Accelerating data science as eng director @NVIDIA RAPIDS.
Previously DL for self driving cars, medical imaging, health data, econometrics, and kernel hacking.
Your AI is bottlenecked by your data. Our Dell AI Data Platform: 12x faster vector indexing, 3x faster processing with Lightning FS (the fastest parallel file system in the world), feeding GPUs at 150 GB/s per rack. 🚀
https://t.co/bMkg0NSoZp
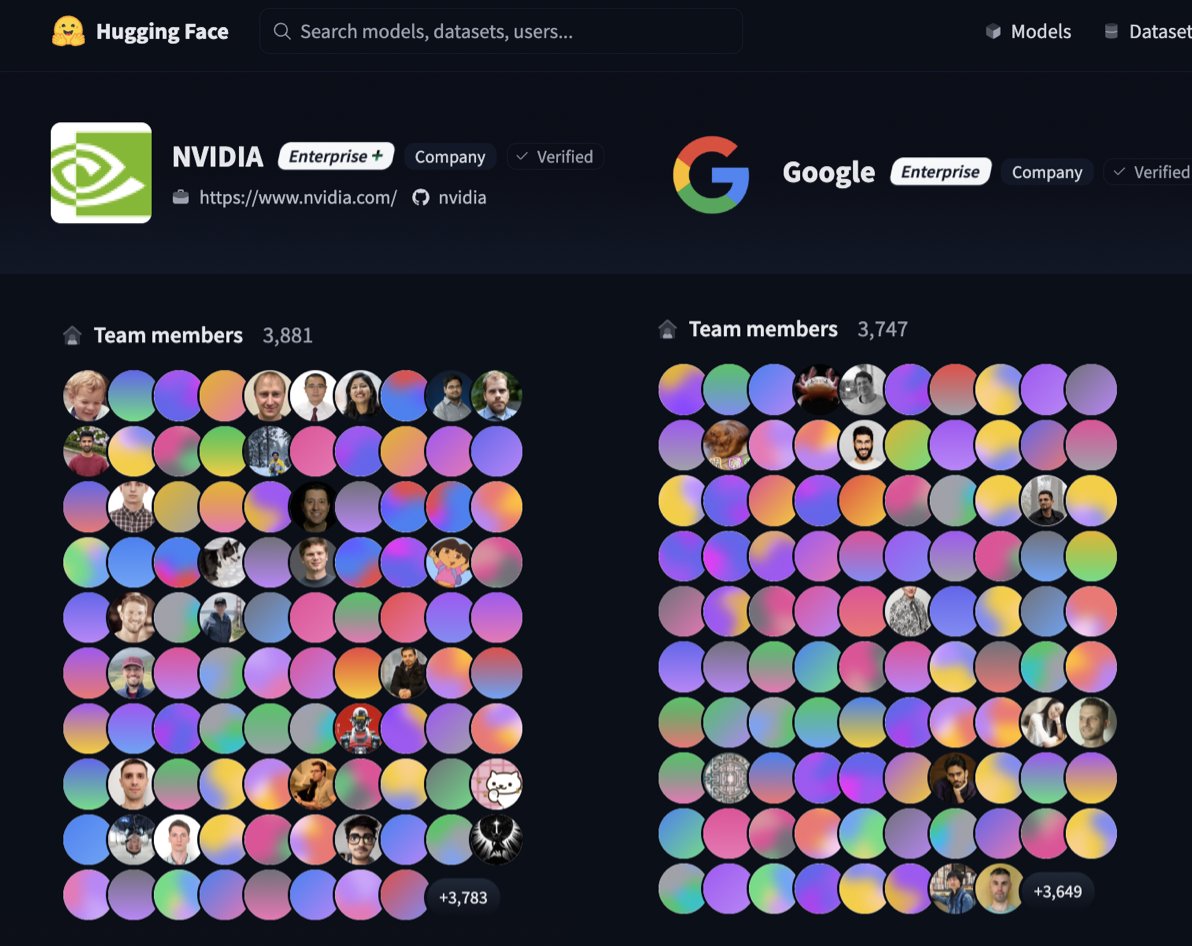
Nvidia just crossed Google as the biggest org on @huggingface with 3,881 team members on the hub.
I'm officially calling it:
Nvidia is the new American king of open-source AI!
Quoting Jensen: "All of these platforms are processing DataFrames. This is the ground truth of business. This is the ground truth of enterprise computing. Now we will have AI use structured data. And we are going to accelerate the living daylights out of it."
Polars DataFrames are at the core of the AI revolution.
https://t.co/bs8Jb18rCg
Truly awesome to see Jensen in his GTC keynote present @nvidia's joint partnership with @IBM to use cuDF to accelerate open source Velox and the Presto SQL engine in watsonx, showcasing how @Nestle achieves 5X faster queries for 83% less cost.
