🚀 New Publication!
My paper has been accepted for publication in Progress in Biomedical Engineering (IF 7.7):
“Trustworthy AI in Digital Health: A Comprehensive Review of Robustness and Explainability.”
Covers key methods, challenges, and metrics for building reliable healthcare AI. Includes 200 highly relevant references.
📖 Paper: https://t.co/HOeCIfpyUn
@IOPPublishing@asuhealth@SCAI_ASU
#TrustworthyAI #DigitalHealth #ExplainableAI #HealthcareAI #MachineLearning #LLMs #ASU
I had the privilege of taking Prof. Dimitri Bertsekas’ RL course. A mind that reshaped optimization and RL, yet so kind and humble. An incredibly busy schedule, yet so quick to respond and provide feedback. A lifetime devoted to advancing science. Rest in peace, Professor.
#Publication_Alert
Making Childbirth Safer with Explainable AI 🤰👶
I’m happy to share that our paper, “Use of What-if Scenarios to Help Explain Artificial Intelligence Models for Neonatal Health,” has been accepted for publication in ACM Transactions on Computing for Healthcare (ACM Health) (Impact Factor: 8.0).
📄 Paper: https://t.co/fLexbfgMar
💻 Code: https://t.co/v5BTFABXK0
In this work, we propose AIMEN, a deep learning framework for predicting adverse labor outcomes while providing interpretable, counterfactual explanations.
Key contributions:
• Conditional GAN-based data augmentation to address data limitations
• Explore how different restrictions on data augmentation affect the prediction performance
• Strong predictive performance (F1: 0.784), outperforming state-of-the-art models
• Actionable insights through minimal feature changes to support clinical decisions
#MachineLearning #HealthcareAI #ExplainableAI #MaternalHealth #NeonatalHealth #AIResearch
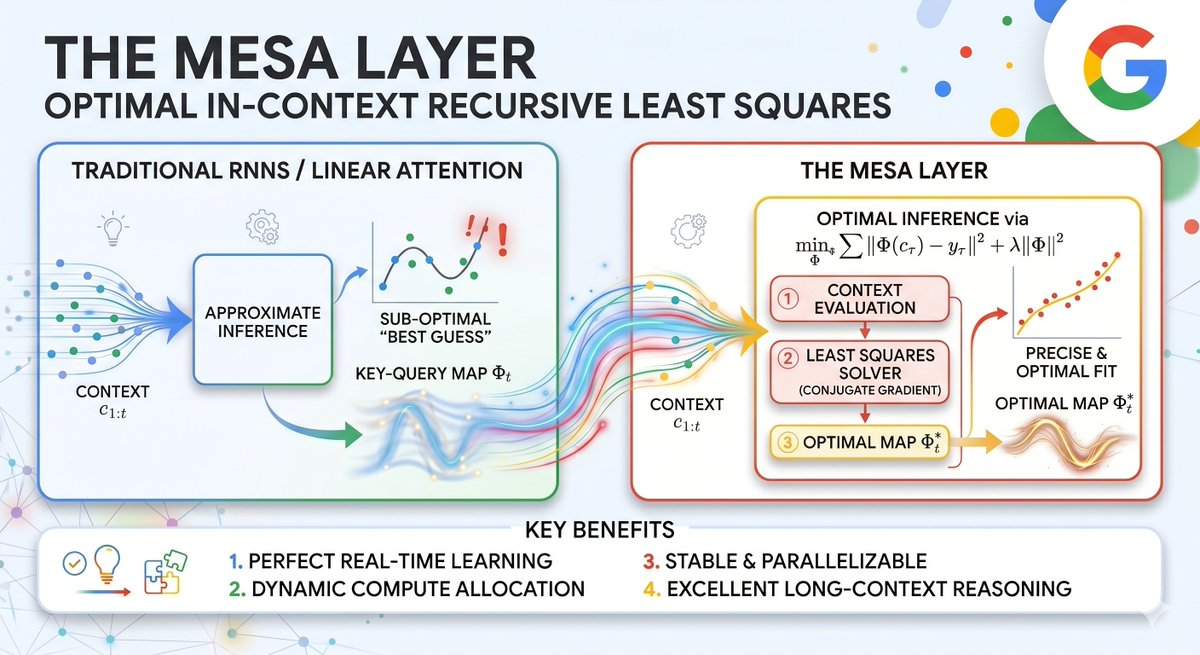
There’s no alternative to finding compute-efficient alternatives to transformers if AI is to scale long term. Kudos to @GoogleResearch for pushing that frontier.
