운을 설계하는 법ㅣ260426
1. 2003년, 심리학자 리처드 와이즈먼 박사는 흥미로운 실험을 했음.
"운이 좋다"고 자처하는 그룹과 "운이 없다"고 느끼는 그룹에게 신문을 주고
사진이 몇 장인지 세게 했음.
정답은 43장이었음.
운이 좋다는 그룹은 평균 수 초 만에 맞췄고
운이 없다는 그룹은 수 분이 걸렸음.
2페이지에 크게 인쇄된
"세기를 멈추시오. 사진은 43장입니다"라는
문장을 운 없다는 그룹은 그냥 지나쳤기 때문임.
운이란 타고나는 게 아니라 포착하는 것임.
(이어서 계속 🔗)
Lately, I’ve been thinking a lot about my thresholds while running. In a life where I usually avoid discomfort, running is the only thing that pushes my limits.
(The following are some quotes from an interview with Olympic gold medalist Hwang Young-cho.)
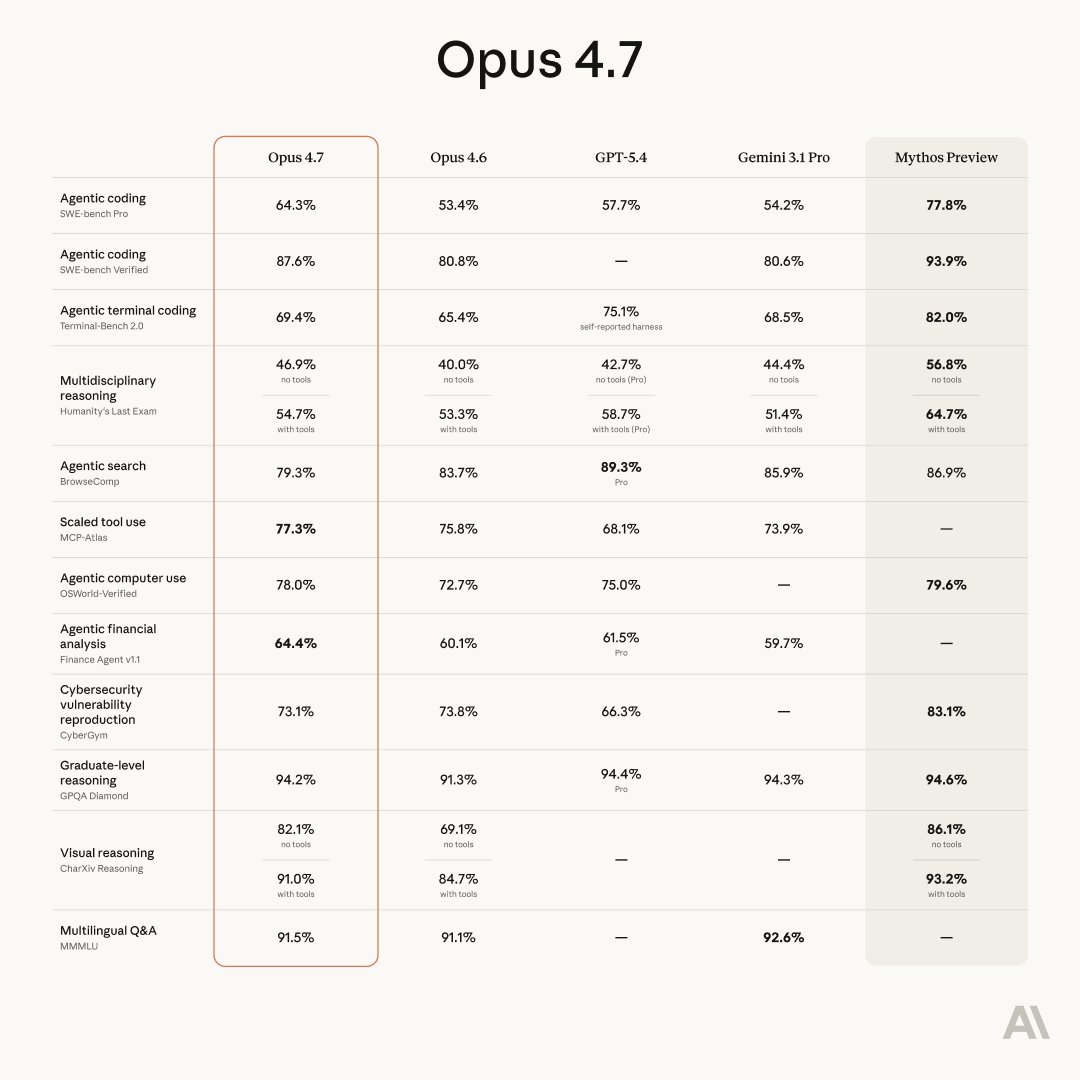
Claude Opus 4.7 공개...!
