i have seen enough proof now that using a coding agent is a deep skill
it's confusing because the people you see heavily using them produce horrible results
but that's because it's a skill! you can get better and the ceiling seems pretty high - this is very exciting to me
Opus 4.8 understands some really subtle nuances in UX and data modeling that makes it just plain lovely to work with.
Still have to keep reminding myself that this is the dumbest it's ever going to be.
Excited to share our SAO '26 workshop paper at ACM CAIS: "𝗪𝗵𝗲𝗻 𝗔𝗴𝗲𝗻𝘁𝘀 𝗢𝘂𝘁𝗴𝗿𝗼𝘄 𝗥𝗔𝗚: 𝗕𝘂𝗶𝗹𝗱𝗶𝗻𝗴 𝗣𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻 𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹 𝗦𝘆𝘀𝘁𝗲𝗺𝘀 𝗶𝗻 𝘁𝗵𝗲 𝗟𝗮𝗸𝗲𝗵𝗼𝘂𝘀𝗲" was accepted! These are some ideas @changhiskhan and I have been discussing at various talks, as well as observations from the Lance open source community in action. 👇🏽 🧵
1/4
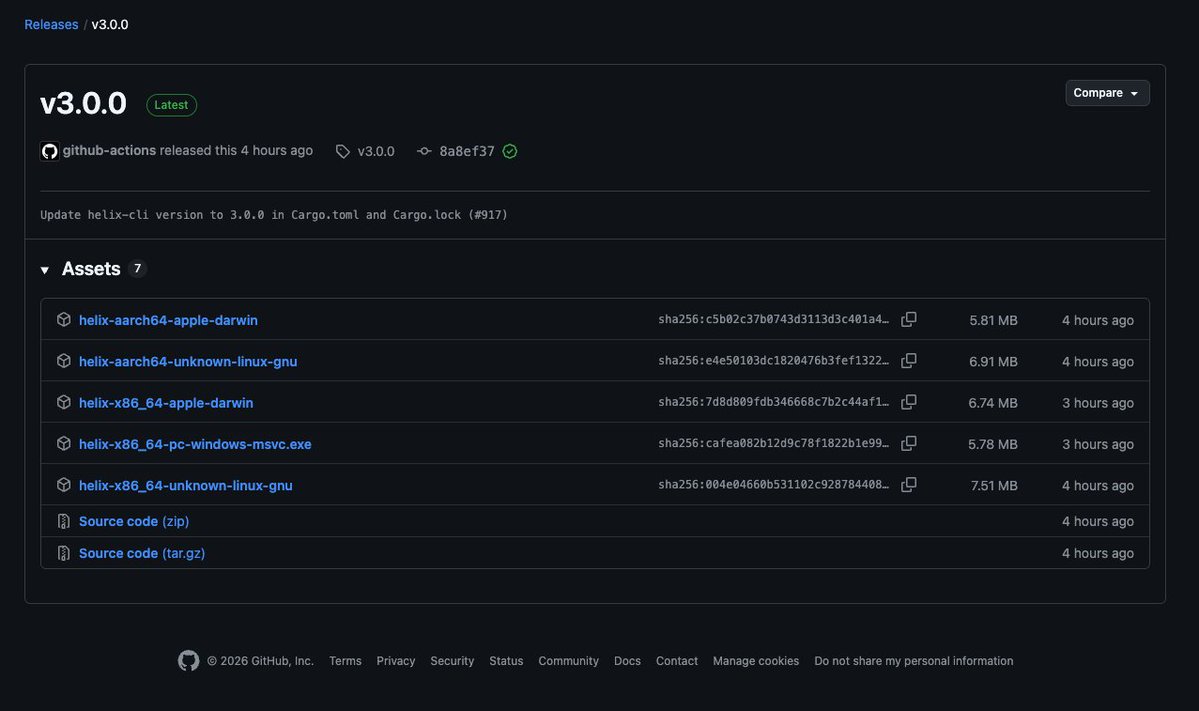
Hermes Agent v0.15.0 is out now!
747 PRs by 321 Contributors - thank you all for the work on this release!
Some Highlights:
- NFTY Platform added to gateway channels
- Skill Bundles and MCP Catalog
- Krea 2, Opus 4.8, Qwen 3.7 and more models supported
- Deep xAI Integrations
Huge performance optimizations and code cleanup:
- Load times 50% faster
- Session Search 750x faster
- No more godfile scripts
- Kanban redux
Security Updates:
- Bitwarden native integration
- Brainworm prompt injection defense
- Auto supply chain defense
And a whole lot more, check it all out below
I use SaaS
SaaS adds LLM chat
Agents use SaaS via MCP
Every SaaS ships native CLI ⬅️ We are here
💡SaaS is mostly a DB wrapper
DB CLI is better than SaaS CLI
Agents can do all the DB ops
I can vibe-code UI myself
I use database
@saranormous Problem is at some point it will become just a pile of md files. Agents start missing things and become confused.
nanograph can solve it:
https://t.co/rhTQGrBnsw
It's a light on-device graph db that syncs via github.
Code agents love it.
