Stoked about the release of the code for our work on scene flow, which was nominated for the best paper award at @CVPR 2025. Take a look, play with it, and let us know what you think!
https://t.co/kAzLjet08r
🎉 [CVPR 2025] ZeroMSF Code Release!
3D scene flow from a single camera, with no fine-tuning on new domains? That’s the challenge we tackled in Zero-MSF (Zero-shot Monocular Scene Flow).
💡 Motivation
Scene flow captures both geometry and motion, but existing methods crumble when moving beyond their training set. We asked: Can we build a foundation-style model that generalizes—out of the box—to any scene?
🔬 Our Answer
• Large-scale synthetic pre-training (1M+ dynamic samples)
• A unified geometry-motion parameterization
• Zero-shot inference on real-world videos—no extra training, just run it!
🤝 Huge Thanks
To my brilliant collaborators AbhishekBadki, HangSu, @0razio and my amazing advisor @jtompkin for making this possible.
👉 Dive In: https://t.co/Ib27sUdHHo
If you're at #CVPR2025 don't miss @YiqingLiang2's talk on our scene flow estimation work, which was also a CVPR Best Paper Award nominee!
Collaboration between @NVIDIAAI and @BrownUniversity
Heading to Nashville for @CVPR ! 🎸
I’ll be presenting the @nvidia internship project —
“Zero-Shot Monocular Scene Flow Estimation in the Wild” (Best Paper Candidate)
🗓 Sunday, June 15
🕘 Poster + Oral Presentation: Morning session
🔗 https://t.co/Ib27sUdHHo
#ComputerVision #SceneFlow #NVIDIAResearch #3DVision #CVPR2025
I'm very excited about this work led by @bowenwen_me, in which we show that high-quality synthetic data and architectural design choices that allow scalability can really push the envelope of stereo-based depth estimation.
Could #AI revolutionize stereo depth estimation?
Utilizing a massive dataset of stereo pairs, FoundationStereo is designed as a foundation model with strong zero-shot generalization and automatic self-curation pipeline.
Details from #NVIDIAResearch ➡️ https://t.co/6ENtbvuwQl
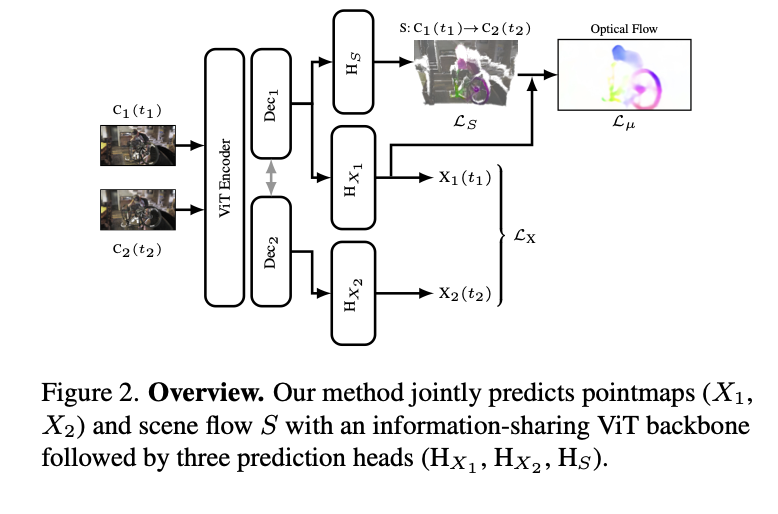
Zero-Shot Monocular Scene Flow Estimation in the Wild
@YiqingLiang2, Abhishek Badki, Hang Su, @jtompkin@0razio
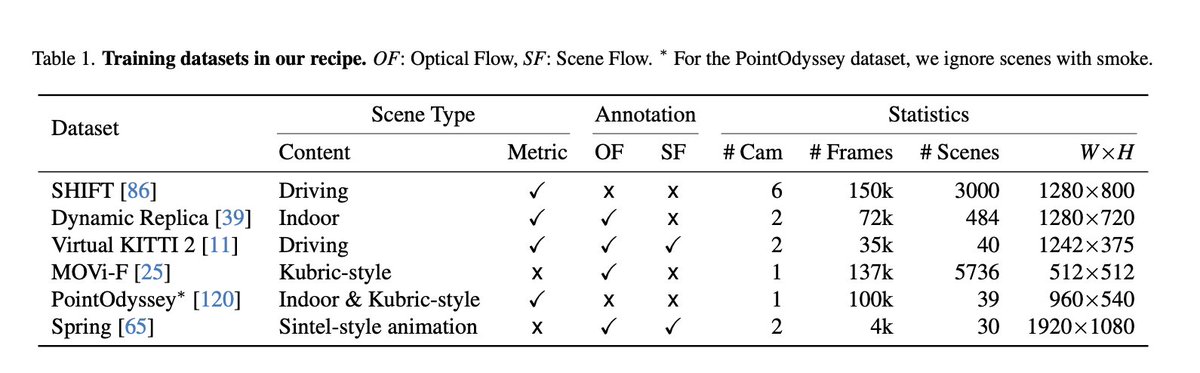
tl;dr: Dust3r predicting also a flow, but really - training recipe how to train on many scene flow datasets, especially w/o GT flow
https://t.co/srEuMJUTwp
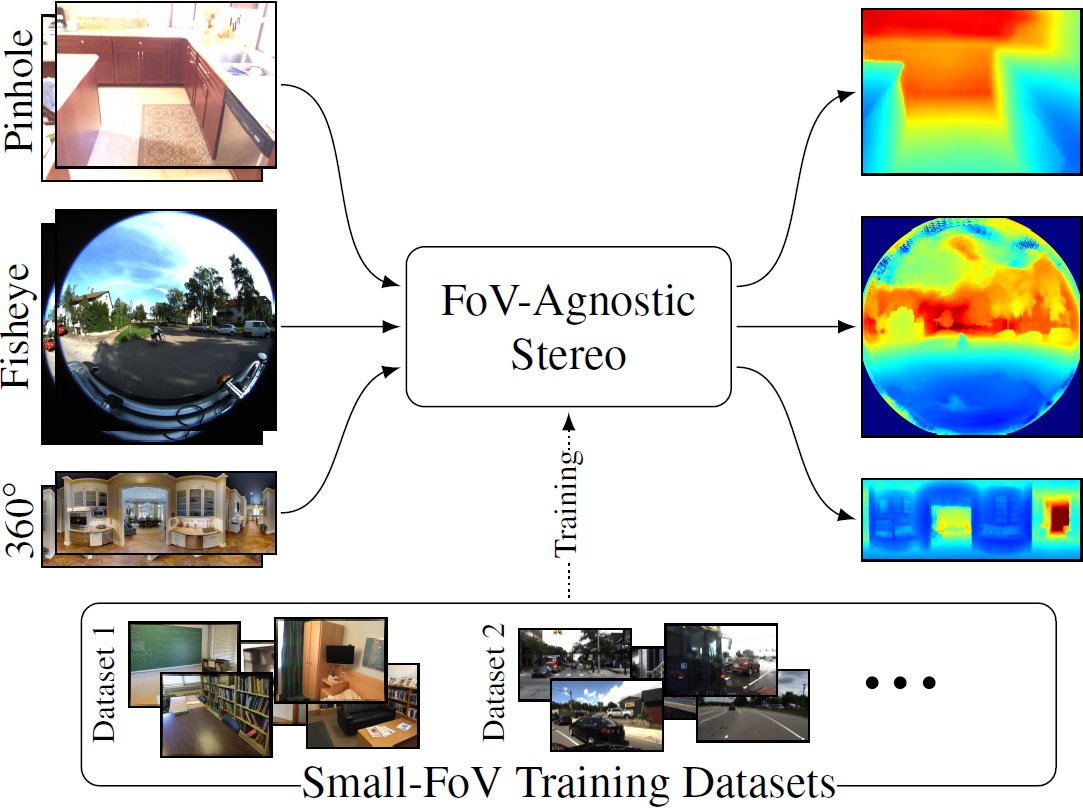
Proud of this project led by @daniel_lichy. FoVA-Depth is our answer to a problem we experience in many projects: for uncommon cameras, eg fisheye, we don't have as much training depth data as we do for pinhole cameras.
