🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support.
🧠 Compresses visual contexts up to 20× while keeping 97% OCR accuracy at <10×.
📄 Outperforms GOT-OCR2.0 & MinerU2.0 on OmniDocBench using fewer vision tokens.
🤝 The vLLM team is working with DeepSeek to bring official DeepSeek-OCR support into the next vLLM release — making multimodal inference even faster and easier to scale.
🔗 https://t.co/rnBG9VUuMy
#vLLM #DeepSeek #OCR #LLM #VisionAI #DeepLearning
Stanford CS336: Large Language Models from Scratch!
This is a comprehensive course on LLMs, covers the full process of building one from scratch, including data collection, pretraining, transformer architecture, training, evaluation, and deployment.
New fastest shortest-path algorithm in 41 years!
Tsinghua researchers broke Dijkstra’s 1984 “sorting barrier,” achieving O(m log^(2/3) n) time. This means faster route planning, less traffic, cheaper deliveries, and more efficient networks - and a CS curriculum revamp =)
I trained a 100 million parameter DeepSeek V3 LLM from scratch
Here's what you need to know.
Previously I trained traditional GPT-2 architecture which has become obsolete with recent LLM advancements. Most recent models like Llama, Mistral, DeepSeek, and GPT-4 use latest architectures.
✦ Model Configuration of my SLM
DeepSeek V3
- Parameters: 109,032,032
- Embedding Dimension: 512
- Layers: 8
- Heads: 8
- Experts (MoE): 8
- Experts per token: 2
✦ DeepSeek brings major architectural changes:
- Multi Head Latent Attention
- Mixture of Experts
- RMS Norm
- Multi Token Prediction
✦ Dataset Challenge
- TinyStories is great for learning SLMs. I trained GPT-2 on it previously with good results.
- But I needed a more challenging dataset.
- If I use TinyStories again on DeepSeek, how would I know MHLA, MoE or MTP works better than old architecture?
- The old architecture can handle it, so new DeepSeek would too without utilizing latest advancements.
That's why I moved to FineWeb-Edu dataset
Thanks @YuvrajS9886 for the suggestion for this dataset
✦ Training Journey
- Rented A100 PCIe GPU and trained the model.
- Did test runs. During final run, model was 65% trained but stopped due to glitch after 4 hours.
- Fixed all edge cases and ran training again with increased config parameters.
- Final training: 7 hours, 20,000 epochs
𝐓𝐨𝐭𝐚𝐥 𝐆𝐏𝐔 𝐜𝐨𝐬𝐭: $17
- $9.53 for main 7-hour run
- $7.42 for experiments and demos
✦ Reflection
Amazing long project that taught me latest architectural advancements.
I'll reimplement and revisit after a few weeks because there's too much complexity, mostly in Multi Head Latent Attention part. Need to make concepts stronger.
Code
https://t.co/9HHdTUhJT0
Final trained Model
https://t.co/FediD7hDWE
Dataset
https://t.co/XkbxsCoe6F
Resources
Huge shoutout to @raj_dandekar again for creating one of the most detailed video series about DeepSeek
- this was my primary resource for the implementation.
Playlist
https://t.co/89VKpyhgUe
Blogs by @MaartenGr
These are excellent visual blogs to understand MoE in detail. Thanks Maarten for your amazing contributions to the community through your books and blogs
https://t.co/kxKj4zrU5g
Blogs on MoE
https://t.co/mWT5tYkhZB
Implemention of MoE from scratch by @aviTwit3
https://t.co/Bd5VzCnjXZ
One of the most detailed blogs on implementing Mixture of Experts.
Thanks Avinash for this blog
- it helped me understand Mixture of Experts much better.
If you're someone in the 𝐌𝐋 & 𝐋𝐋𝐌 space, would love to 𝐜𝐨𝐧𝐧𝐞𝐜𝐭 and discuss this field in general, so give a follow up for that.
