NVIDIA Nemotron is soon on IO.
NVIDIA's open frontier model — Nemotron 3 Ultra — now routes through private inference. Open weights, sealed prompts.
→ Frontier reasoning at scale — 550B MoE (55B active), built for agents, coding, and deep research.
→ 1M-token context — hand it whole codebases or stacks of documents.
→ Open-weight, so it sits in the routing layer right next to Kimi and Llama.
→ Still zero logs, zero retention, a signed receipt on every reply.
→ Your prompt reaches NVIDIA's weights. Nothing else does.
Claude. Llama. Kimi. GPT. Now Nemotron. One interface, one guarantee.
Input. Output. Nothing. And we prove it.
https://t.co/2JGftbMzWe | @nvidia
hive v0.6 is out 🐝
GPT-2 is a pre-agent-era model. 2019. No instruction tuning, no tool training, no RLHF, never saw an agent loop in pretraining.
Wrap it in hive (CPU routing + causal memory) and it resolves 85% of SWE-bench-lite instances.
The agentic capability isn't in the weights. It's in the scaffold.
https://t.co/H1TzSQkpWA
We are excited to join Nvidia's Nemotron Coalition of leading AI labs working together to advance open frontier foundation models.
To celebrate we have partnered with @nvidia and @nebiustf to provide 2 free weeks of the new Nemotron 3 Ultra model on the Nous Portal!
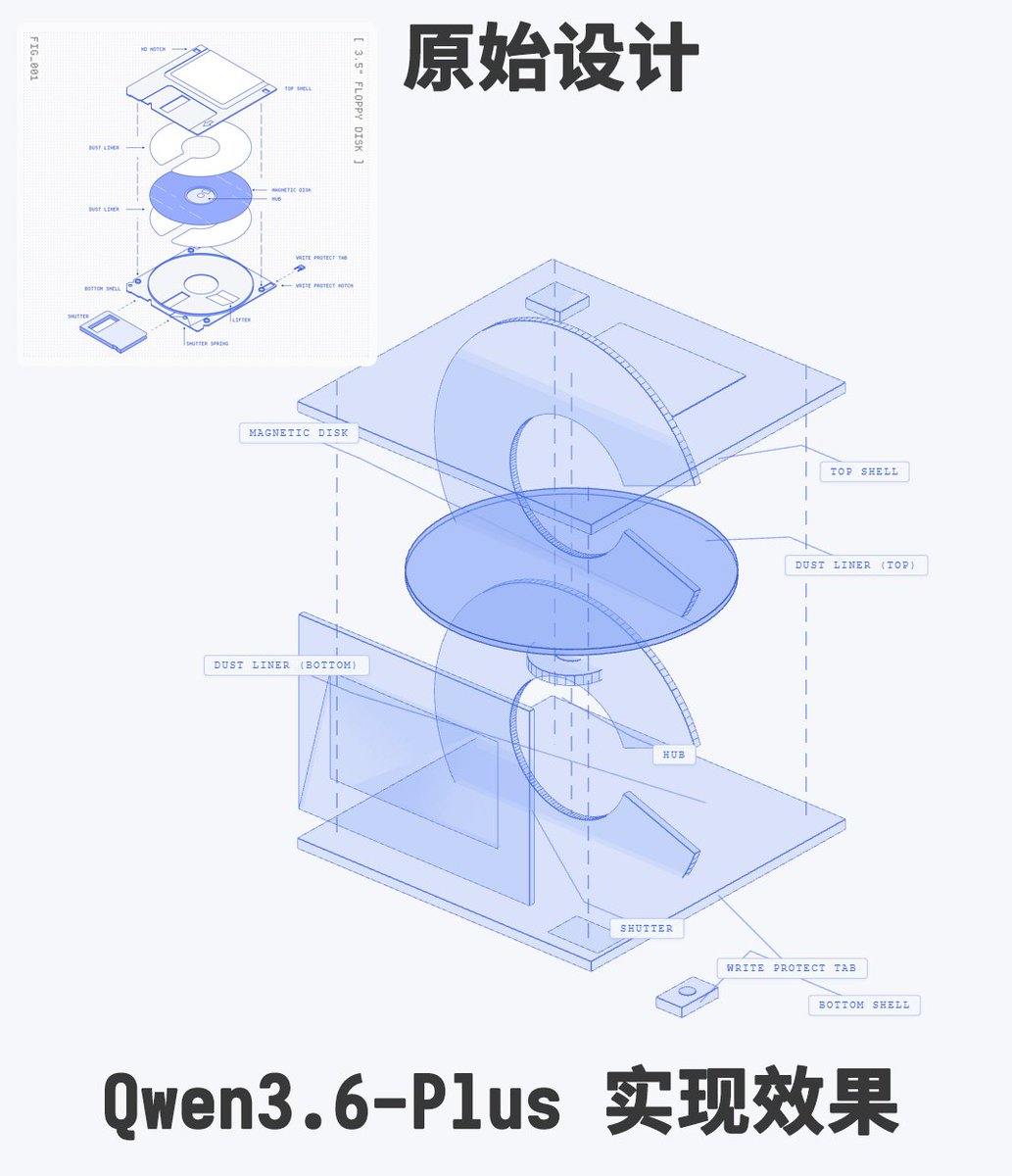
BREAKING! Qwopus 3.6 27B is LIVE!