📢Doing 3D learning on datasets captured with different camera/image models, eg a mix of pinholes and fisheyes or ERPs?
With #nvTorchCam write the code once and forget about it, and you can even batch them all together!
https://t.co/Dz52Tf7T30
Let us know what you think!
🎉 Thrilled to introduce nvTorchCam, our new #PyTorch library designed to support the development of models using camera geometry like plane-sweep volumes (PSV) and related concepts like sphere-sweep volumes or epipolar attention, in a camera model-agnostic way! 🚀
🔗 Code: https://t.co/2z3xqJDDN9
(1/6)
I'll be at @3DVconf next week and I'm hiring! Flag me down if you'd like to join my team to do some cool research on low-level computer vision perception and/or image-based modeling/rendering at NVIDIA! But also, feel free to stop me to say hi :)
@IEEE_TCI is now posting spotlight talks for recently accepted papers on its YouTube channel!
No time to read the paper? Check out its spotlight!!
https://t.co/Bl0pTV4E6J
"Annealed Score-Based Diffusion Model for MR Motion Artifact Reduction" by @okt0711, @jung_sukyoung et al. from @kaist_ai and @cnuh01.
In a rush? No problem, here's a 5-minute talk on it:
https://t.co/L9dZPSwH5B
Or check out the paper:
https://t.co/fhWBBXGMEW
We have research #internships roles at @NVIDIAAI!!
Reach out if you're in a PhD program, and are interested in anything 3D (e.g., monocular/multi-view depth estimation, SLAM, SfM, etc.), anything optical/scene flow, anything novel view synthesis.
Utilize neural fields to generate authentic novel views from LiDAR. If you're at #ICCV2023, drop by to delve deeper.
📌 Poster: Friday, 10:30 AM, Paper 1719
🎙 Talk: Tuesday, 9 AM at the NeRF4ADR workshop
In about a week @SIGGRAPH, we will showcase an AI-Mediated 3D Video Conference system at Emerging Technologies, where you can talk to people in 3D using only a webcam + GenAI. It also features Live 3D Portrait and many more! Check it out https://t.co/UhUc234I9h
We are hiring a Ph.D. intern @ NVIDIA for research on multi-modal generative models, reinforcement learning, self-supervised representations, and 3D perception for video conferencing. If you have experience leading insightful contributions on any of these topics, DM / email me.
At NVIDIA Research, we are seeking research intern candidates who are interested in the topic of Large Language Models (LLM) compression: pruning, sparsity, architecture design, efficient training, and architecture search.
Please submit your CV here: https://t.co/Xd8TQk8DiM