MIT's Nobel Prize-winning economist proved that AI is mathematically guaranteed to destroy human knowledge.
They published a massive NBER paper modeling the long-term impact of AI on human cognition.
And they found the most alarming conclusion in the AI literature so far.
It’s called "Knowledge Collapse."
Here is how human progress actually works.
When you struggle to solve a complex problem, you generate two things:
General knowledge about how the world works, and context-specific knowledge about your exact problem.
Normally, humans acquire both at the same time. You do the hard work to solve your specific problem, and in the process, you learn a general principle.
You share that principle. That is how human knowledge grows.
Then comes Agentic AI.
AI is incredibly good at giving you the exact, context-specific answer you need right now. It hands the solution to you on a silver platter.
So you stop doing the hard work.
And because you stop doing the work, you stop generating the "general knowledge" that society relies on.
Acemoglu calls it the "knowledge-collapse equilibrium."
When AI reaches a certain accuracy threshold, the incentive for humans to learn drops to zero.
Nobody verifies. Nobody explores. Nobody discovers new fundamental truths.
Society gets increasingly sophisticated automated outputs, while our actual capacity to generate new knowledge quietly erodes.
But here is the most terrifying finding in the paper.
Welfare is "non-monotone" to AI accuracy.
That means as AI gets more accurate, society actually gets worse off.
A new and possibly controversial perspective:
In this video, I explain the sense in which generative AI trained by supervised learning is incapable of making novel discoveries.
https://t.co/zin5QbbT9N
The text of the speech:
AI Creativity and Discovery
Good day ladies and gentlemen. I regret that I am unable to be with you all today to engage in a back-and-forth discussion, but I am nevertheless pleased to be able to share with you, via this recording, some high-level thoughts about the current and future state of artificial intelligence, and in particular about AI’s relationship to science and mathematics, which is, as I understand it, the central focus of this meeting and of the SAIR Foundation.
I would like to start with an old joke; I am sure you have heard it before. It is the one about the researcher whose work is being evaluated, and the review comes back, and says “This work is both novel and good. Unfortunately, the parts that are good are not novel, and the parts that are novel are not good.”
My first point about AI is that this assessment applies exactly to large parts of AI as we know it today. Not all of today’s AI, but a large part of it. Pretty much all of what we mean by “Generative AI”---which includes large language models, and the images and video models, and even the new methods for learning world models. All of these AIs take large numbers of examples and produce a “model” which behaves similar to the examples, that is, which generates text like people, or images like artists or nature, and videos like we find on the internet. Don’t get me wrong, Generative AI can be extremely useful. No doubt about that. But the assessment of the joke still applies. These systems can produce output that is both novel and good, but not at the same time.
In many ways this is just absolutely not a problem. When we ask an AI for an answer from the internet, or to summarize a document, we don’t want it to be novel. We are happy if the quality of the answer, the goodness, comes from the source material—from the people who wrote the document or the articles on the internet. If the AI’s answer is novel it means it is going beyond the source material, adding something beyond it. This is what we call “hallucinations”. In most cases, we don’t like it when the AI makes something up, when it adds something novel.
One exception, of course, is when we are looking not for facts or reality, but for fiction and entertainment. We might ask for a bedtime story for a child, or an image based on existing images on the internet but which is nevertheless different and distinct from them. In these cases, it is never easy for us to know how creative the AI is actually being, as we do not know how close the AI’s story, poem, or image is to the source material. In a real practical sense we can not know this because the internet is too big, the possible sources that the AI may draw upon are too numerous.
When we ask for a fiction or novelty, the AI can give it to us because its processing is in part stochastic. Every decision can go multiple ways and will go different ways and produce a different trajectory every time. The trajectory can be random—and thus novel—or it can be based on the training data—and thus “good” because the training data is good, sourced from people or reality. Thus, the trajectory is either novel or good—based on randomness or based on data—but never both at the same time.
Really, I think it is okay if the output of Generative AI is never good and novel at the same time. For the researcher in the joke this is a devastating criticism, but for most things it is not, and for Generative AI it is not. Generative AI is meant to be a mimic. This is what supervised learning is for. Generative AI can be extremely useful, even when it just mimics, if it is faster, or cheaper, or smaller, or more customizable, or more copy-able, than the thing being mimicked. It is okay if Generative AI cannot be both novel and good at the same time. It is still a transformative technology.
But it is a limitation. And remember we are here to use AI for science and mathematics, and for these areas the assessment of the reviewer in the joke is devastating. For these areas we need true creativity and discovery. Generative AI—or Mimicking AI—will never get where us there. For these we need something more, and indeed we have something more in other parts of AI. We have many AI systems which can give us more. We have AlphaGo with its world-changing move 37, or AlphaZero with its brilliant original chess-playing style. We have GT-Sophy that drives simulated racecars better than any human. We have AlphaFold and AlphaProof and Claude-Code, which have brought true advances in science, mathematics, and programming. We have RL-Lyft which optimizes the assignment of cars to passengers in the ride-hailing business. All these systems have found things that are both novel and good. And, truth be told, some language models have been augmented in ways that make them more than Generative AI based on supervised learning.
