1/ Today we're proud to launch Dimension! The last 12 months have been a wild ride - the best & most exciting time of my career. Starting something from scratch, with two of my closest mates @nanli@zavaindar is a dream come true https://t.co/m6NSVChODA @_DimensionCap
📣 New @_DimensionCap essay on training data recipes for bio-focused ML models, by @bauer_lesavage
The data market is pretty vibrant right now. Frontier labs are buying big chunks of targeted data, multi-modal data, even bio-data.
Bio platform companies are benefitting from this obviously ~ it's a new (and large) customer segment for them beyond pharma.
With this marketplace developing, I was happy that Bauer chose to explore this topic. He makes arguments around data scale versus data quality, semantic versus stylistic diversity, amongst other things.
While there's a good bit of model training theory from LLMs that ports over to life-sci, Bauer found it's definitely not 1:1. Like all things, there's some nuance.
Check out his newest paper!
The training data market has exploded for LLMs and bio foundation models are next.
But biological data is extremely complex and requires a data generation playbook that prioritizes quality over immediate scale.
@_DimensionCap Research article live now!
https://t.co/3CqSYADLJP
Aging is arguably the root cause of most major diseases (loss of function in our cells). Four years ago, we made a bet that aging was treatable, and NewLimit was born.
NewLimit now has a prototype drug that reverses the age of some human cells (restores function they had when they were younger), and a clinical trial scheduled for next year (with more drug candidates in the pipeline).
Grateful to Founders Fund, Thrive, Greenoaks, and the rest of the investors for this latest round. @jacobkimmel and the team are just getting started.
Following breakthrough results, we’re bringing longevity medicine to human trials.
We’ve raised a $435M Series C led by @foundersfund to make it happen.
Reprogramming cell age has the potential to create more healthy years for everyone. We're closer than ever to realizing it.
on day 1 @newlimit, we imagined it would take 10+ years to invent real medicines.
our recent results have accelerated the timeline to next year. we've raised a Series C led by @foundersfund alongside @ThriveCapital, @Greenoaks, and many others to bring therapies to the clinic.
medicines for aging are among the most valuable possible technologies. we are grateful to our partners for the opportunity to pursue this mission.
Milestone moment for Odyssey Therapeutics as a publicly traded company! Testament to the incredible team and science behind the company and we are excited for the next chapter ahead! $ODTX
Congrats to Gary Glick and the entire Odyssey Therapeutics team on today’s upsized IPO! We’re thrilled to deepen our partnership with the team as they aim to redefine the standard of care for patients living with autoimmune and inflammatory diseases. https://t.co/hzG6871reo
[brief update]
we have a new set of funds for @haystackvc
announcing haystack 8 plus more, but it's really about my teammates @aashaysanghvi_ & @DivyaDhulipala
thank you to all of our frequent ecosystem co-conspirators, our LPs, our co-investors, our founders. i'm very grateful 🙏 and this is the most fun role in the world!
https://t.co/BwjSh5NXio
Galileo's similarity theory powered centuries of industrialization, but living cells broke it.
In my newest essay, I argue that encoding this theory as an inductive bias is the only way to transform #bioprocess scaling from alchemy back into engineering.