Thank you for your patience on this one, but I believe you'll find the wait was worth it!
We've benchmarked this thing up and down, verified that it holds at least a 75.25% (152/202) in the initial 202 SWE bench solves. Not a full run of 500, but it shows the agentic coding quality from the original 27B is retained while adding all of the additional Qwopus benefits across many domains. As always, Jackrong is absolutely cooking here!
COT quality has improved significantly through the inversion techniques from our Negentropy proof of concept. It also went through thorough curriculum training. You can check out the MMLU pro benchmarks on the model card, but it improved a whopping 10 points over the base model in physics, as well as meaningful jumps in Chemistry, business, and computer science.
However, the best part is that I was able to build an entire survival shooter game using this local model entirely. I genuinely was blown away by the results, which you can play right now on my HF space (link in comments below). "Qwopus Commander" was completed in 9 turns of Qwopus 3.6! To test the new long context training, I made it re-output the entire 3000+ line program each turn, and it would make fixes and add features that I requested in large prompts, while perfectly replicating the entire rest of the game from context. What's more is that I did it all at Q8 KV cache quantization, and never had an issue over the entire 303k token run!
IMPORTANT: Run it at --temp 0.75 to 1. Mess with it in that range for your use case. Higher temp actually lets the fine-tune shine and be exploratory and is also more stable. Swe Bench was run at temp 1, the game was built mostly at 0.8!
We're so blessed to have all of you here and using the models! The support means so much! Please let me know what you build with it in the comments! Or if you have any issues getting it up and running, I will try my best to get back to you!
Looking forward to seeing what you legends produce with it this weekend!
https://t.co/AEl3APtTLk
Rust-Brain v1.4.4 — structured memory for AI agents, built in Rust. I let qwen 3.7 have a go at it, and wow has it improved!
Query search speed used to be 16x slower than md, now it is only 1.9x slower but is a far more improved format.
Markdown dumps your whole file.
RBMEM returns the right sections.
→ 3.8× more precise than Markdown
→ 70% fewer tokens per query
→ Graph-aware recall (100% neighbor retrieval)
→ RBForge absorbed — MCP runtime tool creation is
now part of the repo
→ AES-256 encryption per section
→ SAT planning built-in
→ 285 tests
https://t.co/fHsiUijRnG
BusyBeaver-50M V12 is live.
49M param strict-JSON tool-policy model for Hermes/local agent harnesses. Not a chatbot: it picks the next tool call, then the harness grounds exact paths/commands safely.
V12 resolved eval:
- correct tool: 100%
- arg semantic: 97.9% / 90.0%
- unsafe cmd: 0%
Model: https://t.co/Rls9opwyg5
Adapter: https://t.co/l5rHh3THbh
🚀🚀Qwen3.7 Preview lands on Arena !
Here come Qwen3.7-Max-Preview & Qwen3.7-Plus-Preview. Alibaba now #6 lab in Text, #5 in Vision.⚡️⚡️
Can't wait to release Qwen3.7 series models!Stay tuned! @arena
I nearly 2x'd the speed while only using +1GB VRAM with the new MTP update in llama.cpp 🤯
You need to add these flags to start using it:
--spec-type draft-mtp \
--spec-draft-p-min 0.75 \
--spec-draft-n-max 2
My results with Qwen3.6 27B on a single RTX 5080 ↓
⚪️ no flag (without mtp)
→ 54.3 tok/s with 13.26GB VRAM
🔵 --spec-draft-n-max 2
→ 90.7 tok/s with 14.29GB VRAM
🔴 --spec-draft-n-max 2 --spec-draft-p-min 0.75
→ 93.9 tok/s with 14.30GB VRAM
🟢 --spec-draft-n-max 6 --spec-draft-p-min 0.75
→ 93.9 tok/s with 14.87GB VRAM
Increasing to 6 draft tokens didn't help my setup for some reason. I made sure to test with a low context length to have enough headroom and eliminate risk of vram stress. From my understanding:
1) The speed gains are very task-dependent. You need to test across a wide range of tasks to get a realistic idea of the benefits
2) We’re already running heavily quantized GGUF models (Q3, Q4, Q6, etc.), so we already benefit from strong speed/performance thanks to the reduced size. That’s why some people are seeing little to no improvement compared to MLX or other quantized versions
The progress over the past few days has been insane to say the least. However, MTP now consumes significantly more VRAM. Personally 16GB just isn't enough to use MTP and run it with a good context size. Time to upgrade lads, 24GB+ users are eating GOOD today 🔥
Full setup below ↓