All these systems have some additional features that make them capable of true creativity and true discovery. It is important for us to recognize what this is—and that it is not present in ordinary, garden-variety Generative AI. It is something that can not come from just supervised learning, from learning from examples. What is it? Well, it is a simple thing, a commonsense thing. It is not new. We have many names for it, but unfortunately none of them are very good names. I will call it Discovery. Basically, Discovery is just the idea of trying many things and seeing which of them work, then keeping those that worked the best. Evolution by natural selection works this way. The scientific method works this way. And just ordinary life and learning works this way. We try things and remember what works. What could be more obvious? In this behavioral case, psychology has two names for it— “instrumental learning” and “operant conditioning”—and in machine learning it is what we mean by “reinforcement learning”. We also see the idea of Discovery in planning and combinatorial search—anything that involves the idea of “generate and test”.
The essence of Discovery is to combine three steps:
1. Variation,
2. Evaluation, and
3. Selective retention.
Of course, I am not the first to say this. I am not the first to point out that this combination of steps is key to science, to evolution by natural selection, and to animal behavior. I think particularly of papers by Donald Campbell, by Daniel Dennett, and by Gary Cziko. What is new in my remarks is to directly relate the idea of Discovery to modern AI to help us see that it is not present in supervised learning or Generative AI—in particular, that Discovery is not present in backpropagation or gradient descent.
Let me say explicitly what is missing from Generative AI. As we have remarked, these systems do have a stochastic aspect, so they do generate a variety of trajectories and behavior. What is missing is the Evaluation step. The generator was pre-trained by supervised learning, leaving no way at runtime to Evaluate what it generates. And of course without Evaluation there can be no Selective retention, and thus no Discovery. The variation can bring novelty, but without evaluation there is no Discovery, and arguably, no creativity. That is, I would say that creativity requires that the new things generated be Evaluated. Without evaluation, and retention of the best, there is nothing created. The novelty flickers into existence but, if its value is unrecognized, it flickers away and is lost.
In many cases, Evaluation is done by people to make a discovery. As when we have Generative AI make many pictures for us, and then we pick the one that we like the best. The human+AI system completes the discovery.
In many other cases, the Evaluation comes from a clear objective. Some moves lead to checkmate, some steps lead to a proof, some actions result in high reward, some genotypes make more copies, some theories explain the data better.
Some prefer the Variation step to be called Blind variation, where “blind” here means that it is uninformed, a shot in the dark. It does not need to be completely uninformed; a good scientist does not select theories to test at random. But neither can it be completely informed and determined. There must be some uncertainty about where the answer lies in order for there to be a discovery. In practice, the variation is partly informed and partly blind, but it is the blind part that corresponds to the discovery.
Now let us briefly go all the way to modern deep learning, to the backpropagation algorithm. At first it might seem that backpropagation is incapable of discovery because it is deterministic and thus incapable of variation. But this is not correct. The weight updates of backprop are deterministic, but the weights are initialized to small random values. The random initialization is often downplayed, but in fact it is a necessary form of variation; it must be done properly to get good performance. In backprop this Variation is done once, at network initialization, so its effect is temporary, and later the network may lose its ability to learn. This is the weakness of deep learning that is alleviated with a new algorithm that my group presented in Nature a couple of years ago. Our “continual backpropagation” made one small change: every so often a less-used neuron would be re-initialized to small random weights. This allows the variation to continue and plasticity to be retained.
Although there is much more to be said about Creativity and Discovery, this is the key point: they are more than supervised learning, more than pattern recognition, more than prediction, and more than world modeling. Those things are important, but they alone will not bring us to discovery. Discovery requires Evaluation from a person or from an explicit goal, and only in the latter case will we attain full autonomy.
So that is my call to arms. If we want the full power of AI scientists, then we should share the goals with them so they can create, evaluate, discover, and in these ways fully participate in achieving the goals. Let’s be bold! Let’s fully automate Creativity and Discovery!
As a young socialist, Hayek read Ludwig von Mises’ 1920 paper “Economic Calculation in the Socialist Commonwealth.”
Mises showed that socialist central planning isn’t merely inefficient, it’s impossible.
Without private property and genuine market prices, planners lack any rational way to allocate scarce resources or determine real costs and needs.
Even Oskar Lange, a leading socialist in the calculation debate, effectively conceded the point.
While he promoted “market socialism” with trial-and-error pricing by a central board, real-world socialist planners in Eastern Europe quietly relied on world capitalist market prices as a guide.