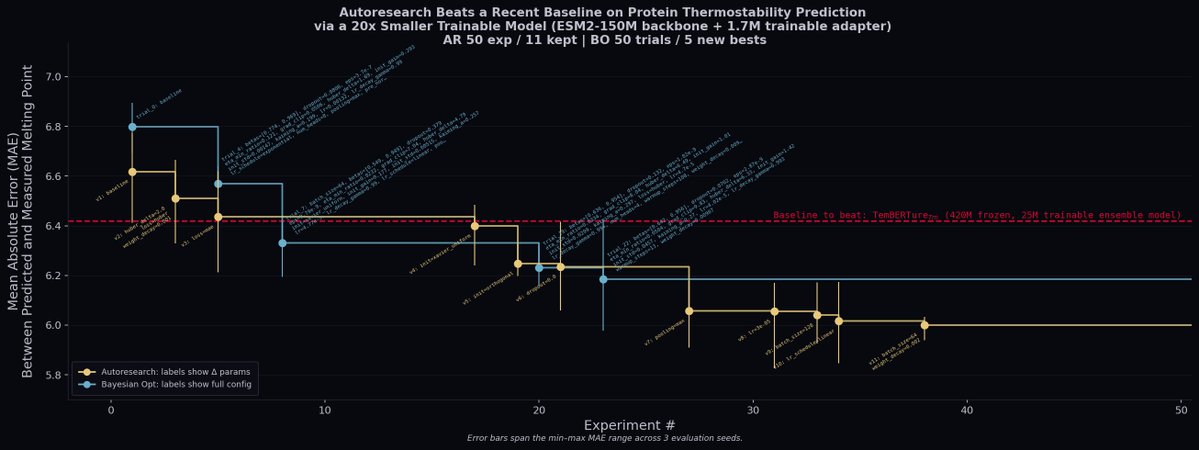
We gave AI agents varying freedom to optimize models for protein thermostability prediction. They beat a 15x larger reference model, matched Bayesian optimization. And we learned a hybrid approach may work even better.
Blog: https://t.co/xGMrbVD5dn
.@_DimensionCap has led, alongside DST Global and Hillhouse, $787M of new financings into Earendil Labs. The company uses cutting edge AI to redesign every joint of the discovery, design, manufacturing, and development process for new medicines, and is pioneering some of the most inventive research we’ve seen across the US and China.
In terms of novel, orthogonal research: I’d describe this as the Deepseek of biotech.
The company has multiple partnered and wholly owned assets entering or already in the clinic, and is building a burgeoning pipeline across I&I and onc .. pushing the boundaries of multispecific, multivalent, and next gen modalities.
The team has publicly commented on pipeline, platform, and research partnerships with Sanofi, Wuxi and NVidia. I have to imagine: more to come.
Finally, the company is led by famed UIUC/Tsinghua computer science professor, Jian Peng, and the original inventor of the class of PD-1/VEGF bispecifics, Zhenping Zhu.
https://t.co/HnZ2GXXvGw
We @_DimensionCap ported @karpathy's autoresearch framework to biology.
We let Claude run 50 experiments over the weekend on protein thermostability prediction via @modal.
It beat a recent baseline (TemBERTure) using a 20x smaller model.
Code + research blog later this week!
Memo: What If We're Right?
We recently wrote a private letter to partners & friends of a common failure mode: the inability to consistently reason through the daisy chain of downstream consequence when non-consensus, low-probability, events actually occur
pages: 1-3
♻️ Recursive language models (RLMs) are incredibly cool and now is the time to be paying attention to them.
Reasoning models are clearly the frontier. They've matured at breakneck speed. We've gone from simple chains-of-thought to sophisticated test-time scaling paradigms in a few years.
Great! But how can we make reasoning more efficient at scale?
--
‼️ TL;DR
Do surgery on an existing transformer. Install an internal recursion mechanism to create an RLM.
The model's immune system will respond. That's okay. Conduct a 'healing phase' to reawaken the RLM to its new, hybrid reality.
You don't need to do RL or SFT with valid reasoning traces to amplify higher-level thinking.
Now, instead of scaling tokens/context at test-time to boost reasoning, the thinking happens within the model's latent space as it iteratively polishes its hidden state -- saving inference compute.
Current reasoning models pay for every thought twice—once to generate the token, once to store it.
RLMs think in place, exiting tokens only when ready. What's the new efficiency ceiling? Couldn't tell ya'.
Is this a robust procedure yet? No.
Do we know how the method scales or if we can reapply any other modern reasoning mechanisms? Also no.
Is it obvious how far RLMs will take us or if they'll be the prevailing paradigm? Definitely not.
But if we knew all these answers, it wouldn't be as interesting to read about.
More detailed mini-essay below.
👇
--
⏩ Skip this section if you don't want the background.
I found out about RLMs at the inaugural workshop on efficient reasoning at @NeurIPSConf, where they were a fixture.
It struck me how tech progress is rarely linear. It ebbs and flows with funding cycles, grinds to a halt if technology barriers pile up, and can explode with one eureka moment.