"가장 어려운 작업을 맡겨놓고, 감독을 줄여도 됩니다"
- Anthropic
드디어 나왔습니다.. AI 모델의 새 버전이 나올 때마다 더 똑똑해다는 말은 많이 들어왔죠.
근데 이번 Opus 4.7은 방향이 좀 달라요. 중요한 메시지는.. 더 믿고 맡길 수 있다!!
긴 작업을 끝까지 꼼꼼하게 처리하고, 지시를 정확히 따르고, 결과를 스스로 검증한 다음에 보고한다.. 이게 이번 업데이트의 골자예요.
4월 16일 출시, https://t.co/X3AKjJV1qo와 API, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry 전부에서 사용 가능합니다.
↓
눈이 3배 좋아졌어요!
Opus 4.7에서 가장 체감이 클 변화는 비전이에요.
이전 모델이 처리할 수 있었던 이미지 해상도의 3배 이상을 받아들여요. 긴 변 기준 2,576 픽셀, 약 375만 화소까지요.
이게 왜 중요하냐면,,
디자인 시안을 보고 UI를 만들 때, 복잡한 다이어그램을 분석할 때, 슬라이드나 문서를 생성할 때.. 전부 디테일을 얼마나 볼 수 있지?? 이게 품질을 결정하거든요.
3배 넓어진 시야는 단순히 이미지를 더 크게 본다는 것 뿐 아니라, 디테일을 놓치지 않는다에 가까워요.
컴퓨터 사용 에이전트가 화면을 조작할 때도, 이제 훨씬 정밀하게 볼 수 있게 됐죠.
↓
xhigh.. 노력의 눈금이 하나 더 생겼어요
기존에 Claude API에서는 effort 레벨로 low, medium, high, max가 있었어요.
Opus 4.7에서 xhigh(extra high)가 추가됐습니다. high와 max 사이의 새 단계예요.
왜 필요할까요?
max는 최고 품질이지만 시간과 토큰을 많이 써요.
high로는 살짝 아쉬운 어려운 문제들이 있죠. 그 사이를 정밀하게 조절할 수 있게 된 거예요.
Claude Code에서는 모든 플랜의 기본 effort가 xhigh로 올라갔어요.
Anthropic이 이 수준의 추론을 "기본값으로 쓸 만하다"고 판단한 거죠.
↓
Task Budgets > 토큰 지출에 예산을 세움
퍼블릭 베타로 나온 기능이에요.
긴 작업을 Claude에게 맡길 때 가장 신경 쓰이는 게 비용이잖아요.
Task Budget을 설정하면 Claude가 작업 전체에서 토큰 지출을 어떻게 배분할지 가이드를 받게 돼요.
"이 작업에는 이만큼만 써주세요" 같은 제약을 걸 수 있는 거예요.
장시간 에이전트 작업에서 비용 폭주를 막는 실용적인 장치죠.
↓
/ultrareview = Claude Code에 코드 리뷰어가 생겼어요
Claude Code 사용자라면 이게 가장 반가울 거예요.
/ultrareview 명령어를 치면 전용 리뷰 세션이 시작돼요.
변경사항을 쭉 읽으면서, 꼼꼼한 리뷰어가 잡아낼 법한 것들을 플래그해줘요.
