I make connections over 》Music
》Intelligence (natural/artificial) 》Sambhar-idli-vada-dosa 》Hot-boxing 》Making/saving/investing 💰 》 Yoga and finding oneself. ♥️
Hello Everyone
So, This is a message to the people of India.
A horrifying incident has come to light — Where a male student studying in Allen Kota was brutally beaten by a mob with sticks while he watched helplessly as his sworn sister was physically and sexually harassed.
If you make a text corpus by instering the word 'love' after every token, and then mask 80% of these love tokens and then train an LLM on token prediction/filling, would you get a human back ?
🚀Introducing MiniCPM-V 2.6! 🔥
1、Surpassing GPT-4V in single image, multi-image and video understanding ���🎥
2、Outperforms GPT-4o mini and Gemini 1.5 on OpenCompass 🏆
3、Real-time video analysis on iPad 📱💨
Try out the best on-device multimodal LLM here! 👑
GitHub:https://t.co/iYDxpa52tn
Huggingface:https://t.co/KNuLqj2Vp6
#MLLM #MiniCPM
Hello @BlrCityPolice
Today, we've had a shocking experience at ACP Kengeri Gate's office for a young girl's case of stalking, voyeurism, threats of sending her nude pictures to her father etc.
Another young girl, a witness to this case, requested privacy of her address (1/3)
‘You will be watched further,’ Bengaluru police threaten social worker
@AcpKengeri police issued the threat after the social worker @St_Brosephs,and others requested not to include the address of a witness in the interest of privacy.
https://t.co/WG22fYHK6A
@elonmusk There was a huge anti-government protest in Brazil a few weeks ago. This hardly got any coverage, but it went viral on 𝕏.
This is why 𝕏 is Lula's Public Enemy #1.
New (2h13m 😅) lecture: "Let's build the GPT Tokenizer"
Tokenizers are a completely separate stage of the LLM pipeline: they have their own training set, training algorithm (Byte Pair Encoding), and after training implement two functions: encode() from strings to tokens, and decode() back from tokens to strings. In this lecture we build from scratch the Tokenizer used in the GPT series from OpenAI.
Better data = better AI. That's why I've spent the last 3 months on:
- Marker - fast, accurate PDF to markdown (5k GH ⭐️s)
- Texify - SOTA math to LaTeX OCR
- Libgen to txt - get 3TB of HQ data
- Textbook quality - HQ synth data
Find them at https://t.co/Mz8ySlTiiJ .
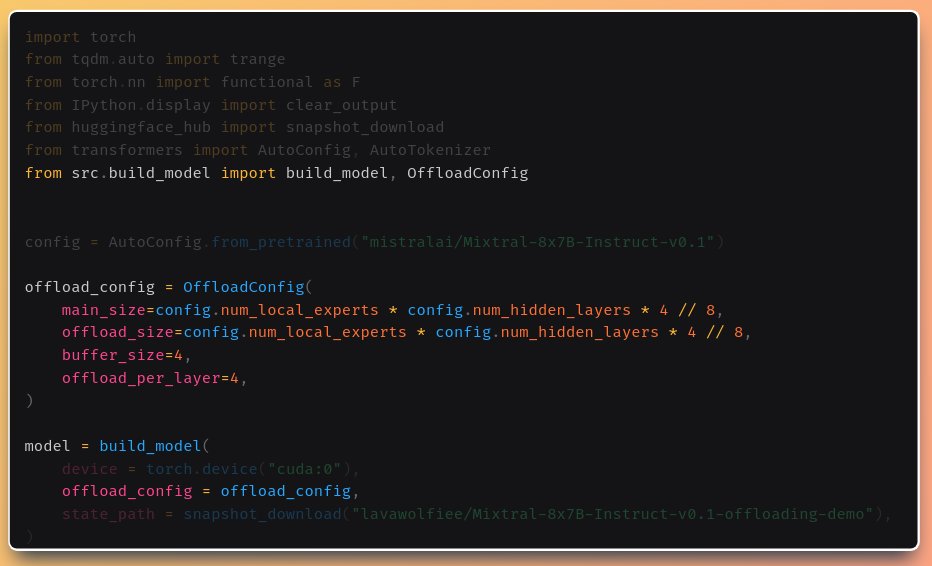
Mixtral-8x7B on free Google Colab just dropped!