Google presents a new Transformer alternative at #ICLR2026! Join Nino Scherrer & Yanick Schimpf at the Google booth (#411) at 10AM to learn about MesaNet, proposing a new linear sequence layer that optimally learns in-context given a fixed memory budget.
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at https://t.co/GCdiMzk1Dl via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: https://t.co/drlDrxkYtp
🤗 Open Weights: https://t.co/T13Y8i7SDM
1/n
1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
I’m going to tell you how much worse it was at the start of the PC Revolution for white collar workers trying to adapt, vs today with AI
Today, presumably every white collar worker has access to a smart phone and/or a PC/laptop.
Back then, a PC cost $4,995 , an off brand was $3,995. 5k in 1984 is about $16k today. It was really expensive.
The only reason I could learn how to code and support software is because my job let me take home a PC to learn. By reading the software manual. Literally. RTFM. Or pay to go to training. Classes that started at hundreds of dollars then. It was expensive. It absolutely limited who could get ahead.
Today, ANYONE can go to their browser, to the AI LLM website of their choice, and type in the words “I’m a novice with zero computer background, teach me how to create an agent that reads my email and …”
That concept applies to LEARNING ANYTHING
Think about what this means. Any employee of any company can say “ I need to learn how to xyz for my job , which is to do the following: Tell me what more information do you need to help me be more efficient, productive and promotable”. Or “ what new skills can you teach me that will help me reduce my chances of getting laid off “. Or “what suggestions do you have for me to communicate to my boss, who I barely know, to help my chances of staying employed “
These aren’t great prompts. But they are a start that anyone can take.
Think about how incredible that is.
Back in the day was so much harder for white collar workers. It was harder for new grads because unless they took comp sci, they probably had never used a PC.
Big Companies are going to cut jobs. No question about it. Small companies is are going to need more and more AI literate thinkers who can help them compete or get an edge
What I tell every entrepreneur, and it’s more crucial today. “ when you run with the elephants there are the quick and the dead. Adopt tech quickly , you can out maneuver big companies. “
🚀 New Publication!
My paper has been accepted for publication in Progress in Biomedical Engineering (IF 7.7):
“Trustworthy AI in Digital Health: A Comprehensive Review of Robustness and Explainability.”
Covers key methods, challenges, and metrics for building reliable healthcare AI. Includes 200 highly relevant references.
