I installed Claude Cowork yesterday
2 hours later it had produced:
- 14 job descriptions I'd been "getting to" since November
- Q1 marketing strategy doc (with budget allocations)
- 47 partner emails I'd been avoiding
- Website copy for 3 announcements we hadn't even scheduled yet
- A brand voice guide I promised the team 6 months ago
- Responses to 23 LinkedIn DMs from people I'd left on read
2 months of work. 2 hours.
I panicked and closed my laptop. Opened Slack to look busy. Realized there was nothing to do.
Took a walk. Got coffee. Reorganized my desk. Took another walk.
It's now 11am the next day and I'm writing this tweet because I genuinely don't know what my job is anymore.
My calendar is empty. My to-do list is empty. My inbox is empty.
I have a 1:1 with my manager at 2pm and I'm trying to figure out how to explain that I'm both more productive than ever and also completely useless.
Two key yet under-discussed numbers from #GPT-5 launch:
1) AIME (an eval on difficult math) has been *100%* solved.
2) GPT-5 has achieved 74.9% accuracy on SWE Bench Verified (an eval on real programming task)
I just ran a regression on the progress of AI accuracy in coding in the past two years and it shows that the improvement has been quite steady -- with the same pace programming will also be *100%* solved by Feburary 2026, which is aligning with the prediction at AI-2027 forecast (https://t.co/JsqD19O5So)
It has been believed that AGI will come shortly when coding is automated as AI companies can start to improve its models fully autonomous. It's also how @sama is quite certain the next time there's a new model it will come with new major scientific invention.
This is probably the last doubt by the public whether AGI is really coming.
Update:
I'm open-sourcing this.
My DMs have exploded with investors, pro players, teams, users. The demo has 5,000,000 views across platforms.
There is obviously interest.
But, I have zero interest in working on it. I'm more interested in working on Tidbit.
So -- someone please steal it and run.
There's a beautiful vision here, especially those who want to build in education.
Imagine an AI super-coach in your pocket:
- Do yoga, correct your form in real-time
- Practice guitar, fix finger positioning instantly
- Learn cooking, get real-time tips on spices.
- Learn painting, get brush stroke feedback.
The future of learning will look a lot like real-time, in the moment AI instruction -- it likely won't look like an AI homework helper.
Anyways.
There's a cool vision here for the right person to obsess over for 10+ years.
And the starting point is clear -- pick one thing (ex. basketball), be the best AI real-time coach in the world for it, keep growing.
GLHF :).
https://t.co/LTbjI84x9u
P.S: The repo is literally just a visualizer file + prompt. But hey, maybe it inspires someone.
+1 for "context engineering" over "prompt engineering".
People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step. Science because doing this right involves task descriptions and explanations, few shot examples, RAG, related (possibly multimodal) data, tools, state and history, compacting... Too little or of the wrong form and the LLM doesn't have the right context for optimal performance. Too much or too irrelevant and the LLM costs might go up and performance might come down. Doing this well is highly non-trivial. And art because of the guiding intuition around LLM psychology of people spirits.
On top of context engineering itself, an LLM app has to:
- break up problems just right into control flows
- pack the context windows just right
- dispatch calls to LLMs of the right kind and capability
- handle generation-verification UIUX flows
- a lot more - guardrails, security, evals, parallelism, prefetching, ...
So context engineering is just one small piece of an emerging thick layer of non-trivial software that coordinates individual LLM calls (and a lot more) into full LLM apps. The term "ChatGPT wrapper" is tired and really, really wrong.
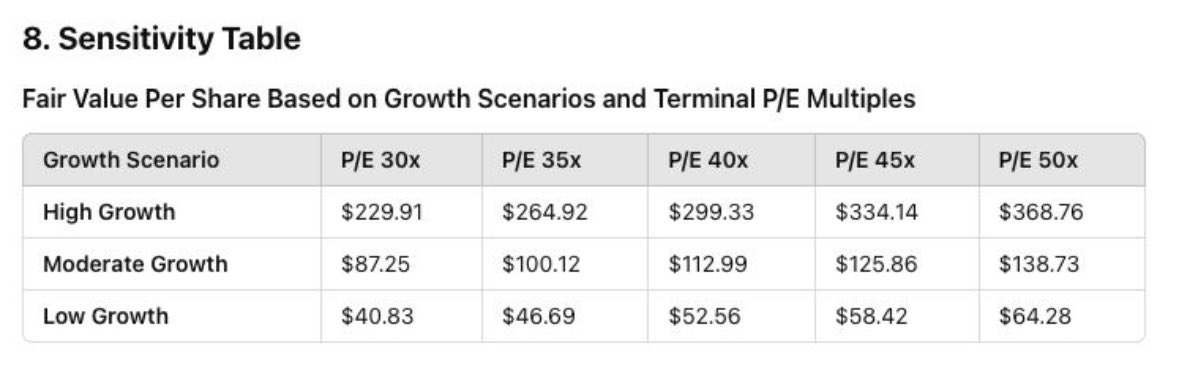
@BenjaminDEKR Built a sensitivity analysis on various rev growth and terminal P/E ratio assumption on discounted cash flow model to get $Nvidia’s fair mkt price. It takes a skilled ibanker a a few hours to build the model. o1 did it in 30s. 4o just completely hallucinated it
I tasked o1 with a sensitivity analysis on $NVIDIA's #DCF by varying rev growth and terminal P/E scenarios. Also, I requested o1 to forecast the #GPU market's future growth for rev projections. It's mindblowing 🤯
4. While I refrained from mentioning #VC above, I remain cautious about the dynamics of competition among AI-powered service vendors. However, given their low cost base, these businesses are likely to be profitable ventures. So considering it a small-business fund with reasonable multiples and trade-sale options, not a VC pursuing valuations and indefinite growth.
Prediction markets and Community Notes are becoming the two flagship social epistemic technologies of the 2020s.
Both truth-seeking and democratic, built around open public participation rather than pre-selected elites.
I want to see many more things like this.