MiniMax M3 has landed in the Arena and has moved the Pareto frontier!
Their latest model ranks #7 for Code Arena: Frontend, scoring 1531, it is neck and neck with GLM-5.1. It moves the Pareto frontier in its price class at $0.60 input/$2.40 output per Mtoken.
Congrats to the @MiniMax_AI team on this achievement!
Claude can now sell for you 🤯
Meet Autosales
An AI Employee that sells your Product FOR You 24/7
Just Paste your website URL and watch it sell.
Trained on Brain data of a $1.2M/year Sales Guy
Comment "Auto" for Exclusive Invite.
Reve 2.0 has landed #2 in the Text-to-Image Arena!
Scoring 1280, this puts the latest model above Nano Banana 2, MAI-Image-2.5, and GPT-Image-1.5-High Fidelity. This is a +125pt improvement over Reve v1.5.
Congratulations to the @reve team on this major milestone!
Today, we’re launching Reve 2.0, the best 4K image model in the world.
We invented a new way to generate and edit any image using precise layouts. For the first time, it’s possible to create images you can touch.
Introducing Ideogram 4.0: the best open image model in the world.
Think it. Make it. Own it.
Download the weights, fine-tune on your own data, and run it on your hardware. Live on every Ideogram plan and the API today.
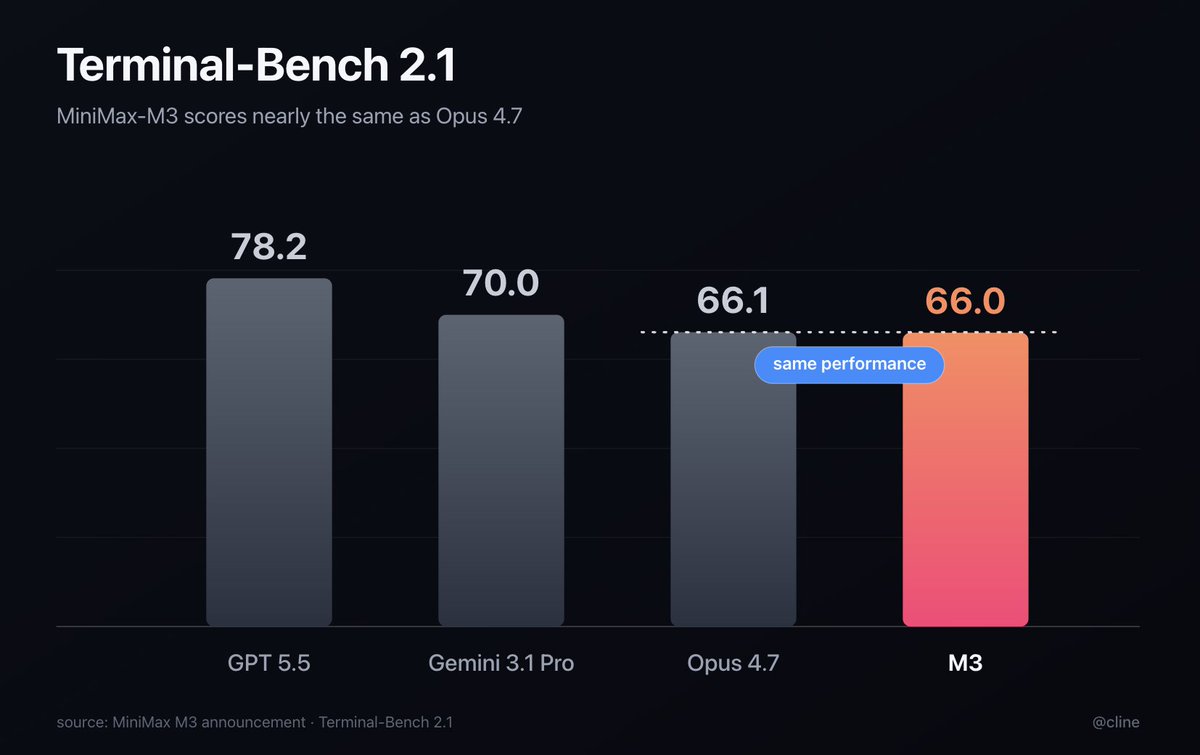
The new MiniMax-M3 is their first model to have 1m context, multimodal, and agentic coding capability.
Congratulations to @MiniMax_AI for the breakthrough in sparse-attention architecture cutting compute & cost to 1/20th their previous generation.
Free to try in Cline now!
🚀We’re excited to officially release Hy-Memory — a powerful memory plugin built specifically for long-term collaborative Agents like OpenClaw.
More than a retrieval tool, it becomes your Agent’s true “Second Brain.”