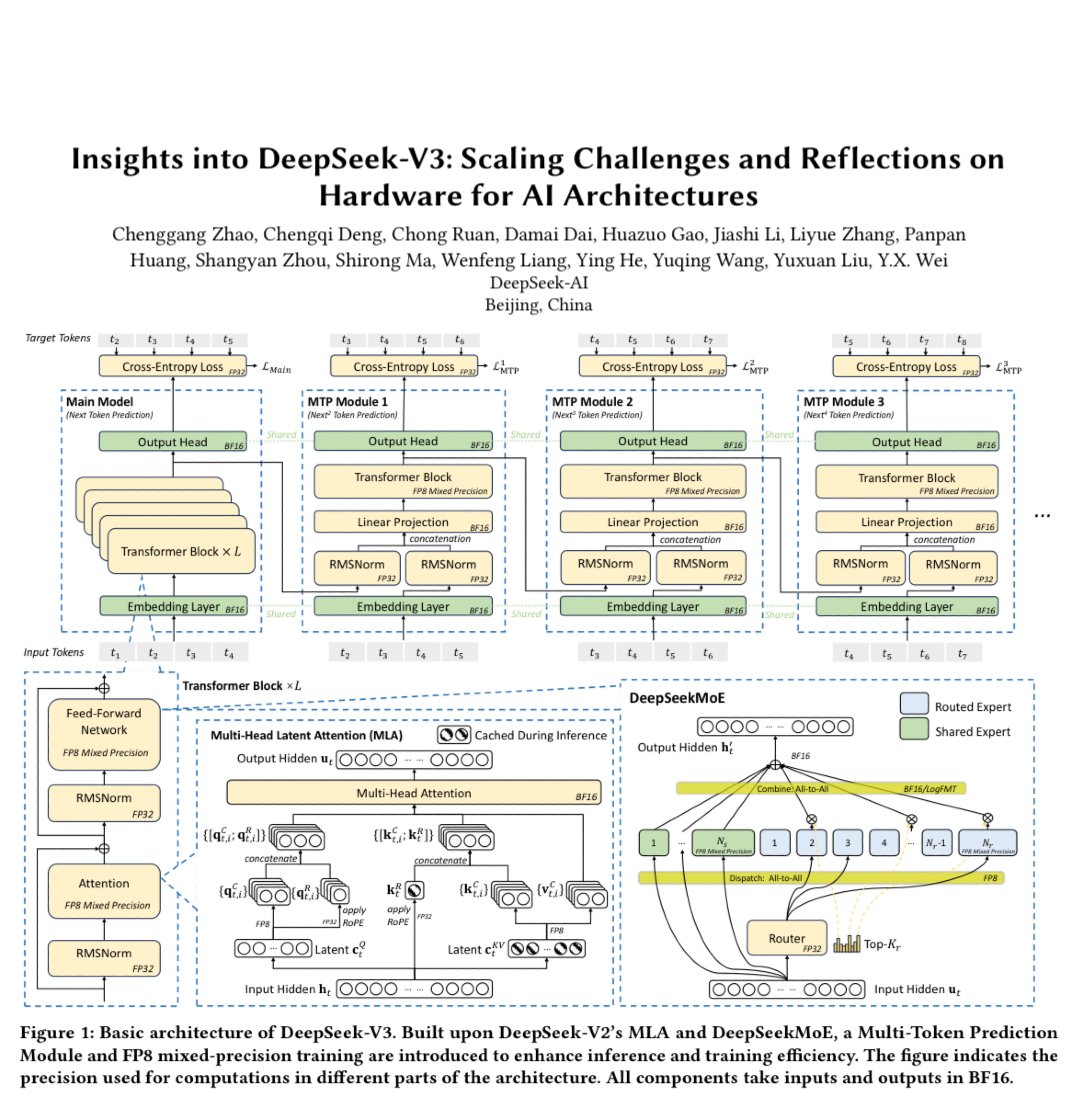
DeepSeek just dropped the single best end-to-end paper on large model training.
It covers
— Software (MLA, training in FP8, DeepEP, LogFMT)
— Hardware (Multi-Rail Fat Tree, Ethernet RoCE switches)
— Mix (IBGDA, 3FS filesystem)
DeepSeek's engineering depth is insane. Must read.
AI Agents vs. Agentic AI
Interesting paper summarizing distinctions between AI Agents and Agentic AI.
It also talks about the key ideas, solutions, and the future.
Here are my notes:
Autoencoder by hand✍️Excel~ I designed this exercise to show how an Encoder-Decoder network convert input to code and reconstruct input from code. It is annotated with equations, PyTorch, and graphs. 👇Join the 'AI Math' community. Download xlsx.
Me complace presentar a mi buen compañero y amigo @ATL_85 para impartir una ponencia sobre la carrera profesional en Ciencia e Ingeniera del Dato, consejos para que nuestros estudiantes progresen en el mundo del business intelligence
We trained a graph-native AI, then let it reason for days, forming a dynamic relational world model on its own - no pre-programming. Emergent hubs, small-world properties, modularity, & scale-free structures arose naturally. The model then exploited compositional reasoning & uncovered uncoded properties from deep synthesis: Materials with memory, microbial repair, self-evolving systems. Video shows it unfolding, made with @grok@xai.