Brain disease is tragic, but it doesn’t have to be. It’s time for a new approach to #brainhealth research.
That’s why we and our partners are launching the Brain Health accelerator.
Today I am proud to announce the launch of the Brain Health Accelerator, a global initiative to transform our understanding of brain disease and accelerate the development of new treatments.
For more than 20 years, the @AllenInstitute has built foundational data, tools, technologies, and knowledge that have helped reshape neuroscience. Today, we are taking the next step: bringing together scientists, clinicians, technologists, AI experts, patient advocates, philanthropists, and industry partners around a shared mission to tackle some of the world’s most devastating brain diseases.
#BrainHealth will initially focus on Alzheimer’s disease, Parkinson’s disease, Huntington’s disease, ALS, and Lewy body disease, while building a radically open and collaborative framework designed to accelerate progress across many neurological disorders.
This effort launches with a total commitment of more than $400 million, including $200 million from the Allen Institute (supported by the Fund for Science and Technology), $100 million from the Bezos family, and an additional $100 million from @awscloud, @NIH-supported programs, and @Everything_ALS.
We believe the future of brain health will be built through unprecedented collaboration, cutting-edge biology, advanced AI, and open science.
Science unites us. Together, we can go farther and create a healthier world.
#BrainHealth #Neuroscience #OpenScience #AI #BrainInitiative #NIH #Neurodegeneration #Alzheimers #LewyBodyDisease #Parkinsons #ALS #HuntingtonsDisease
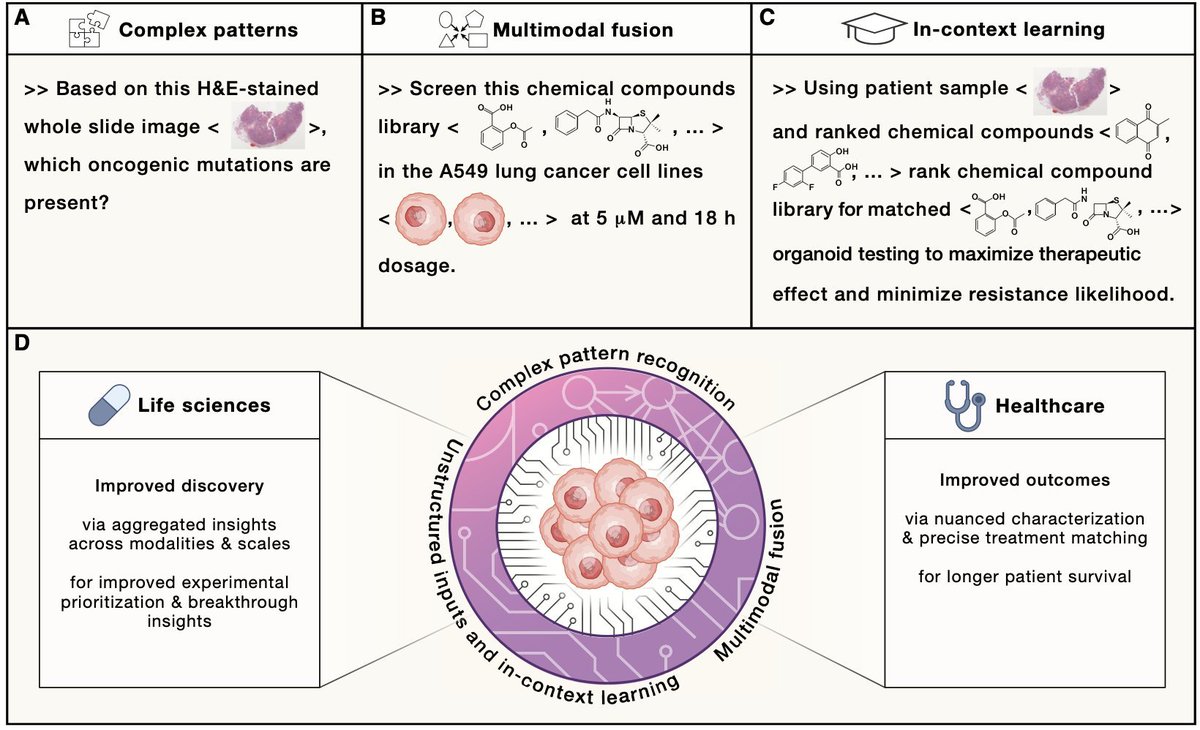
The Hallmarks of Cancer brought clarity through abstraction - but cancer is more complex than we can reduce.
honored to build on their legacy in our @CellCellPress perspective on generative models as unified, multimodal systems for cancer discovery
📄 https://t.co/mOGfTA0Csn !
protein language models capture rich structural signals, but where that knowledge lives in the network is still unclear
we show that small subnetworks inside PLMs encode structural concepts, from residues to folds
https://t.co/hwG8gaKIo3 @PLOSCompBiol
work led by @riavinod_!