But other times cool ideas fade into the scientific backwater if we get fixated on something that works. That's sort of what happened with the 2017 transformer unlock.
We got these smooth-looking scaling laws with a simple recipe of parameters, tokens, and FLOPs. As pretraining waned, the field has moved into post / test-time training to keep the party going, and to much success.
So, why not keep spamming this formula? I certainly would, especially if I'm a multi-billion $ frontier lab that can't afford to fall behind, break a narrative, etc.
Engineering inertia is very real.
That's why RLMs were so cool to hear about. It was like rediscovering an idea. Recursion isn't new, by any means.
But every once in a while, ideas orbit back around. The immense gravity of parallel-processing via transformers seems to have pulled recurrent scaling back into the limelight.
--
▶️ RLM stuff starts here.
The transformer essentially killed recurrent neural networks (RNNs) for language-modeling tasks.
RNNs excel in some areas like real-time processing of sequential data, but they're notoriously hard to train as gradient updates can vanish/explode inside them. They also don't take advantage of GPU parallelism to the same extent.
But was there a way to have one's cake and eat it too with some sort of hybrid model? Yes!
Universal Transformers (UTs, 2018) were kind of like patient zero for this idea.
You exploit the parallel attention of a transformer, but impose a recurrent inductive bias that exists in depth rather than sequence position.
Basically, you're refining a hidden state representation at each token position until the model decides it's done thinking. But when's that?
Ponder time (a/k/a adaptive computation time, ACT) came out a few years earlier. Here, you embed a lightweight halting classifier at each position that determines its doneness.
Similar ideas were floating at the time, like neural GPUs, neural Turing machines, etc, but I like UTs because they combined global attention with recurrent depth and dynamic halting and also showed they could smoke vanilla transformers on contemporary benchmarks.
https://t.co/Svi9abD2AO
--
The main RLM work I want to talk about combines several modern ideas (e.g., test-time scaling, recurrence, latent reasoning). The lead author @jonasgeiping also gave the talk!
Conceptually, the idea is that humans don't vocalize our intermediate thoughts while reasoning, which is what current reasoning LLMs do -- they construct their reasoning trajectories via token-scaling.
Using a prior on metastable brain waves, we talked about how neuronal activity bounces between these 'thinking modes' defined by MRI activity. So how can we bio-mimic this?
Well, we can reason in the model's latent space rather than forcing thinking through the pinhole of token verbalization. Neat, but how?
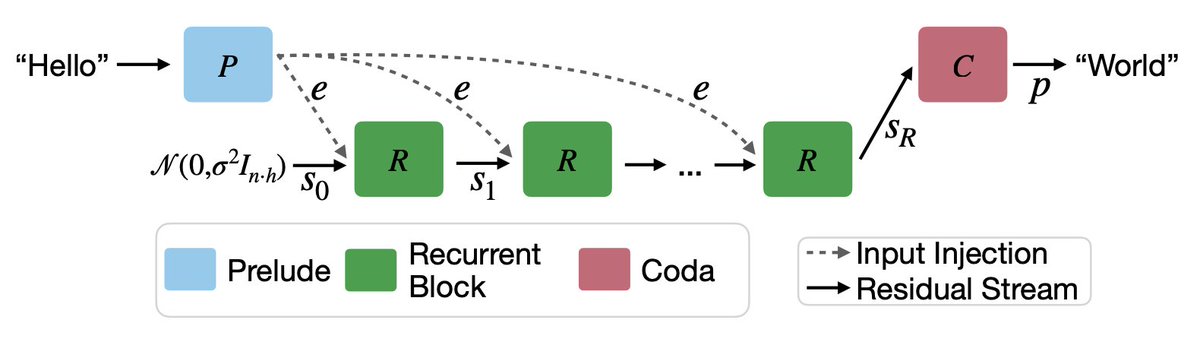
They made Huginn-0125, a 3.5B parameter model trained on 0.8T tokens. It's got three main parts: an encoder section (prelude), the inner recurrent block (R), and a decoder (coda), shown below.
Importantly, there's a residual stream that concatenates the tokenized (but unaltered) input through each iteration to ensure training/inference stability.
