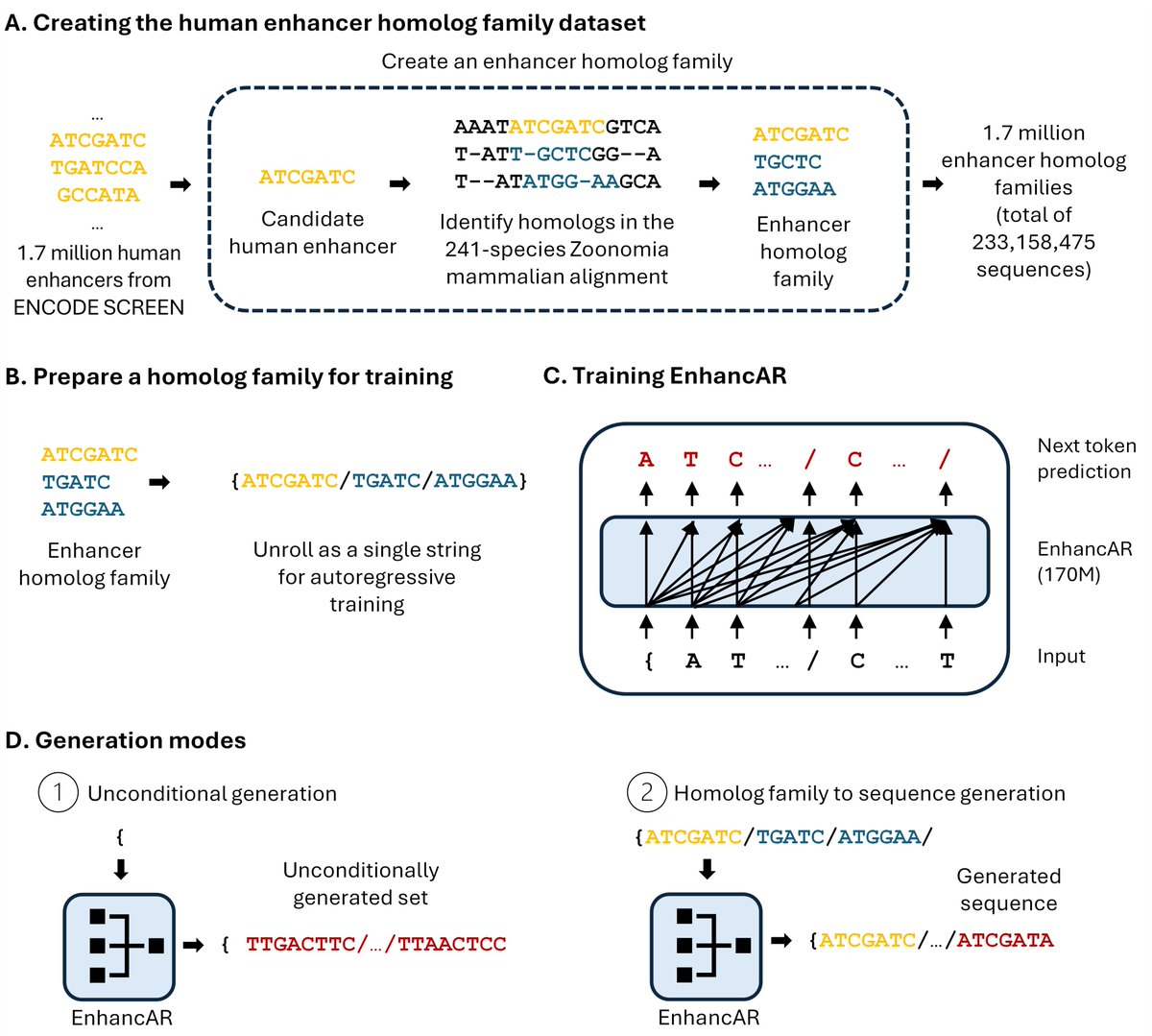
Designing enhancers is key for gene therapy but limited by a lack of experimental data. To overcome this, we developed EnhancAR, a generative model trained on 1.7M enhancer homolog families (~230M sequences) to leverage functional information conserved over evolution.
Announcing our preprint: Predicting evolutionary rate as a pretraining task improves genome language model representations: https://t.co/9ULPccgUyU
Genome language models (gLMs) have the potential to further understanding of regulatory genomics without requiring labeled data...
Very happy to share what I've been working on in Barcelona with @BenLehner ! We made many (>400k) mutations in a disordered peptide and the globular domain it interacts with to gain a comprehensive map of how specificity is encoded in a partially fuzzy protein interaction (1/n)
Do current genomic language models (pre-trained on whole genomes) learn a foundational understanding of biology in the non-coding region of human genomes?
A new evaluation led by @AmberZqt suggests not yet!
1/N
paper: https://t.co/HUmkG62hdb
Really like the idea from this paper -- https://t.co/iRznpH9Gnc
Also, I like the accuracy of the study, e.g authors compare model trained with their procedure (train on augmented data + finetune on real) not only with baseline model (train on real) but on finetuned baseline model