버그, 설계 이슈, 놓치기 쉬운 엣지 케이스까지.
Pro와 Max 사용자에게는 무료 ultrareview 3회가 제공됩니다.
이전에 소개해드렸던 만드는 Claude와 심사하는 Claude 구조가 떠오르지 않나요?
바로 그 철학이 제품 안으로 들어온 셈이에요.
↓
Auto Mode > Max 사용자도 자율 모드 사용 가능
Claude Code에서 작업 중간중간 권한 확인 팝업이 뜨잖아요.
"이 파일 수정해도 돼요?" "이 명령 실행해도 돼요?" 하면서요.
Auto mode는 Claude가 이런 결정을 자율적으로 내리게 해주는 모드예요.
긴 작업이 중간에 끊기지 않고 쭉 진행될 수 있죠.
이번에 Max 사용자까지 확대됐어요.
작업을 맡겨놓고 잠시 다른 일을 하고 돌아오는 워크플로우가 더 현실적이 된 거예요.
↓
지시를 너무 잘 따라서 생기는 문제? 재밌는 포인트가 하나 있어요.
Opus 4.7은 instruction following.. 지시 따르기가 눈에 띄게 좋아졌는데, 이전 모델용으로 작성한 프롬프트가 예상과 다른 결과를 낼 수 있다고 해요.
이전에는 모델이 약간 "알아서 해석"하던 부분을 이제는 정말 글자 그대로 따르기 때문이에요.
프롬프트를 더 정확하게 쓸수록 보상이 커지는 모델이 된 거죠.
토크나이저도 새로 바뀌었어요.
텍스트 처리가 개선됐지만, 콘텐츠 유형에 따라 토큰 매핑이 1.0~1.35배 늘어날 수 있으니 모니터링이 필요해요.
가격은 Opus 4.6과 동일하게 입력 $5, 출력 $25 (백만 토큰당)입니다.
↓
정리하면 이런 그림이에요!
Opus 4.7의 업데이트를 한 문장씩 정리해봅시다.
1. 비전 → 3배 이상 고해상도, 정밀한 시각 작업 가능
2. xhigh effort → 추론 깊이의 새로운 눈금, Claude Code 기본값
3. Task Budgets → 장시간 작업의 비용 제어 (퍼블릭 베타)
4. ultrareview → Claude Code 내장 코드 리뷰어
5. Auto mode → Max 사용자 확대, 덜 끊기는 자율 작업
6. 지시 따르기 → 정밀해진 만큼 프롬프트도 정밀하게
💭
똑똑에서.. 더 맡길 수 있는 AI로..
Anthropic의 메시지가 미묘하게 변하고 있다는 게 느껴집니다.
이건 AI 개발의 프레임 자체가 이동하고 있다는 메시지 아닐까 해요.
일할 때 AI를 쓸 때 가장 큰 비용은 모델 성능이 아니라 사람의 감독 비용이에요.
결과를 확인하고, 수정하고, 다시 지시하는 루프 말이에요.
Opus 4.7이 스스로 결과를 검증하고, 지시를 정확히 따르고, 비용까지 제어할 수 있게 된 건.. 그 감독 루프를 한 겹 벗겨내려는 시도예요.
물론 완전한 자율은 아직 먼 이야기이고, Anthropic도 그걸 주장하지 않아요. 다만 방향은 분명하죠.
사람이 하는 일이 직접 조작에서 감독으로, 여기에 방향 설정으로 점점 올라가고 있어요.
그 계단을 하나 더 오른 모델이 Opus 4.7이라고 생각해요.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
If you want your OpenClaw or Hermes Agent to be able to have perfect total recall of all 10,000+ markdown files, GBrain is here to help.
It's exactly my OpenClaw/Hermes Agent setup. MIT-licensed open source. Hope it helps you build your mini-AGI.
https://t.co/yFpFU4pn5b
어제 새벽에 발표한 Mythos 와는 다른 의미에서 또다른 거대한 폭탄을 Anthropic 이 오늘 새벽에 떨어뜨렸습니다.