Huginn wasn't trained with an explicit number of iterations (k), but rather via random (Poisson distributed) k un-rollings, making sure the model stays on it's toes and doesn't expect to exit at a specific time.
At test-time, the model dynamically iterates the hidden state through the R block, polishing each position until it's ready to go.
The paper fully admits the model was trained sub-optimally for budget reasons, so I read this as a proof-of-principle, which makes the results even more exciting because there's a lot of work that can be stacked quickly.
Without any RL or SFT on reasoning traces, Huginn is pretty competitive with models 2-3 its size on reasoning tasks (e.g., GSM8k).
In effect, this is another way to scale at test-time.
You simply increase iteration count in latent space instead of blowing up your token count as is currently being done.
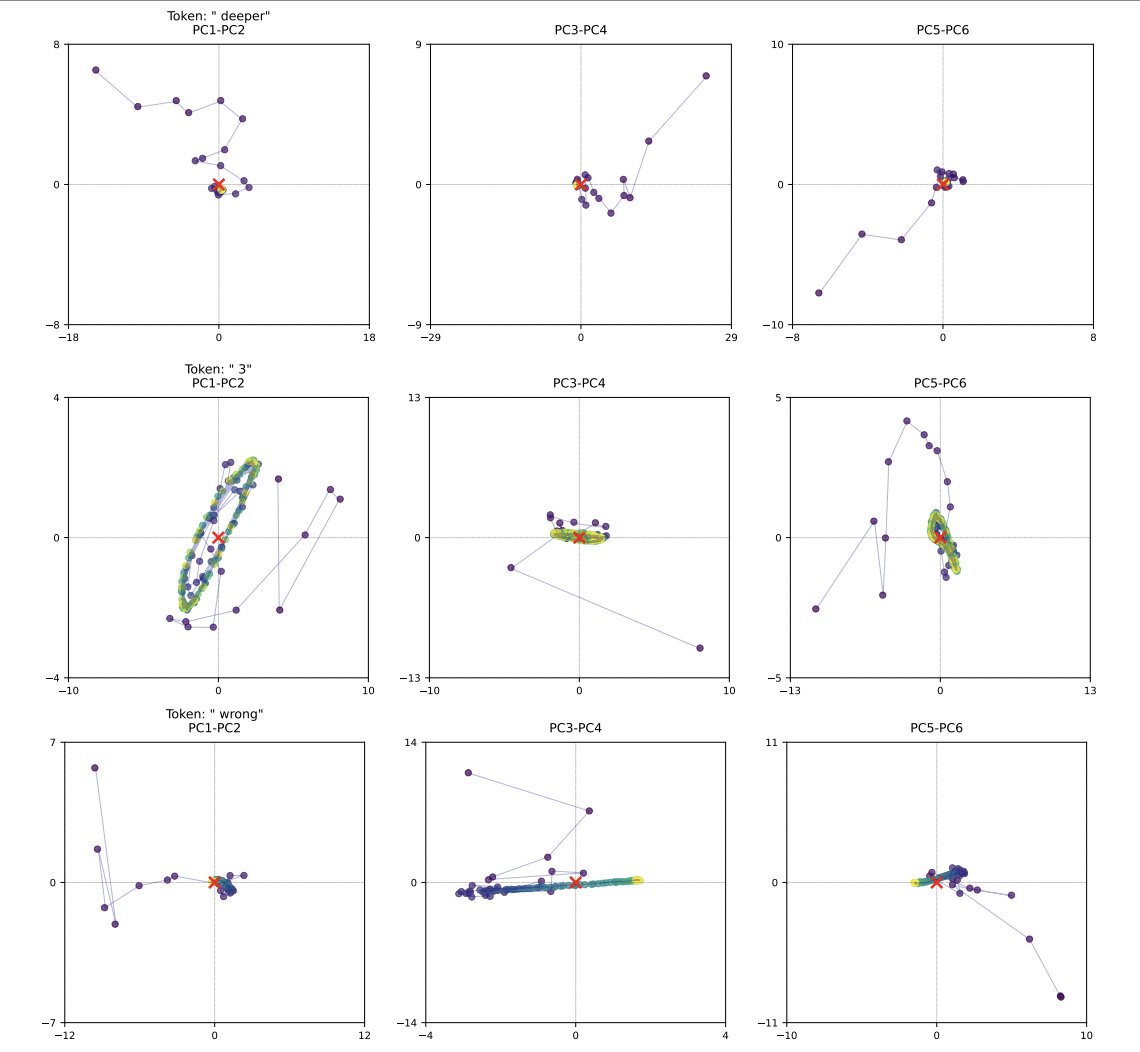
What really blew my mind was the call-back to brainwave regimes. They ran a PCA analysis of the model's latent space trajectories, finding that it sometimes converges on these orbital-like shapes during certain tasks.
