DV2025
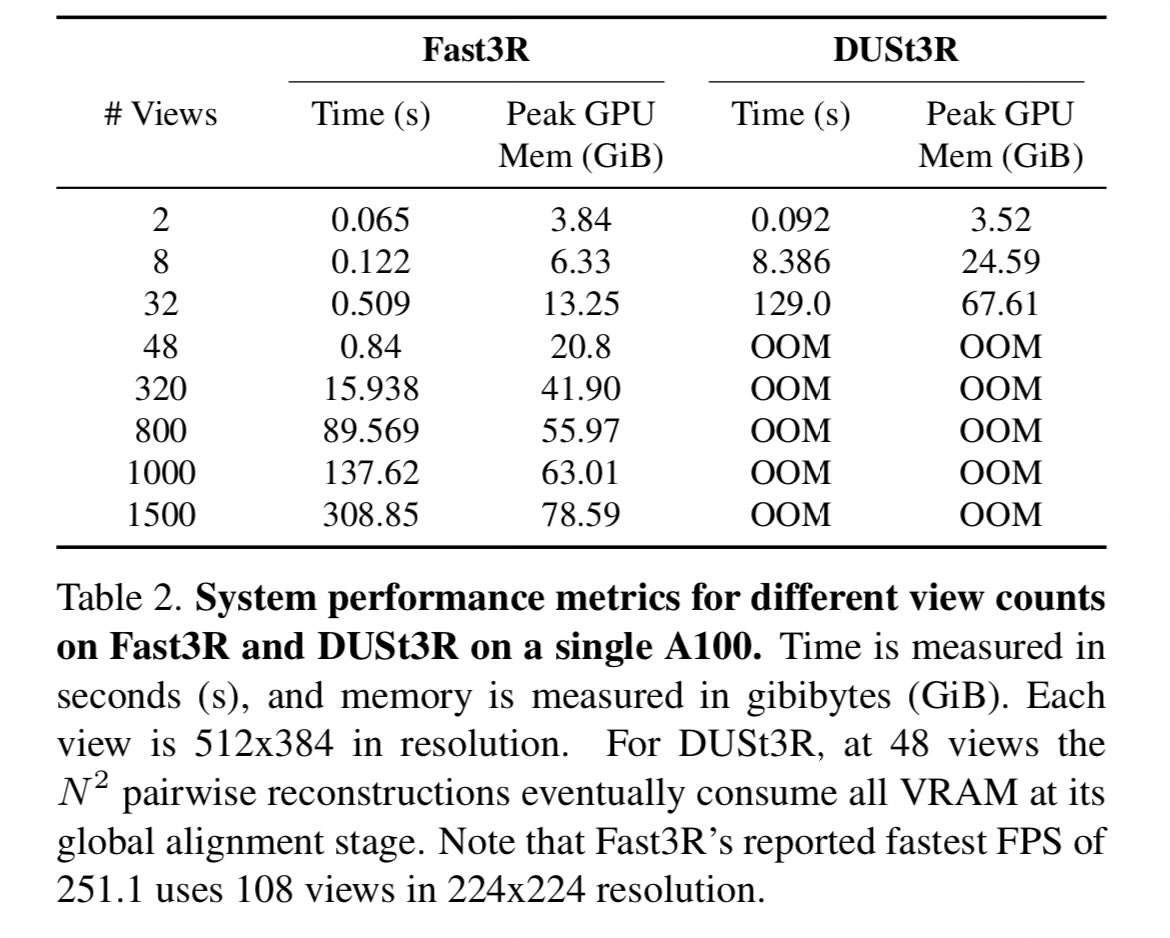
Just found a great paper Fast3R, processing 1000 images in Dust3R style in one go!
https://t.co/91Is4oP4so
Btw, training takes a week on 64 A100 😅 and inferencing 1500 images takes 5min on 1 A100
I'm excited that our paper got into ICLR 2025!
Great work done by @DavidLA05031686!
This is another great work on camera localisation from our group @AVLOxford (other works are mostly from @ShuaiC8 and @wenjing_bian)
📢 Paper accepted to #ICLR2025 🎉
"GSLoc: Efficient Camera Pose Refinement via 3D Gaussian Splatting"
TL;DR: a novel test-time camera pose refinement framework leveraging 3DGS as the scene representation and MASt3R for 2D matching.
🔗: https://t.co/zK99FUQhCy
Mitigating racial bias from LLMs is a lot easier than removing it from humans!
Can’t believe this happened at the best AI conference @NeurIPSConf
We have ethical reviews for authors, but missed it for invited speakers? 😡
I'm a PhD student at @UniofOxford and I think I'm living in a fairytale :-)
Foxes playing around in the snow at Magdalen College this morning — absolutely magical!
@Parskatt My hypothesis is that using CrossScore as a loss function requires it to be a smooth manifold, and with <400 scenes trained so far, I don’t believe the manifold is smooth enough for GD. We plan to work on it in future.
Thanks for sharing :)
TLDR: Introducing an image evaluation method that assesses rendered images via images from other viewpoints, eliminating the need for ground truth.
Primary use: assessing novel views in NVS tasks.
⛳️ https://t.co/y0QdBq1ngl
📄 https://t.co/yDBmW0fuqR