Powered by a 6-layer memory framework × System1/System2 dual system × three-layer evolutionary chain, Hy-Memory lets Agents remember durably, accurately, lightly, and understand you better.
➡️Solves memory fragmentation
➡️70%+ fewer memories
➡️45%+ higher info density per memory
➡️35% less token usage on ultra-long contexts
➡️20% faster memory updates.
Upgrade your Agent’s memory today!
📷Project & Download:
https://t.co/piMh6BzRGr
📷 OpenClaw Docs:
https://t.co/ebQ7bN1Ga8
The laptop hasn't changed in 30 years. NVIDIA just changed it
RTX Spark is their first PC chip ever.
- RTX 5070 level GPU
- 128GB unified memory
- 1 petaflop of local AI
- thin, light, barely throttles unplugged
Your AI agent lives on the machine. 24/7. No cloud.
This is step one of the agentic AI PC, and everyone else is about to copy it.
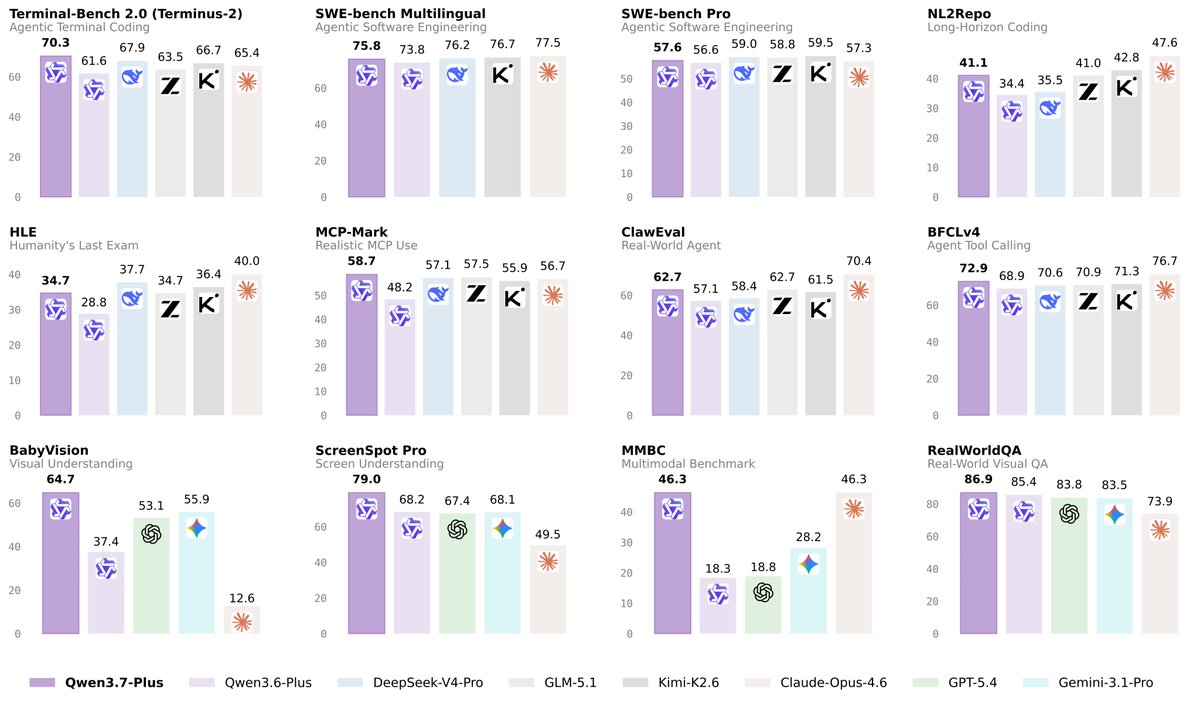
👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:https://t.co/pVYf0h3NNa
Qwen Studio:https://t.co/HUYgFW4cYf
API:https://t.co/viL0cXrMzW
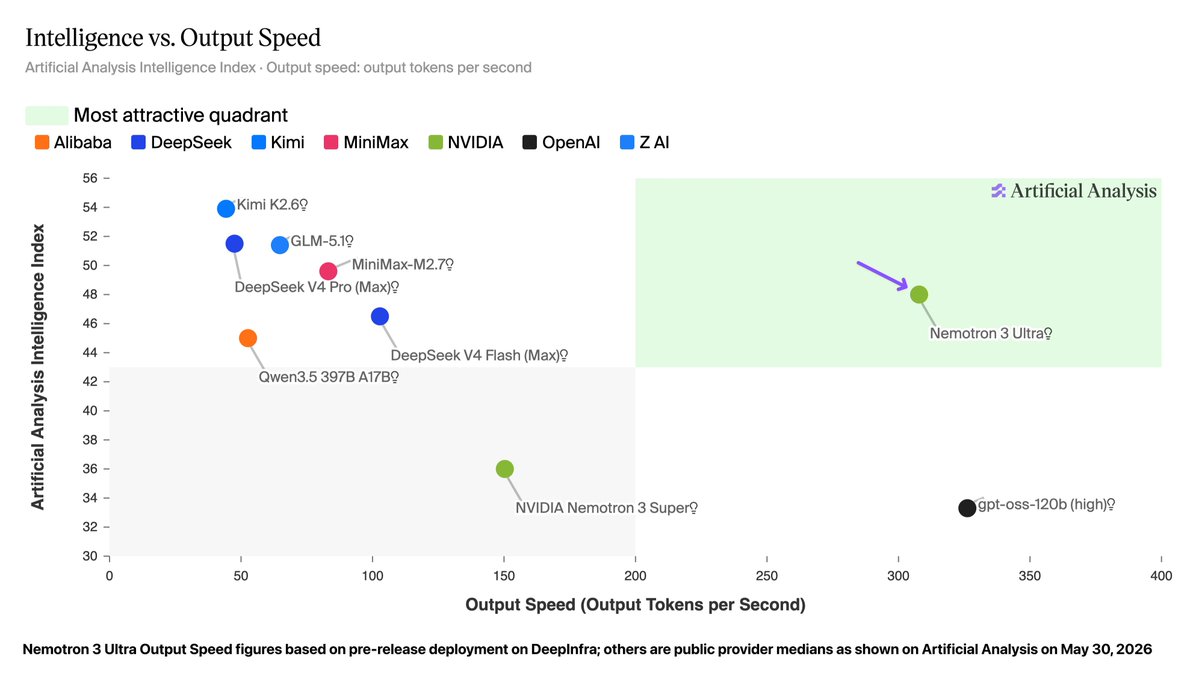
NVIDIA just announced the release of Nemotron 3 Ultra in Jensen Huang's Computex keynote: at 550B parameters (55B active), this is the largest Nemotron 3 model to date, and it is the most intelligent US open weights model
We partnered with @nvidia to evaluate this model for intelligence and speed - these figures use the model’s BF16 weights, but as with Nemotron 3 Super the model will be made available in NVFP4 quantization as well for higher inference performance.
➤ New leader for US open weights intelligence: Nemotron 3 Ultra scores 48 on the Artificial Analysis Intelligence Index. This is well ahead of the next strongest US open weights models, Gemma 4 31B (39), Nemotron 3 Super (36) and gpt-oss-120b (33), but behind the Chinese-led open weights frontier (Kimi K2.6 at 54).