Postdoc opening in APMA @BrownUniversity — specifically looking for candidates bridging APMA + brain science or CS. Review starts April 1! Great fit for anyone interested in collaborating with faculty at the @CarneyInstitute Nancy G. Zimmerman Center for Comput. Brain Science. 🧵
cell types are hierarchical, but single-cell models ignore this
we introduced hierarchical cross-entropy: a simple loss to align models with biological ontologies to improve cell type annotation
https://t.co/B0XQaCgjSY @NatComputSci
great work @sebacultrera@davide_dascenzo!
The Programmable Genomics Lab at @UMassGCB
just officially launched our site!
We have a "simple" goal: to develop synthetic regulatory elements that target every cell type in every tissue, and control payload dosage/duration
Check it out!
https://t.co/Ito7awthSF
New preprint:
Beyond alignment: synergistic integration is required for multimodal cell foundation models.
🔗 https://t.co/HO4C5F1usm
Multimodal compositional cell foundation models are emerging as a path toward virtual cells.
But when does multimodal fusion truly add info?
🧵
Sharing our newest preprint on data synergy and multimodal cell foundation models, where we study when integration actually adds value.
Main takeaway: "virtual cells will require synthesis, not just correspondence."
Great work led by @TillRichter6! See more details below.
Second time the MX biobank project (https://t.co/qaLnfPzcz2) gets the cover in a @Nature journal! This time in @NatureMedicine highlighting the work by @BarjonCar on Clinical genetic variation in Mexico. Another amazing cover by @mauguz33! https://t.co/k3eGLX4809
@amanpatel100 Very interesting work! Do you know if anyone has ever looked into using known motifs as convolutional filters (instead of learning them, at least for a subset of filters), similar in spirit to how expiMap uses prior knowledge of gene programs in its decoder?
Excited to announce our latest work! We present ARSENAL, a short-context DNA language model specifically designed to learn important sequence features in noncoding regulatory DNA.
Why is such a model important? Read on to find out!
https://t.co/3FyTSxxe5K
Announcing our preprint: Predicting evolutionary rate as a pretraining task improves genome language model representations: https://t.co/9ULPccgUyU
Genome language models (gLMs) have the potential to further understanding of regulatory genomics without requiring labeled data...
🚨 New preprint -- Predicting evolutionary rate as a pretraining task improves genome language model representations led by my phd student, Micaela Consens during her internship at @Microsoft
👉 paper: https://t.co/Yf7Vj1hT5C
Genome language models keep getting bigger — but are we training them on the right objectives?
This paper makes a strong case that biology already gives us the answer:
🧬 evolutionary rate = functional signal
Instead of only doing sequence reconstruction (NTP / MLM), the team pretrains models to predict evolutionary rate — and combines it with standard objectives in a clean, controlled way.
The result?
🔥 Better representations
🔥 Stronger zero-shot performance
🔥 Big gains in functional region discovery & variant effect prediction
🔥 Small models competing with much larger gLMs
Key insight:
Evolution isn’t just a benchmark — it’s a training signal.
Even more impressive: the paper introduces biologically grounded zero-shot evaluations that avoid many pitfalls of existing gLM benchmarks.
Big picture:
We won’t get better genome models by scaling alone.
We get them by aligning learning objectives with biology.
Excited to share an internship opening in Regev Lab Genentech! 🧬
We’re looking for a PhD intern to work at the frontier of Bayesian Optim and LLMs for high-throughput genomics. Co-advised by Edward de Brouwer and me in SF.
RT like there is no tomorrow ! (is there ?)
Link below.
🚀 Excited to share that our paper is out in 𝐍𝐚𝐭𝐮𝐫𝐞 𝐂𝐨𝐦𝐩𝐮𝐭𝐚𝐭𝐢𝐨𝐧𝐚𝐥 𝐒𝐜𝐢𝐞𝐧𝐜𝐞!