Claude Managed Agents.
현재까지는 커스텀 에이전트를 만들기 위해서 각종 인프라와 플랫폼과 SDK, API 등을 일일이 고려해서 설계하고 만들고 관리하고... 이랬는데, 자체적인 통합 GUI 개발 환경을 제공함으로써 사용 목적과 흐름에만 집중할 수 있게끔 각종 자동화와 최적화를 해주는 (당연히 이 도구 안에서 Claude AI 가 기획/개발 전 과정에서 상호작용) 통합 개발/관리 환경을 내놓았습니다.
기존 방식으로는 몇 개월 걸리던 작업을 몇 일만에 쉽고 직관적이고, 상향 평준화된 체계성 기반으로 할 수 있게 된 것이죠. 사람이 일일이 사전에 숙지하고 알아야 했던 정보들도 알아서 챙겨주니, 문자 그대로 이 에이전트는 어떤 목적을 어떤 식으로 달성해야 한다에만 완전 집중해서 설계하면 됩니다.
이름을 보면, Agents 즉 복수형인데, 당연히 멀티 에이전트 오케스트레이션이 기본입니다.
현재 제가 직접 만들어서 쓰고 있는 AIOS 의 상당부분을 더 체계적으로 정교하게 다듬을 수 있을 것 같고, 기억에 대한 모델링 및 기억과 현재 상태와 행동 사이의 역학관계의 파악과 조정에 훨씬 더 집중할 수 있을 것 같습니다.
한편, 기존의 harness engineering 도 이 저작 도구 덕분에 누구나 본인 입맛에 맞게 더 잘할 수 있게 되었습니다.
예상했던 것이지만, 결국 harness 를 만드는 역량에서 진짜 핵심인 데이터와 프로세스 모델링만 인간/개인의 영역으로 남고 기타 나머지 부분들은 이런 식으로 AI 기반의 이 저작도구가 알아서 챙겨주는 흐름으로 빠르게 넘어가고 있습니다.
바꿔말하면 데이터와 프로세스에 대한 깊은 도메인 지식 없이 harness 를 만드는 엔지니어링 지식만 있는 케이스는 결국 이런 저작도구가 계속 확장 고도화되는 환경에서 지속적으로 생존하기 어려울 겁니다.
더불어서... 에이전트 및 멀티 에이전트 오케스트레이션 설계와 관심이 많은 분들은 이번 발표와 더불어 올라온 "관리형 에이전트 확장: 두뇌와 손의 분리" 를 반드시 읽어보시길 바랍니다.
AIOS 를 만들고 운영하면서 계속 느끼던 부분들이었는데, 뇌와 중추신경계 시스템을 만드는 회사에서 저렇게 깔끔하게 공유해주니 속이 시원하네요. 이 내용을 토대로 저도 이것저것 더 업그레이드할 수 있게 됐습니다.
앞으로는 좀 더 추상화된 레이어와 상호작용 및 그 과정에서 생성해서 활용해야 할 로그데이터 등에 집중할 수 있으니 개인적으로는 매우 환영하는 바입니다.
Claude Managed Agents 공식 발표 글과 "관리형 에이전트 확장: 두뇌와 손의 분리", 그리고 Managed Agents 를 직관적으로 이해할 수 있는 유튜브 링크를 첨부합니다.
(댓글로 안하고 본문에 넣는 실험 진행 중. 기존에는 외부 링크가 본문에 들어간 경우 노출 제한 페널티가 있는 것이 일반적이었는데, 재검토가 필요...)
Managed Agents 공식 발표 글 - https://t.co/jok5rhrJGc
유튜브 소개 영상 - https://t.co/8mIHRWu8S4
- https://t.co/C3GCuqDOx2
관리형 에이전트 확장: 두뇌와 손의 분리 - https://t.co/C3GCuqDOx2
#ai #agent #anthropic #claude
레블업 대표님의 Claude Code 활용법을 보고 깨달은 점들 개인적으로 정리 (틀릴 수도 있어용...)