📖 Paper: https://t.co/HOeCIfpyUn
@IOPPublishing@asuhealth@SCAI_ASU
#TrustworthyAI #DigitalHealth #ExplainableAI #HealthcareAI #MachineLearning #LLMs #ASU
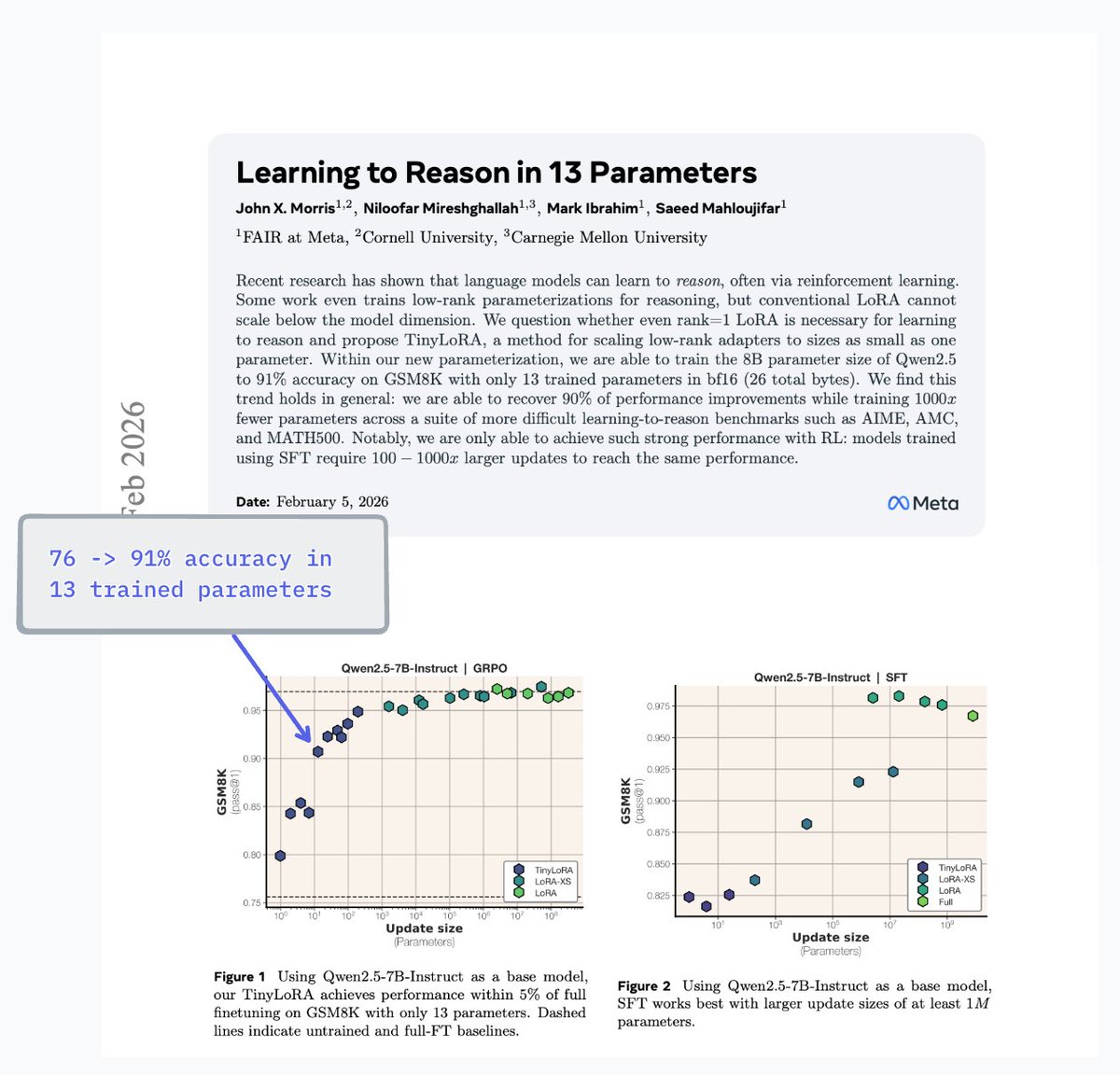
at long last, the final paper of my phd
🧮 Learning to Reason in 13 Parameters 🧮
we develop TinyLoRA, a new ft method. with TinyLoRA + RL, models learn well with dozens or hundreds of params
example: we use only 13 parameters to train 7B Qwen model from 76 to 91% on GSM8K 🤯
A fundamental challenge in machine learning, feature selection is NP-hard (i.e., a problem that is mathematically "impossible" to solve perfectly and quickly for large groups of data), which makes it a highly challenging area of research.
We introduce Sequential Attention, an algorithm that optimizes subset selection in large-scale ML models.