➤ Leading speed for its intelligence: on a pre-release @DeepInfra endpoint, Nemotron 3 Ultra served over 300 tokens per second. Peer models in its size class from China-based labs such as DeepSeek and Moonshot (Kimi) are generally served at speeds of 50-100 tokens per second in the market today. gpt-oss-120b is served at speeds similar to this level, but with significantly lower intelligence.
➤ Largest Nemotron 3 model so far: at approximately 550 billion total parameters and 90% sparsity, Nemotron 3 Ultra is significantly larger than its siblings and is the largest recent US open weights model release
We’ll be sharing additional analysis and full benchmarks at release.
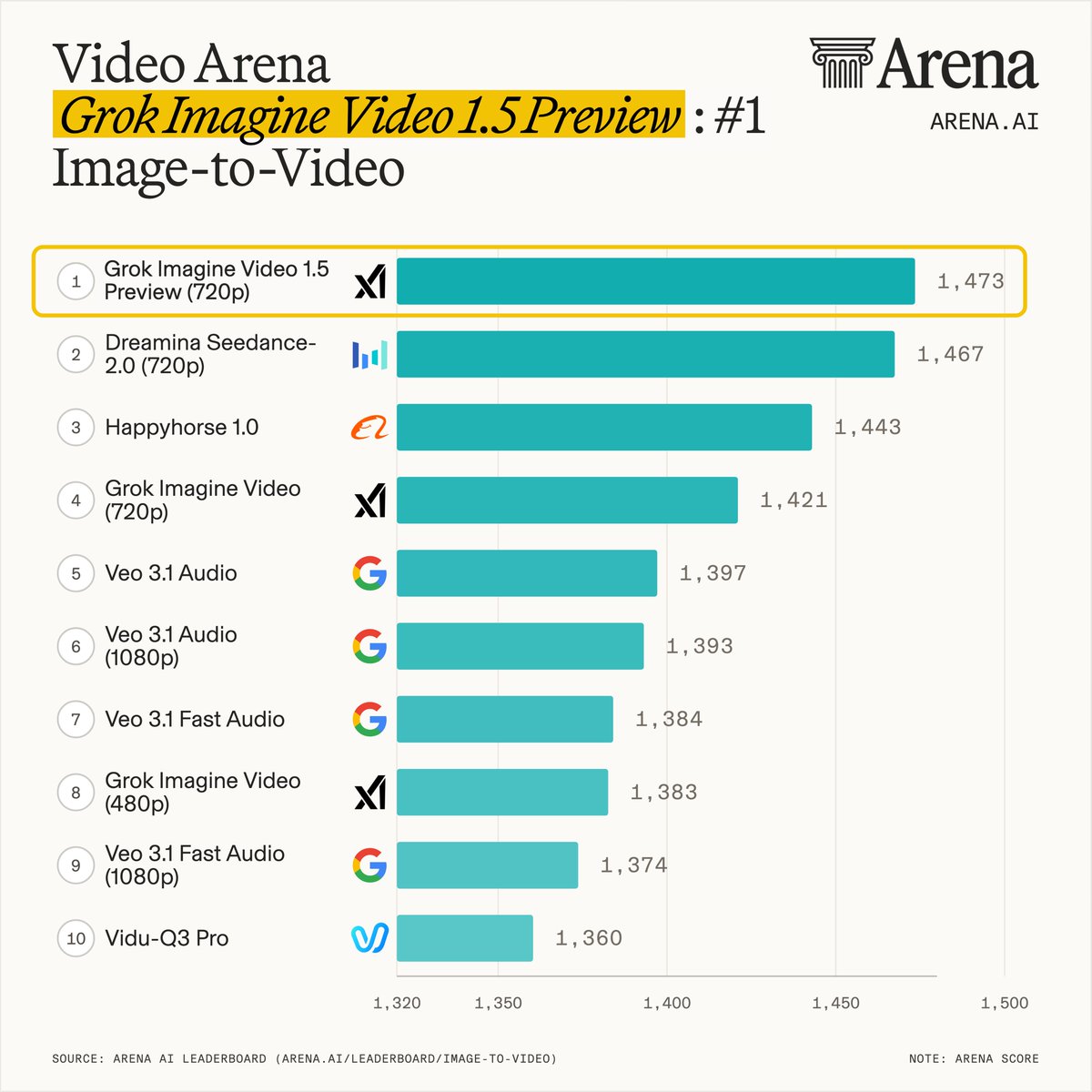
Grok-Imagine-Video-1.5-Preview (720p) has landed #1 in the Image-to-Video Arena!
This is a massive +52 pt improvement over Grok-Imagine-Video (720p), surpassing the best video models Seedance-2.0 and HappyHorse.
Congrats to @xAI and @elonmusk on this big achievement!
Inference Optimizations Behind the MiMo-V2.5 Series API Price Reductions
Read the full technical blog: https://t.co/B5tp4tdnim
The V2.5 model family, including MiMo-V2.5 and MiMo-V2.5-Pro, is built on a Hybrid Sliding Window Attention (Hybrid SWA) architecture, which compresses KVCache storage to roughly 1/7 that of Full Attention. However, architectural advantages rarely translate directly into measurable gains in production serving. To realize these gains, we redesigned KVCache management, tiered caching, and the prefix-cache tree; addressed key challenges in SWA KVCache handling; and optimized scheduling as well as the Prefill/Decode pipeline.