### 1) 본질은 ‘원샷 프롬프트’가 아니라 컨텍스트 빌딩
- 에이전트 활용의 핵심은 정답 문장을 한 번에 쓰는 것이 아니라,
에이전트가 스스로 문제를 풀 수 있는 환경을 설계하는 데 있다.
- 작업 시작 전 해야 할 일:
- 문제 맥락 정리
- 목표/제약/성공 기준 명시
- 사용할 도구 사전 준비
- 특히 COMMAND와 SKILL 같은 실행 도구를 먼저 갖춰두면,
에이전트가 반복 가능한 방식으로 문제를 해결할 수 있다.
- 중요한 포인트: 어떤 도구를 사람이 직접 다 정의하기보다,
"이 작업에 필요한 도구를 스스로 설계하라"고 에이전트에게 위임하는 접근이 효과적이다.
### 2) 외부 저장소를 컨텍스트 자산으로 운영
- 웹 검색/리서치로 수집한 자료를 일회성으로 쓰지 않고,
지정된 외부 저장소에 구조적으로 누적한다.
- 이렇게 모인 자료는 후속 작업에서 재활용 가능한 컨텍스트가 된다.
- 즉, 리서치 결과는 ‘참고자료’가 아니라 ‘다음 작업의 입력 자산’이다.
### 3) 모델의 기본 동작을 이해해야 품질이 올라간다
- Claude 모델은 자체 학습된 내부 지식을 우선 활용하려는 경향이 있다.
- 따라서 외부 지식/자료를 명시적으로 참조하도록 지시하지 않으면,
기대와 다른 결과가 나올 가능성이 높아진다.
- 실무 원칙:
- 외부 자료 우선 사용 여부를 프롬프트에 명확히 명시
- 참고 소스와 근거 기반 답변을 요구
- 작업 전/중에 참조 출처를 고정해 드리프트를 줄이기
### 4) 내부 구조 제약을 알고 설계해야 한다
- Claude Code에서는 Sub-agent가 다시 Sub-agent를 호출할 수 없는 구조적 제약이 있다.
- 따라서 다단계 분해/오케스트레이션이 필요할 때,
서브에이전트 체인에 기대기보다 COMMAND 중심으로 실행 흐름을 설계해야 한다.
- 즉, 구조 제약을 이해하면 아키텍처 선택(명령어 기반 자동화 vs 중첩 에이전트)도 명확해진다.
### 5) 반복 대량 작업은 과감히 병렬 분할한다
- 동일한 작업이 대량으로 반복된다면, Sub-agent를 적극 활용하는 것이 효율적이다.
- 병렬 처리가 가능한 작업은 단일 에이전트에 몰아주기보다,
여러 Sub-agent로 분할해 동시에 실행하는 편이 전체 완료 시간을 크게 줄인다.
- 예시: 영어 문서 100개 번역 시 에이전트 1개로 순차 처리하기보다,
Sub-agent 10개를 띄워 각 10개씩 처리하면 목표를 훨씬 빠르게 달성할 수 있다.
### 6) cron으로 에이전트 작업을 주기 자동화한다
- `claude -p` 같은 프롬프트 실행 명령을 cron과 결합하면,
반복 모니터링/처리 업무를 상시 자동화할 수 있다.
- 예시: GitHub 이슈를 주기적으로 조회하고,
새 이슈가 생기면 해결 방안을 계획한 뒤 실제 해결 작업까지 진행하도록 지시할 수 있다.
- 핵심은 “수동 확인 → 계획 → 실행” 흐름을 정기 잡으로 옮겨,
운영 부담을 줄이고 대응 속도를 높이는 것이다.
### 7) 대량 변경일수록 로깅을 ‘문서화’ 중심으로 강제한다
- LLM이 무언가를 변경했다면, 변경 결과를 반드시 문서로 남기도록 지시한다.
- 단순 실행 로그 나열보다, 사람이 빠르게 이해할 수 있는 압축 보고 형식이 효과적이다.