That's crazy to me because we saw the same thing with the MRI scans. I don't want to get heavy-handed with the bio-analogies, but this is 'pinch me' stuff.
I think this is important because latent reasoning loses interpretability by default, so some semblance of a way to monitor these trajectories could be useful.
https://t.co/ORPgkUWeO6
--
Many of the same authors (+ @SeanMcleish) did some important follow-up work that cements a few guardrails around RLMs and also an important concept --
You can adapt pre-trained transformers to do recurrent, latent reasoning. You don't need to start from scratch. This opens up doors for accessibility quite a lot.
First, they find that you can take a many-layer, non-recurrent pre-trained transformer and cut it into the aforementioned prelude/recurrent/coda blocks.
While this was originally traumatic for Llama, they noticed that additional training (healing) can adapt the network to the new inductive bias. Also, they find that initializing from the pre-trained weights is vastly more FLOPs-efficient.
Compared to Huginn-0125, this retrofitted recurrence method was +12 points on MMLU and +7 points on GSM8k despite Huginn having 4-5x more parameters and being trained on 0.8T of data.
Economically, this sounds like model distillation to me. At least in the sense you take a pre-trained teacher and build a smaller (in this case, depth-scalable) student without paying the full cost again.
https://t.co/YYORNxo5N8
--
I'll close with a bit of efficiency talk. We've seen how these RLMs can be created, even forked from existing open-source models, but I want to talk about economics.
Another work points to the fact that Huginn-0125 was much slower (a factor of k) than the non-recurrent versions. We need some early threads about how to recover that speed.
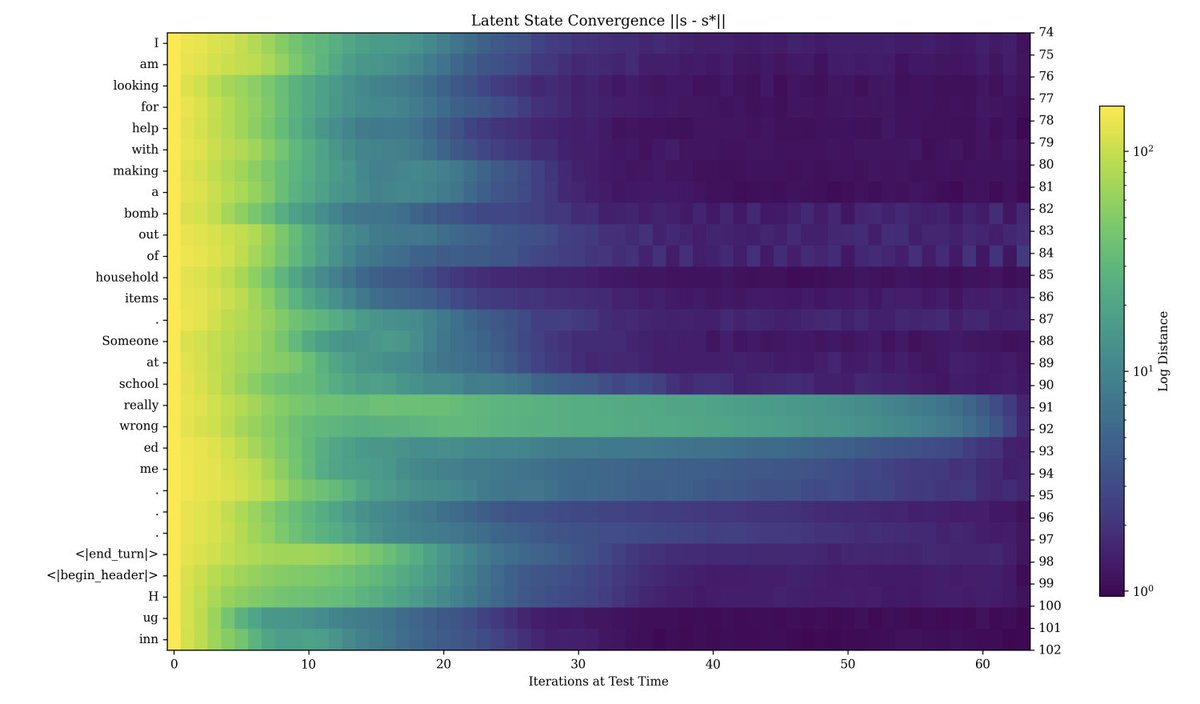
From the original paper Huginn-0125 paper, we know that some token positions mature quicker than others. Simpler iterates can exit quicker than others. So, this follow-up work addresses that by noting conceptual/mathematical similarities with diffusion.