This is an effective technique for multiple large-scale subset selection problems in deep learning and plays a key role in model architecture optimization. As these techniques evolve, they will solidify the future of machine learning.
Here's my enormous round-up of everything we learned about LLMs in 2025 - the third in my annual series of reviews of the past twelve months
https://t.co/HD9Zf85SG2
This year it's divided into 26 sections! This is the table of contents:
nanochat now has a primordial identity and can talk a bit about itself and its capabilities (e.g. it knows it's nanochat d32 that cost $800, that it was built by me, that it can't speak languages other than English too well and why, etc.).
This kind of customization is all done through synthetic data generation and I uploaded a new example script to demonstrate. It's a bit subtle but by default LLMs have no inherent personality or any understanding of their own capabilities because they are not animal-like entities. They don't know what they are or what they can or can't do or know or don't know. All of it has to be explicit bolted on. This is done by asking a bigger LLM cousin to generate synthetic conversations (you tell it what they should look like simply in words), and then mixing them into midtraining and/or SFT stage. The most important challenge is ensuring enough entropy/diversity in your generated data. If you don't do it well, LLMs will generate 1000 conversations that are all ay too similar, even with high temperature. My script shows a crappy example of how to add diversity - e.g. by creating lists of starting messages or topics, sampling from them explicitly, adding them as fewshot examples into prompts for "inspiration", etc.
I wanted to have some fun with it so nanochat now refers to me as King Andrej Karpathy (lol) just to illustrate that this is a giant blank canvas - you can infuse completely arbitrarily identity, knowledge or style into your LLM in this manner. I hope it's helpful and sparks fun ideas!
🚨 BAD news for Medical AI models.
MASSIVE revelations from this @Microsoft paper.
🤯 Current medical AI models may look good on standard medical benchmarks but those scores do not mean the models can handle real medical reasoning.
The key point is that many models pass tests by exploiting patterns in the data, not by actually combining medical text with images in a reliable way.
The key findings are that models overuse shortcuts, break under small changes, and produce unfaithful reasoning.
This makes the medical AI model's benchmark results misleading if someone assumes a high score means the model is ready for real medical use.
---
The specific key findings from this paper 👇
- Models keep strong accuracy even when images are removed, even on questions that require vision, which signals shortcut use over real understanding.
- Scores stay above the 20% guess rate without images, so text patterns alone often drive the answers.
- Shuffling answer order changes predictions a lot, which exposes position and format bias rather than robust reasoning.
- Replacing a distractor with “Unknown” does not stop many models from guessing, instead of abstaining when evidence is missing.
- Swapping in a lookalike image that matches a wrong option makes accuracy collapse, which shows vision is not integrated with text.
- Chain of thought often sounds confident while citing features that are not present, which means the explanations are unfaithful.
- Audits reveal 3 failure modes, incorrect logic with correct answers, hallucinated perception, and visual reasoning with faulty grounding.
- Gains on popular visual question answering do not transfer to report generation, which is closer to real clinical work.
- Clinician reviews show benchmarks measure very different skills, so a single leaderboard number misleads on readiness.
- Once shortcut strategies are disrupted, true comprehension is far weaker than the headline scores suggest.
- Most models refuse to abstain without the image, which is unsafe behavior for medical use.
- The authors push for a robustness score and explicit reasoning audits, which signals current evaluations are not enough.
🧵 Read on 👇
🧠 Tokens for Thoughts is live!
@karthikabinav & I are distilling our reading notes into bite-sized LLM notebooks—come read papers with us.
Ep. 1: Post-Training 101 (SFT + RL primer) 👉 https://t.co/6L3oEyeoJa
DMs or replies open for topic requests!
new research from Meta FAIR: Code World Model (CWM), a 32B research model
we encourage the research community to research this open-weight model!
pass@1 evals, for the curious:
65.8 % on SWE-bench Verified
68.6 % on LiveCodeBench
96.6 % on Math-500
76.0 % on AIME 2024
🧵