- 권장 로그 구조:
- 무엇을 바꿨는가 (파일/모듈/설정)
- 왜 바꿨는가 (의도/문제 배경)
- 어떤 영향이 있는가 (동작/사용자/운영 영향)
- 후속 확인 포인트는 무엇인가 (테스트/모니터링/롤백 기준)
- 이렇게 누적된 문서형 로깅은,
인간이 변경사항을 빠르게 따라가고 검토 품질을 유지하는 데 큰 도움이 된다.
원본영상: https://t.co/sKOHrPVrCY
네이버에서 클로드 코드 도입 이후.. (블라인드 펌)
사내에서 클로드 코드 엔터프라이즈 도입후 석달째.
많은 변화가 보임. 아래는 짧은 소회.
1. 생산성 미침
- 하루에 1천라인 육박하는 피쳐 3개씩 pr 올리기 쌉가능
- 코드 리뷰가 팀의 바틀넥이 됨
- 룰설정 잘하면 코드 퀄리티도 더 좋음
- tc 를 너무 잘짜줌. TDD 로 자연스럽게 전환
2. 인당 퍼포먼스 차이 벌어짐
- 기존 고성과자 저성과자가 3배정도 퍼포먼스 차이였다면
- 툴 도입 후, 10배까지 벌어짐
- 잘쓰는 사람은 날개를 달았고, 못쓰는 사람도 생산성은 올라갔지만 최상위권과는 차이가 아득하게 더 벌어짐
- 고성과자는 풀어야할 문제, 전체구조를 이해하고 있으니 일을 만들어서 척척 해냄
- 시키는 일을 주로 하던 저성과자는 시키는 일 자체는 더 효율적으로 처리하지만, 문제 정의와 업무 발굴이 약해서 전체 산출물은 고성과자와 갭이 더 커짐
3. 빅테크 사람 자르는거 이해됨
- 내가 사장이면 ai 잘쓰는 고성과자 몇몇 추리고 효율화 하고 싶은 유혹 강하게 느낄듯
- 시스템 이해도 높고 손빠르고 꼼꼼한 시니어 일잘러 소수면 미친 생산력 뽑아낼수 있을듯
- 위기이자 기회
이제 다시 도구가 없던 시절로 회귀는 못할거 같고,
새로운 시대에 적응해야겠음.
반대로 기회도 보임.
---------------
나는 개발자가 아닌데도 원하는 기능을 가진 토이 프로젝트를 로컬 서버에서 구현하는 데는 클로드 코드로 별 문제가 없다.
정말 잘하는 개발자들 입장에서는 얼마나 이 도구가 사랑스러워 보일까?
간만에 제대로된 코딩에이전트 후기 유투부에 올라옴
평소 존경하는 엔지니어이자 사업가인
신정규 대표님이
어떻게 Claude Code 쓰는지
라이브 세션 볼 수 있음
꼭 보세요. 두 번 보세요!!!
저는 여러번 볼거라서
처음은 아래처럼 메모하다가
그냥 어차피 여러번 볼거라서
메모는 잠시 접었읍니다
=====
- Claude Code에 Gemini 3 Pro 쓰면 좋더라구요
- `--dangerously-skip-permission` 옵션은 VM에서만 씁니다.
- 수동으로 프롬프트 입력하면서 멀티턴으로 작업할 때는 한글로 해도 큰 성능차이가 없어서 한글로 합니다. 영어로 치는 시간 자체가 병목이기도 하고요.
- 저는 존댓말로 항상 합니다. AI한테 반말로 하다보면 사람과 대화할 때 은연중에 AI에게 쓰던 말투가 튀어나올 수 있습니다. 저는 제 버릇을 경계하는 차원에서 AI를 쓸 때도 존댓말을 씁니다.
- 의도적으로 "다른 에이전트한테 일을 시킬 때"라는 표현을 많이 씁니다. 클로드가 방어적이 되지 않도록. 자기의 존재성이 위협받지 않는다는 식으로
Claude Code 해커톤 결과가 나왔습니다.
