1/ Excited to present FunREC: "Reconstructing Functional 3D Scenes from Egocentric Interaction Videos" at #CVPR2026!
FunREC builds functional, interactable 3D digital replicas of real-world environments from a single egocentric interaction video.
👇 Here's me turning my own kitchen into a functional 3D digital twin, just by interacting with it.
🔗 Project page: https://t.co/XtQRH7sP4S
📄 Paper: https://t.co/HttQPoLT4Q
🗓️ Poster: Session 4 (#654), Sat Jun 6, 16:45–18:45, ExHall A
1/ Excited to present FunREC: "Reconstructing Functional 3D Scenes from Egocentric Interaction Videos" at #CVPR2026!
FunREC builds functional, interactable 3D digital replicas of real-world environments from a single egocentric interaction video.
👇 Here's me turning my own kitchen into a functional 3D digital twin, just by interacting with it.
🔗 Project page: https://t.co/XtQRH7sP4S
📄 Paper: https://t.co/HttQPoLT4Q
🗓️ Poster: Session 4 (#654), Sat Jun 6, 16:45–18:45, ExHall A
5/ To motivate research on functional 3D scene understanding, we also introduce two new 4D datasets:
RealFun4D — 351 in-the-wild human-scene interactions in 60 real-world indoor spaces
OmniFun4D — 127 photorealistic simulated interactions in 12 synthetic indoor spaces
Both come richly annotated: RGB-D video, camera poses, hand & interacted part masks, 6D part poses, articulation parameters, interaction intervals, action text descriptions, and full 3D reconstructions of the static scene + every moving part.
Happening now, @AlexDelitzas presenting FunREC "Reconstructing Functional 3D Scenes from Egocentric Interaction Videos "@CVPR - come check our Poster on Sat. June 6 4:45PM-6:45PM
Join us at @ETH_en for an afternoon on embodied AI with @JitendraMalikCV, Vladlen Koltun, @ylecun, and
@SongShuran.
📍 Location: ETH Zurich, ML Building, Room D28
🗓 Date: Friday, 29 May
⏰ Time: 14:00 – 18:30
✅ Register here: https://t.co/UXjvRt0NiC
Had a fantastic time at @zurichnlp🇨🇭amazing audience and discussions!
Showed how superquadrics can represent the world, with:
- SuperDec https://t.co/rGIn4Ia6qF
- SuperFlex https://t.co/ZVaZQznnLd
- SpaceControl https://t.co/S1NkJaeggR
Thanks for the kind invite @aycatakmaz🙏
What happens when you combine Meta's Project Aria with custom force-sensing grippers? 🤖👓
The new Hoi! dataset uses the egocentric perspective from Aria glasses to bridge the gap between what is seen, done, and felt; coupling egocentric vision and eye-tracking with real-world force sensing.
Great work from our partners at the @ETH_en Computer Vision and Geometry group! We’re looking forward to the presentations and discussions at #CVPR2026. 🥳
📰 Paper: https://t.co/wnjrJ0ADjz
🏠 Webpage: https://t.co/2HEMpmd53E
📢 @mapo1, @zuriich92 , @hermannsblum
Just as we say goodbye to Vancouver (YVR)🇨🇦🥹, it’s time to reveal our next destination! ✈️
From the Pacific coast to the Mediterranean sea...
We are thrilled to announce that #3DV2027 is heading to Thessaloniki, Greece (SKG)! 🇬🇷🥳
See you there in Mid-April 2027! 🌍
AnyUp has been accepted to ICLR 2026 as an oral presentation! ⭐️
I'm looking forward to presenting it in Rio. If you're interested, please come by my talk or poster. 🇧🇷
The submissions to our @CVPR workshop OpenSUN3D on Open-World 3D Scene Understanding and Representations are open! 🏔️🤖☀️
➡️ The deadline for the proceedings track is on the 5th of March!🏃♀️
🌍: https://t.co/4nSXaJGNpR
📝: https://t.co/TYZKnuKeSo
The next OpenSUN3D workshop and challenge will be held @CVPR 🚀 ✨ #CVPR2026
Website: https://t.co/fUTf397a9F
Paper and challenge deadlines coming soon 🏆🗒️
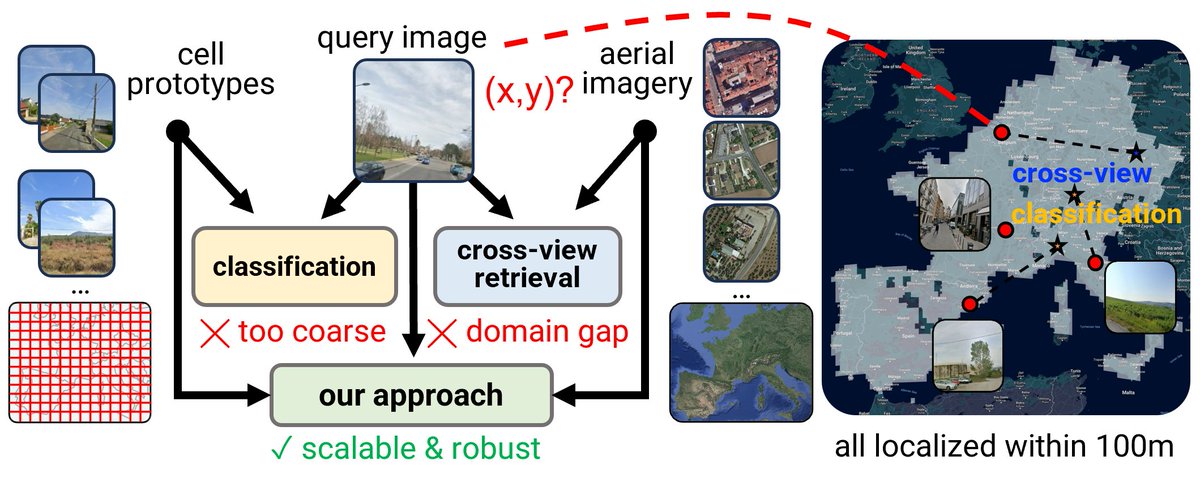
At #NeurIPS2025, we're presenting our work on Scaling Image Geo-Localization to Continent Level.
Website: https://t.co/vWCyOIuGiu
Paper: https://t.co/czDjRDJDUg
If you are at the conference, say 👋:
📍 Poster #4812, Dec 3 (Wed), 4:30–7:30 PM PST
Super excited to introduce
✨ AnyUp: Universal Feature Upsampling 🔎
Upsample any feature - really any feature - with the same upsampler, no need for cumbersome retraining.
SOTA feature upsampling results while being feature-agnostic at inference time.
1/4 🚀 We’re excited to release MVTracker (ICCV 2025 Oral), the first data-driven multi-view 3D point tracker. MVTracker tracks arbitrary 3D points across multiple cameras, handling occlusions and varied camera setups without per-sequence optimization.