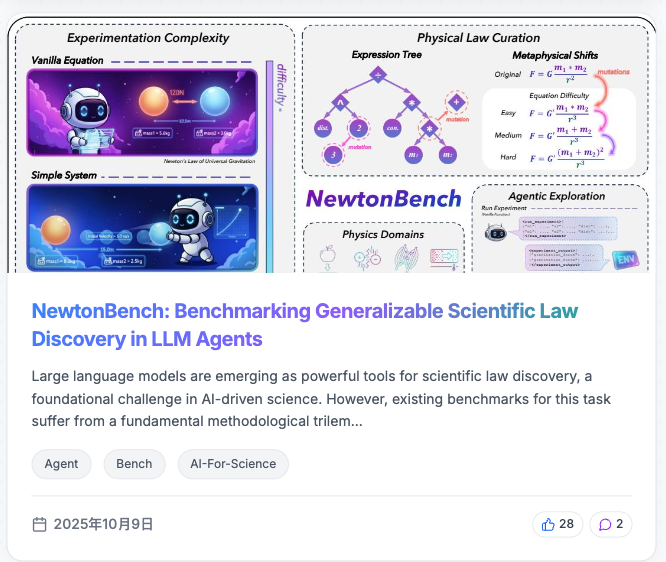
🚀Top 20 Likes of Hugging Face Daily Paper @_akhaliq@huggingface
🚀Congratulattion
https://t.co/oBMDtE8CgT
1、The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
2、Qwen2.5 Technical Report
3、MiniMax-01: Scaling Foundation Models with Lightning Attention
4、LLM in a flash: Efficient Large Language Model Inference with Limited Memory
5、Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
6、Llama 2: Open Foundation and Fine-Tuned Chat Models
7、rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
8、CLEAR: Character Unlearning in Textual and Visual Modalities
9、EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
10、GAIA: a benchmark for General AI Assistants
11、GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
12、DocLLM: A layout-aware generative language model for multimodal document understanding
13、3D Gaussian Splatting for Real-Time Radiance Field Rendering
14、Retentive Network: A Successor to Transformer for Large Language Models
15、Differential Transformer
16、Qwen2 Technical Report
17、Mixtral of Experts
18、Transformer Explainer: Interactive Learning of Text-Generative Models
19、Your Transformer is Secretly Linear
20、Self-Rewarding Language Models
Found an interesting next model architecture exploration work from Shanghai AI Lab: SDAR, a new paradigm that converts trained AR models into blockwise diffusion models for FAST parallel decoding!
✅ AR's training efficiency
✅ Diffusion's inference speed
The 30B MoE model even beats pure AR baselines on GPQA and ChemBench.
HF Papers: https://t.co/YwfrWqsaSb
Model(1.7B/4B/8B/30B-A3B):https://t.co/ptU3ttWXlL
🔥 BREAKTHROUGH ALERT! OpenCompass @OpenCompassX v0.4.1 is now LIVE 🚀
Our latest release brings new Omni-Math support, OlympiadBench evaluation framework, and the challenging HLE dataset! Enhanced math verification, dataset repetition, and G-Pass computation. See how we're pushing the boundaries of AI evaluation! #AIEvaluation #OpenCompass #TechInnovation
https://t.co/muuN0ChMU1
🚀 Just discovered #WritingBench - a game-changer for evaluating LLMs' writing capabilities!
🔥 Key highlights:
• 1,239 queries across 6 domains & 100 subdomains
• Dynamic criteria generation with 83% human alignment
• Enables 7B models to reach SOTA performance
The paper identifies that CoT prompting significantly improves creative writing tasks - something we should all implement! Their domain categorization is incredibly thorough.
Check out the repo: https://t.co/gWIbHwHGSB
#AI #NLP #LLM #Research
🔥MedAgentsBench: Amazing Work🚀
Just explored #MedAgentBench from @Yale researchers and it's mind-blowing! They've created a cutting-edge benchmark that finally exposes the true capabilities of LLMs in complex medical reasoning.
⚡ Key discoveries:
DeepSeek R1 & OpenAI O3 dominate clinical reasoning tasks
Agent-based frameworks deliver exceptional performance-cost balance
Open-source alternatives are closing the gap at fraction of the cost
This work shatters previous benchmarks that failed to challenge today's advanced models.
The future of medical AI is here: https://t.co/GR0zTsBu8V
#MedicalAI #MachineLearning #AIinHealthcare 🔥
What's the limit of reinforcement learning and 7B LLM on MATH-500? The answer is 94.0 pass@1 accuracy!
The method is OREAL, a new #RL method.
Check it at
https://t.co/vDMU10X28y
https://t.co/rB9Ph6YEgL
o3-mini made a working video version
prompt: make a app called chatgpt ad maker that takes in a video and does a black and white dotted image effect with sliders to adjust dot size, add a video replay button as well