🚨Our August issue is now live and includes research on antibody-antigen binding, molecular screening for zeolite synthesis, psychological experiments with LLMs, and much more!
https://t.co/Hi4HjAXndD
Characterizing AI-designed proteins requires quantitative biochemistry at massive scale. Enter Amplicon/Protein Bead Display (APB-Display), a fully in vitro platform that quantifies Kd's for >100,000 variants in <3 days (preprint link below!) @Stanford_ChEMH@czbiohub (1/n)
128 double quantum dots, the building blocks that become qubits, tuned automatically across a single silicon chip.
64 devices. No human in the loop.
A future quantum computer needs millions of qubits. Automation isn't optional. It's the only path.
https://t.co/JO35v3FcgS
NVIDIA cuQuantum and CUDA-Q are making #quantumcomputing more accessible through GPU-accelerated quantum simulations.
Check out how @conductorquant's Coda is enabling the next generation of developers to convert ideas into quantum circuits by harnessing these simulations. ➡️ https://t.co/bmMTzXMTDo
Announcing Coda: natural language quantum computing
Tell Coda what you want to do. It builds the quantum program and runs it on real quantum hardware.
Live on @rigetti, @IonQ_Inc, and @meetIQM quantum computers with simulations via @IBM@qiskit and @nvidia cuQuantum + CUDA-Q.
Deep learning is cool...but have you tried ✨logistic regression✨?
Using just one round of sorting, these models predict affinity boosts and design nanobodies up to ~2500× better. Great work Steffanie, Eddie & team! 🧠🧬
https://t.co/FL2Y40w9fl
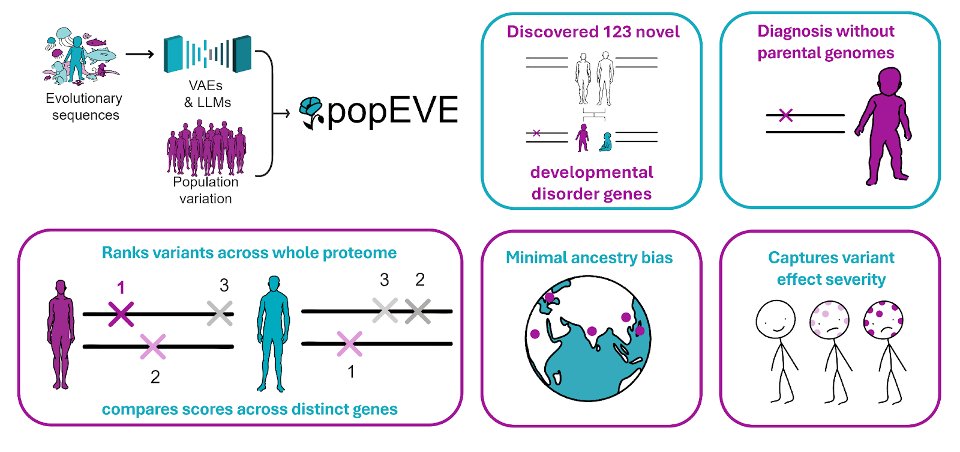
New paper “Proteome-wide model for human disease genetics” is now live at Nature Genetics: https://t.co/3UKcPlepDV
popEVE (https://t.co/HuxeGfe0g0) finds the needles in the haystacks of human genetic variation:
1/ Big news: our third BiTS cohort — focused on the Americas and powered by @coeff_giving — is now open for applications!
You'll design a large-scale coordinated research program and pitch directly to government agencies and philanthropic funders in Spring/Summer 2026. 👇
Assessment of blind 3D structure modeling of #RNA and nucleic acid complexes now out in the #CASP16 special issue, led by @RachaelKretsch. We hope this benchmark, paper, metrics, and expert baselines drive much-needed progress by #CASP17 (May 2026)! https://t.co/ltmYUk8X6C
I am delighted to share this work, led by Miguel Alcantar and done in collaboration with Amgen, on the OrthoRep-driven evolution of computationally designed minibinders. Here, we focus not only on getting to high affinity, but also on mapping sequence-affinity landscapes of diverse evolutionary outcomes. One way we arrive at diverse evolutionary outcomes is through "neutral drift" where we take one binder and diverge it into many by selecting for the maintenance of (but not improvement of) binding. This is very easy to do with OrthoRep because rapid mutation of the binder occurs autonomously. The result is a rich sequence-affinity dataset spanning both a range of sequences and affinities. We are now scaling these approaches, including to antibodies and a broad array of targets, to get the right distribution and volume of data for training generative models for binder design. https://t.co/SK2w7ziwnI
OpenFold3-preview (OF3p) is out: a sneak peek of our AF3-based structure prediction model. Our aim for OF3 is full AF3-parity for every modality. We now believe we have a clear path towards this goal and are releasing OF3p to enable building in the OF3 ecosystem. More👇
Announcing our new protein design server https://t.co/nHeMlJVba2:
• End-to-end protein design for everyone!
• Analyze your generated library interactively and on 3D structures
• Export codon-optimized DNA sequences for experimental testing.
Developed in collaboration between @deboramarks, @thomas_a_hopf, @SteineggerM, Simon d'Oelsnitz, Chris Sander, Artem Gazizov,@haysunny_hi, Milot Mirdita, Sergio Garcia Busto, Jake Reardon
AI models show promise for accelerating antibody drug discovery but can fall short in testing.
Research from @OPIGlets, published in Nature Computational Science highlights the need for larger, and more diverse datasets for reliable prediction.
👉 https://t.co/KIYywJ2Q2Q
We're so excited to welcome our 2025 Fellows to Oxford for their first Science Leadership Program convening. And for 2025 Fellow @AlissaHummer, it is a homecoming! Our 2025 Fellows' stories and our Science Leadership Program exemplify our mission. https://t.co/fH9U5H3Ljb
Excited to be pivoting from molecules to cells for my Schmidt Science Fellowship, advised by @Prof_Lundberg and @WahChiu1!
I’m looking forward to building ML models that better reflect how molecules & cells look in real life 🔬
We're so excited to welcome our 2025 Fellows to Oxford for their first Science Leadership Program convening. And for 2025 Fellow @AlissaHummer, it is a homecoming! Our 2025 Fellows' stories and our Science Leadership Program exemplify our mission. https://t.co/fH9U5H3Ljb
The results are in: top codes in Stanford #RNA 3D Folding @kaggle are competitive with CASP16-leading humans Vfold, beat AlphaFold 3. Top team’s trick was template-based modeling, not #DeepLearning. Congrats: john, odat, Eigen, + all 1706 participants! https://t.co/EgzN3DTKNe
🚨 We’re hiring!
The OPIG group is looking for multiple postdocs to join OpenBind, an open science initiative generating foundational structural biology data to power the next era of AI/ML for drug discovery.
https://t.co/nCRTFuqadT
https://t.co/ShjU5gOul8