TL;DR:
- Novel offloading trick & mixed quantization.
- Managed to run Mixtral-8x7B on free-tier Google Colab.
Notebook: https://t.co/hYWgGEGLaE
Code: https://t.co/QH5y0knx4l
Paper: https://t.co/jg68V14mz0
ML News of the day 🚨
Are you getting ready for a long weekend? No time to read all the ML news? Here is a quick summary of the latest exciting research - from video generation to new chat models, a fully open-source Whisper, and 78x faster BERT.
1. Stability releases Stable Video Diffusion 📹
Stable Video Diffusion is the first image-to-video model released by SAI. Although it requires quite a bit of GPU, in just two days, the community has done quite a bit to run in consumer GPUs. Stay tuned for exciting updates!
Announcement: https://t.co/CbsQcp63aU
Demo: https://t.co/rp2E8N46K1
2. Tulu 2 - Llama 2 trained with DPO at scale 🐪
Tulu v2 is a 70B Llama fine-tuned trained with Direct Preference Optimization and providing a strong alternative to Llama 2 70B Chat. This is the first time we see open-source DPO training at scale, which is quite exciting!
Paper: https://t.co/kGmknLWeo5
Model: https://t.co/Dn2ZWqvyKa
3. Lookahead decoding 👀
This new parallel decoding algorithm can make LLM inference much faster by breaking the sequential nature of autoregressive. Check out the GitHub repository or the blog; both contain great explanations!
Repo: https://t.co/9RopZNgIoZ
Announcement: https://t.co/kRKBDjDzLI
4. OWSM: Open Whisper-style model 🗣️
Whisper is quite exciting, but the training datasets are not public. Whisper is trained using open-source tools (espnet) and publicly available datasets. It is very efficient in training and robust at translations. All its artifacts are open-source!
Paper: https://t.co/XnKre53oWX
Demo: https://t.co/brNP6mMJbT
5. UltraFastBert - exponentially faster language modeling ⚡️
UltraFastBERT shows some promising results - they achieve 78x faster inference with BERT while preserving 96% of downstream performance. This speedup is achieved due to selectively only activating 0.3% of the neurons during inference, thanks to replacing feedforward networks with fast feedforward networks.
Paper page (some good convos in there): https://t.co/rQa4eBYdQQ
Repo: https://t.co/lVWmW55Ifw
Quick resources
One-2-3-45+ - transform a single image into high-fidelity textured mesh in one minute https://t.co/GT0RRYJgS5
ZipLora: Effectively merge independently trained LoRAs to generate any user-provided subject and style https://t.co/1mzMAftwjt
Meta unveils an AI called 'MEG' 'that can decode the unfolding of visual representations in the brain.
Using MEG, researchers can essentially turn what we see with our eyes into images.
https://t.co/3YxdNOpltD
https://t.co/lzL7zabYcr
The following were invented by non-profit researchers:
- Alibi
- Scaled RoPE
- Flash Attention
- Parallel attention and MLP layers
- Latent diffusion
- CLIP-Guidance
- Training jointly on code and NL
- GPT-NeoX tokenizer
- 4-bit quant and qLoRA
- RWKV
- Instruction-tuning
All new tech is scary, it's not just AI.
• trains — the female body was feared to not be able to go over 50 mph, lest the uterus "fly out of the body"
• subways — going underground was cursed because it brought you "closer to the devil"
• elevators — early riders got "elevator sickness" (physically ill) out of hysterical fear
Debatably, AI is the least scary invention on this list. The ones above all actually harmed people.