Amazing collaboration between the Nvidia and IBM teams to make this a reality, and we're just getting started.
Very proud to share that @JiweiLiu, @MJeblick , and @jackyu815 from my team just won DABStep benchmark with an agent that learns from the tasks it solves.
We'll share more details ASAP.
https://t.co/AJgaEI6YxC
NVIDIA #CUDA-X libraries are accelerating scientific breakthroughs with the power of #AI.
🧬 NVIDIA cuEquivariance takes protein structure analysis from months to minutes, and RAPIDS-singlecell lets researchers process massive volumes of genomics data in seconds.
🔋 NVIDIA ALCHEMI rapidly accelerates battery and OLED discoveries, turning years of lab work into days.
🌎 NVIDIA Earth-2 and NVIDIA PhysicsNeMo enable realistic weather forecasts in seconds, helping scientists predict disasters with AI-driven precision.
Watch here to learn more 👇
or on YouTube ➡️ https://t.co/T6PJoF57Vw
🎊 Congrats to our NVIDIA cuOpt team who just won the 2025 COIN-OR Cup 🏆, awarded for top #opensource achievements in decision optimization and operations research.
cuOpt runs LP, MIP, and VRP workloads on NVIDIA GPUs, delivering fast, scalable results with a robust open codebase.
Get started 🖥️ https://t.co/RjYwJVTysg
HUGE
> we have a new #1 on the
> MTEB Embedding Benchmark Leaderbord
llama-embed-nemotron-8b
> beats Gemini, Qwen3, Linq, GTE
> fits on ONE RTX 5090
> 4096 dims, 32k ctx
> 69.46 avg across tasks
> multilingual bi-encoder, zero-shot across retrieval, rerank, STS, classification
🔥 Join us at #SciPy2025 for our tutorial, "Scaling Clustering for Big Data: Leveraging RAPIDS cuML" with Allison Ding!
🚀 Come learn to implement, optimize, and scale clustering algorithms effectively unlocking faster, deeper insights in your machine learning workflows.
⚡cuML accelerations for ML workflows for scikit-learn, UMAP and HDBSCAN -- with zero code changes required. cuML is up to 60x faster for UMAP and up to 175x for HDBSCAN over traditional CPU-based implementations.
Read the intro to GPU-accelerated UMAP and HDBSCAN workflows: https://t.co/MsAoVkR7AG
🎉 Huge congrats to our NVIDIA team “NemoSkills” for winning the AIMO-2 Competition 🏆 on @Kaggle.
Their system solved 34 out of 50 problems in just 5 hours using 4 L4 GPUs. 🔢✨⏱️
https://t.co/LnhFOMscJl
How? A powerhouse squad—Christof Henkel, Darragh Hanley, Ivan Sorokin, Benedikt Schifferer, Igor Gitman, Shubham Toshniwal, and Ivan Moshkov—combined expertise in LLM training, data generation, and KGMON insights.
Their final test set performance even beat earlier public results, proving they don’t overfit.👏
More details on the final solution are coming soon.💡
@kagglingdieter, @gonedarragh, @igtmn, @shubhamtoshniw6, and @i_vainn
🎊 Llama Nemotron Ultra 253B is here 🎊
✅ 4x higher inference throughput over DeepSeek R1 671B
🏆Highest accuracy on reasoning benchmarks:
💎 GPQA-Diamond for advanced scientific reasoning
💎 AIME 2024/25 for complex math
💎 LiveCodeBench for code generation and completion
Try as #NVIDIANIM ➡️ https://t.co/bHVzfSbsZf
Technical deep dive ➡️ https://t.co/hsHmzJLig7
🚀 The Colab team collaborated closely with @nvidia to deliver day 1 compatibility for NVIDIA cuML's Zero Code Change ML Acceleration. Now, you can experience significant speedups in your machine learning workflows in Colab with no code modifications! Example notebook below 👇
https://t.co/xIskNY5RnF
👀 See how RAPIDS cuML 24.10 makes GPU-accelerated #UMAP even faster and scalable to larger-than-GPU-memory datasets, reducing runtime from hours to minutes on 150GB+ datasets.
➡️ https://t.co/T72fVLiPrX
Dive into the technical walkthrough to learn more.
Today, @pydatanyc kicked off with a tutorial on GPU Accelerated Python! @numba_jit, @CuPy_Team, and @RAPIDSai are all great ways to accelerate your code. Check out the full tutorial on the NVIDIA Accelerated Computing Hub to learn more: https://t.co/4FKCQ0kPdH
📣 Released into open beta: Polars GPU engine powered by RAPIDS cuDF.
It brings up to 13x acceleration to the fastest growing dataframe library with zero code changes required.
Read the announcement blog from NVIDIA #AIsummit ➡️ https://t.co/KWU0HWxp4E