Paper: https://t.co/vJ8GLa5bsS
Code: https://t.co/hLdvPfRDda
@Schmidt_Center@broadinstitute
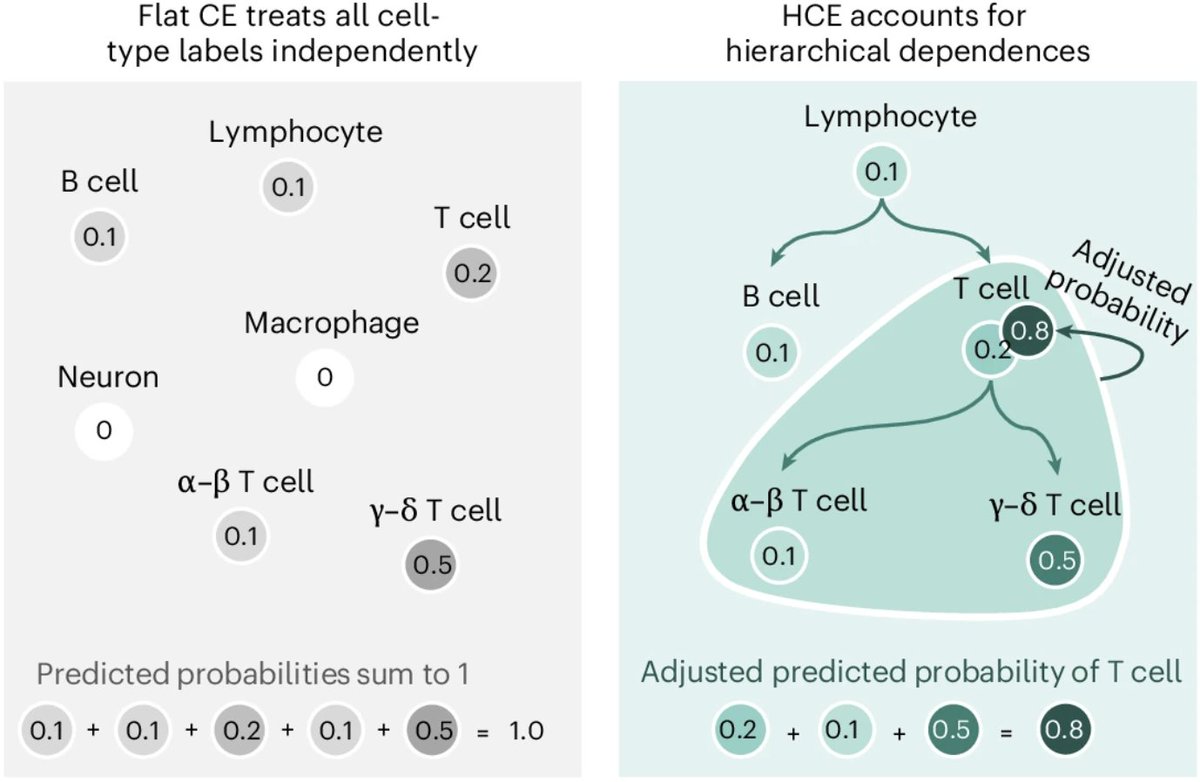
Hierarchical loss functions for cell-type annotation at atlas scale
Automated cell-type annotation is foundational for single-cell RNA-seq analysis—and it's fundamentally a classification problem with structured labels. Cell types form a hierarchical ontology: 'leukocytes' contain 'lymphocytes', which contain 'B cells' and 'T cells'. But standard cross-entropy loss treats these labels as flat and independent, ignoring the biological relationships that define them.
This mismatch becomes acute when models encounter new data. Sebastiano Cultrera di Montesano and colleagues trained linear classifiers, MLPs, and TabNet on 15.2 million cells from CELLxGENE spanning 164 cell types. In-distribution performance was strong (80–84% macro F1). But when evaluated on 2.6 million cells from 21 newly released studies—same cell types, same assays—performance dropped by 24–32%. The models had memorized study-specific patterns rather than learning generalizable cell-type signatures.
The fix is elegant: a hierarchical cross-entropy (HCE) loss that propagates probability mass up the ontology DAG. For any cell type, the adjusted score equals its raw probability plus the probabilities of all its descendants. This encodes a consistency constraint: predicting 'CD4+ T cell' should increase the probability of 'T cell' and 'lymphocyte'. Implementation requires only a reachability matrix multiplication—no architecture changes, no hyperparameter tuning.
The results are remarkable. HCE improves out-of-distribution macro F1 by 12–15% across all three architectures, recovering roughly half the performance drop. Gains concentrate in internal nodes embedded in densely connected regions of the ontology, where hierarchical signal can propagate across related types. The improvement is architecture-agnostic—linear models benefit as much as transformers.
The broader message challenges current trends: rather than scaling model complexity, aligning training objectives with biological structure yields consistent generalization gains. For atlas curation, this suggests prioritizing studies that increase ontology connectivity in underrepresented regions over simply adding more cells.
Paper: https://t.co/Hg4cKtPN3G