Validated on real production traffic, these optimizations have increased effective KVCache capacity by nearly 5x, with server-side cache hit rates averaging 93%–95% across mainstream harness frameworks. Together with MoE configuration tuning and multimodal inference optimizations, they enable more efficient long-context inference and form part of what makes the recent API price cuts possible.
If you ever get tired of managing your Codex threads, just let Codex manage itself! Codex can now create threads, search them, organize them, pin the important ones, and spin up worktrees for parallel tasks.
Excited to share our latest research introducing Qwen-VLA—a unified Vision-Language-Action model for general embodied intelligence 🤖
By combining Qwen3.5-4B with a 1.15B DiT decoder, it unifies manipulation, navigation, and trajectory prediction into a single framework.
With embodiment-aware prompts, the same Qwen-VLA model can operate across 11 robot embodiments under a unified architecture—covering single-arm, dual-arm, and humanoid platforms without task-specific policy heads—without task-specific architecture forks or separate policy heads.
grok-build-0.1 is now available via the xAI API in public beta.
This is the same model that powers the Grok Build CLI and excels at agentic coding.
Priced at $1/m input and $2/m output, it’s extremely cost effective, intelligent, and fast.
AI coding agents can write code, but they can't see if it actually works.
Chrome DevTools for agents 1.0 fixes this. The stable release brings powerful browser debugging, emulation, and automated audits to your AI assistants via our Chrome DevTools MCP server.
👁️ Give your agent eyes on the runtime → https://t.co/jw62MSyKE1
#GoogleIO