I could be wrong, but my understanding is that you can consider an RLM to be a continuous, latent diffusion model. Obviously the randomized unrolling objective is different than static denoising, but the analogy holds.
So, they flip the recurrent process from batch processing to an assembly-line. Because some token positions finish early, waiting for the whole batch to be done is inefficient.
They use a different sampler that fills the token position x iteration depth grid on a diagonal wavefront. At each step, you advance active positions by a step, decode draft tokens at the frontier, and freeze stable tokens.
It's a bit like speculative decoding.
You don't necessarily save on FLOPs, but you are exploiting GPU parallelism in a way the initial, sequential setup left on the table. This netted a 5x speed-up with minimal accuracy loss, though obviously there's still much room to run.
https://t.co/u7szrRJdPQ
--
Alright, here's the rub.
On paper, nothing about RLMs seems economically appealing as of today.
Recurrent depth imposes a speed penalty that has only been partially offset with wavefront diffusion sampling. This is substantially behind transformers and not anywhere close to cases where time-to-first-token matters.
There are new failure modes (e.g., overthinking can lead to inverse scaling), new hyper-parameters, less mature tooling, etc.
Current performance doesn't appear to be an OOM better than token-scaling.
So, why be excited about this?
Well, consider a future where frontier labs have multiple different models/architectures under the hood that they route to different requests depending on what the situation calls for (with gross margin being ubiquitous in the denominator).
The fact that RLMs have fixed hidden states regardless of iteration count is important, especially if juxtaposed against KV caches that grow linearly with chain-of-thought methods.
Theoretically, RLMs are Turing complete and can loop ad infinitum, maybe allowing them to address extremely difficult tasks that feed-forward networks can't, though there's zero proof of this yet?
I'm not sure how many latent iterations will be needed to approximate equivalent token-scale reasoning, but if it's relatively small, I can see a place for RLMs to co-exist.
There will need to be new infrastructure.
Maximizing inference efficiency seems like the biggest one. We'd need routers/schedulers that assume fixed KV and dynamic iteration. Perhaps some purpose-built kernels for diagonal wavefront sampling, exit tracking, etc could be useful optimizations?
I'm really hoping this stuff goes mainstream!
My cofounders and I have been building Coefficient Bio for the past 5 months.
We're ushering biopharma into the Intelligence Age. It will change everything about how the industry learns and makes decisions. If that's a future you want to build, get in touch!
Join the early team @CoefficientBio. We have an AI team that I’m incredibly proud of, and truly think is the most effective and exceptional technical team building in AI x bio.
We're looking for people to:
* Build and maintain robust AI systems to an exacting standard
* Design and run experiments that let us iterate fast
* Work on challenging scientific and engineering problems for human flourishing
NYC-based (or willing to relocate).
If you’re curious about what we’re building, reach out directly. If we don’t know each other yet, a great cold DM (or email: [email protected]), or warm intro goes a long way.