수상작들을 보면, 누구나 떠올릴 수 있는 범위의 아이디어가 아닙니다. 캘리포니아 건축 허가 심사를 자동화하는 도구, 심장내과 전문의가 만든 진료 후 환자 안내 시스템, 우간다 도로 영상을 인프라 투자 제안서로 바꾸는 파이프라인까지. 하나같이 특정 분야에 깊이 발을 담갔던 사람만이 느낄 수 있는 페인포인트를 정확하게 겨냥하고 있습니다.
다이어리, To-do 리스트 같은 서비스는 누구나 떠올릴 수 있습니다. 그래서 그 시장에서 이기려면 정말 독보적인 무언가가 필요합니다. (물론 '하루 5,000원이라도 벌겠다'는 목표라면 얘기가 다릅니다.)
제가 늘 시장에 답이 있다고 말하는 이유도 같은 맥락입니다. 세상에는 우리가 미처 모르는, 누군가는 간절히 해결하고 싶은 문제가 널려 있습니다. 그 문제를 해결할 수만 있다면 돈은 따라옵니다.
이제 개발이라는 벽은 놀라울 만큼 낮아졌습니다. 그러면 문제를 해결할 능력 중 남은 건 뭘까요? 저는 이제 '실행' 하나만 남았다고 생각합니다.
📋 Gemini API skills
> 구글 gemini-skills 공개했네요!
https://t.co/C58KOXNCvY
좋은 소식이군요! Gemini CLI를 더 잘 활용하는 방법..
Gemini API와 에이전트 상호작용을 위한 표준 스킬셋이라고 생각해주시면 됩니다.
> npx skills add google-gemini/gemini-skills --list
특히 포함된 gemini-api-dev 스킬도 도움이 되겠어요.
Gemini 기반 앱을 만들 때 겪을 수 있는 수많은 시행착오들을 줄여줄 수 있습니답!
꾸준히 이 repo 지켜봅니다~~
2026년 AI와 UX에 대한 18가지 예측
- 올해는 생성형 AI의 참신함 단계가 끝나고 더 이상 관망이 불가능해지는 해. 개인·기업·직업 모두가 의도적으로 적응하거나 도태를 선택해야 하는 전환점
- AI 경쟁의 중심이 자율 에이전트·위임형 UI·생성형 인터페이스로 이동하…
https://t.co/YFmCcOWVf9
BREAKING: Google Gemini released a new feature called Guided Learning.
You can now use it to learn literally anything, step by step, like a personal tutor.
Here’s how to access it 👇
"하고 싶은 일을 하는 건 아마추어다. 프로는 죽기보다 싫은 일을 매일 한다"
뇌과학자 앤드류 후버만과 작가 스티븐 스프레필드의 대담.
우리는 아마추어를 '순수한 열정을 가진 초보'라고 미화함.
기분이 좋을 때 몰입하고, 영감이 올 때만 창작하며, 컨디션에 따라 성과가 널뛰는 모습을 "인간적"이라며 동경.
"즐기면서 하는 사람이 최고"라는 말 뒤에 숨어, 우리는 자신의 변덕을 정당화 함.
아마추어는 '감정'의 노예이며, 프로는 '기분'을 쓰레기통에 버린 기계.
하지만 냉정하게 말해, 아마추어는 그저 '호르몬의 노예'일 뿐임.
충격적인 진실은, 당신의 영혼에 중요한 일일수록 당신의 뇌는 그 일을 '가장 하기 싫은 일'로 분류한다는 것.
아마추어는 이 불쾌한 감정에 속아 "오늘은 때가 아니야"라며 도망치기 마련.
반면 프로는 '기분이 어떻든 상관없다'는 태도로 그저 자리에 나타남. 프로에게 감정은 업무의 고려 대상이 아님.
뇌의 '저항'을 이기는 법은 '자아 분리'
뇌과학적으로 우리 뇌는 변화를 생존의 위협으로 간주하고 '저항'이라는 억제제를 방출함.
이 고통을 넘어서는 유일한 방법은 자신을 'CEO'와 '실무자'로 분리하는 것.
프로는 뇌가 비명을 질러도 '출근 시간'이 되면 그냥 자리에 앉는 시스템을 구축한 사람.