OSS, all data stored in lance files
shape of agent-native db is more clear now:
less: system of record
more: context assembly
models, memories, maps, reasoning structures
from "retrieve some data for LLM"
to "curate & maintain context state"
multi-paradigm, not just multimodal:
graph, columnar, documents, KV, objects, embeddings
not trying to suck every resource into
acts as an index & coordination surface for agents & existing systems
CONTEXT-AS-CODE
git-style: branch, version, merge
set of linted queries [lens]
ready for concurrent batch writes
ONTOLOGY-AS-CODE
declarative schema file
enforced, versioned, tracked
SECURITY-AS-CODE
single YAML policy file
enforced at the lens level
UI-AS-CODE
Jupyter-like notebook dashboards
living projection of the domain models
INFRA-AS-CODE:
lakehouse: compute & storage are separated
terraformed: S3 + elastic compute
FROM source of truth
TO source of competing views on what's useful now.
AI slop is good, actually. Slop is what enables fast parallel experimentation. The etiquette and skill is understanding the boundaries of where slop exists and the extent to which it should be cleaned up and how.
A few examples:
I’m working on the internals of some system right now. The API and GUI of this thing is fully zero shame slop. It’s horrible. But it lets me focus on the core quality while shipping a usable piece of alpha quality software to testers (transparent about the slop frontend).
Similarly, this system has plugins. We sent agents in Ralph loops overnight to generate dozens of plugins. The plugins are slop. The quality is bad. The plugin API/SDK is absolutely not done.
But we can test a full GUI with a full plugin ecosystem. When we change the API, we can regenerate them all. The cost of change is just tokens, the velocity is incomparable to before.
I built Terraform. We tested and shipped TF 0.1 with about 3 very weak providers. Because we ran out of time. Building was slow. And when we changed our SDK the cost was immense. Totally different today, 10 years later. Today, I would’ve slop generated 100 providers (again, with transparency and cleanup later, but just to prove it out).
As an anti example, I would not PR this (without prior warning) to another project. I would not throw this onto customers without full review or transparency (as I’m already doing). I would not accept first pass slop. It’s almost never right.
Slop is a tool. And like anything else it’s not blanket bad or good. The context is everything.
Fully migrated to @zeddotdev for code + docs
I used to switch between VSCode <> Cursor <> Obsidian
Now it’s just Zed
Minimal. Opinionated. OSS.
Tiny RAM footprint.
Rust-native UI render on Metal
beats Electron all the time.
One of those upgrades when you don’t look back.
Conjecture Institute Advisor @DavidDeutschOxf on some problems he'd like to see solved:
1. The theory of how to create an artificial intelligence (which will be far more illuminating than actually implementing the theory)
2. Progress in constructor theory (fundamental theory in physics that casts all laws of physics in terms of possible and impossible tasks)
3. Revival of optimism (apparent obstacles are just problems to be solved)
The problem is Signal vs Noise, not structure.
One way to solve it is to define clearly what constitutes the signal for you (this will be your contract with the agent).
You need to keep the definition up-to-date and versioned.
You can define it as a set of rules / patterns / anti-patterns.
Without those your knowledge base will turn into a pile of random noisy snippets real fast.
After you got the contract right - just use the database you like (via mcp or cli). Set up the schema and start collecting information.
In Claude Code you can create a skill and connect it to an end-session hook:
so agent could extract high-signal info from your sessions.
Also sessions dashboard tools are useful - give you observability so you wouldn't miss important things.
The next question is: how to keep your knowledge base up-to-date and hydrated.
You can solve it with another agentic workflow:
make agent go through your database and surface things that are conflicting, stale, or contradicting.
For this create another skill and run your agent with this skill on a cron schedule.
At some point you will get a bunch of policies for agent to resolve contradictions autonomously.
Next step - go into semantics and ontology.
You need those to give your agent not just knowledge, but reasoning pathways.
Full toolkit:
Database
Skills
Cron
If you give this post to your agent of choice - it will set up v0 for you right away
On-prem is the new cloud
@chamath called this 2 months ago.
Now it's everywhere:
On-prem - ideal
VPC - okay
SaaS / public cloud - 👎
The cost of setting up infra is decreasing fast.
Agents can configure anything in a matter of hours:
Firmware, LAN, VMs, k8s, Terraform - you name it.
Many companies are running open-source LLMs in-house for simple workflows.
And pseudonymize data for cloud models.
CFOs love it!
They hate everything that is per-seat or per-token.
Way more focus on what's defensible:
data
policies
ontology
know-hows
decision chains
New motto:
Data sovereignty
Zero vendor lock-in
Headless OSS stack
On-prem / hybrid infra
Centralized governance
Context graph ownership
Bearish on rent
Bullish on own















![1eo's tweet photo. shape of agent-native db is more clear now:
less: system of record
more: context assembly
models, memories, maps, reasoning structures
from "retrieve some data for LLM"
to "curate & maintain context state"
multi-paradigm, not just multimodal:
graph, columnar, documents, KV, objects, embeddings
not trying to suck every resource into
acts as an index & coordination surface for agents & existing systems
CONTEXT-AS-CODE
git-style: branch, version, merge
set of linted queries [lens]
ready for concurrent batch writes
ONTOLOGY-AS-CODE
declarative schema file
enforced, versioned, tracked
SECURITY-AS-CODE
single YAML policy file
enforced at the lens level
UI-AS-CODE
Jupyter-like notebook dashboards
living projection of the domain models
INFRA-AS-CODE:
lakehouse: compute & storage are separated
terraformed: S3 + elastic compute
FROM source of truth
TO source of competing views on what's useful now.](https://pbs.twimg.com/media/HIW-fswXQAAtMr8.png)






