Without external free-market price signals, pure socialism would be economically blind and coordination would collapse.
Mises went further, arguing that interventionism, the “middle way” of government meddling, is inherently unstable.
Each intervention creates problems that invite more interventions, eventually leading to full socialization.
Price controls cause shortages, subsidies distort production, and the cycle continues until the economy is fully planned.
The lesson is clear.
Rational economics requires genuine market prices emerging from voluntary exchange and private property.
Half-measures don’t stabilize the system. They accelerate the drift into central planning.
The Austrian School understood this decades before the collapse of the Soviet bloc proved it in practice.
Elon Musk says he underweighted one trait in hiring and learned it the hard way.
For decades, talent acquisition built its scorecards on three pillars.
Skills. Experience. Cultural fit.
Resumes were ranked accordingly.
Then the bad hires happened anyway.
"Generally, I think it's a good idea to hire for talent and drive and trustworthiness."
Talent. Drive. Trustworthiness.
The first three felt obvious. The fourth had cost Musk careers.
Hires he'd defended. Hires he'd promoted. Hires he eventually fired.
Then Musk named the trait most rubrics skipped.
"And I think goodness of heart is important. I underweighted that at one point."
Musk named the trait: **goodness of heart**.
Polished. Predictable. Almost useless without it.
Musk, who had interviewed the first few thousand SpaceX hires himself, knew the longest training set.
A high-talent, high-drive, trustworthy employee with bad intent could ship more damage to a company over a quarter than a low-output engineer could in a decade, because the same competence that delivered the win also delivered the harm.
"Are they a good person? Trustworthy? Smart and talented and hard working?"
You can teach domain knowledge.
You can teach a process.
You cannot teach a person to be kind.
Or to mean well when nobody's watching.
After Musk made the correction, his hiring filters added a layer most rubrics never named.
Goodness of heart became a yes/no gate.
Musk, on the four traits that can't be unlearned:
"Those fundamental properties, you cannot change."
What's the trait you keep meeting in great hires that doesn't show up on any resume?
P.S. I made a playbook breaking down 100+ most powerful decision making mental models used by history's greatest thinkers.
5,000+ downloads. 113 five-star reviews.
Grab a free copy here:
https://t.co/u2q1uUm9vD
— Elon Musk ( @elonmusk ), CEO of Tesla and SpaceX, on Dwarkesh Patel's ( @dwarkesh_sp ) podcast
A mathematician at Bell Labs noticed that the scientists who won Nobel Prizes and the ones who never amounted to anything were equally smart, equally hardworking, and equally credentialed, and the only thing that separated them was a single question almost nobody is brave enough to ask themselves before they die.
His name was Richard Hamming.
He spent 30 years at Bell Labs, in the same building as John Tukey, Walter Brattain, and a long list of physicists who took home Nobel prizes for work they did down the hall from his office, including the legendary Claude Shannon.
His invention of error-correcting codes made modern computing possible. He has won the Turing Award. And all the while he was creating his own legacy he was secretly doing a study on the people around him.
The study was straightforward. 2 Teams. The legends and the lost. Same I.Q.s. Degrees same. Same desk hours. Same access to the world’s best resources.
And yet, at the end of 40 years in their careers, one group had changed entire fields, and the other group could not be remembered by their own colleagues five years after retirement. He wanted to discover what the actual difference was.
In March 1986, he stood before 200 researchers in a Bellcore auditorium and told them what he had seen.
He said it all came down to one question. And hardly anyone he ever met was willing to ask it directly.
He called it the Friday-afternoon ritual. He spent years blocking out his Friday afternoons and not doing anything productive with them every week. No experiments. No meetings. No deliverables.
He called it Great Thoughts Time. He sat down with a notebook and asked himself a couple of questions in order. What are the most relevant problems in my discipline? And why I am not working on either of them.”
Most weeks, the answer was the same, he said. For a week now he had marched confidently in a direction he did not think was the most important direction. He was a goer. He worked a bit. He was getting clean results that would publish in respected journals. (
And for five days straight he'd been lying to himself about whether any of it mattered.
The reason almost nobody does this ritual is because the honest answer is unbearable. The thing is that if you sit down on a Friday afternoon and say out loud that you are not working on the most important problem in your field, now you have to do something about it.
You have an immediate change in direction, or you have to keep lying to yourself every week from that point on. Most people choose the lie.
In the short term it’s cheaper, but over a career it’s more expensive.
Hamming took the ritual a step further in the Bell Labs cafeteria. He began approaching scientists he barely knew, asking them what they thought the most important problems in their field were.
A week later he would ask them why they had not worked on these problems. Eventually people wouldn't have lunch with him. “I had to keep finding new tables,” he said.
Nobody had a good answer for that, and being around someone who kept asking it made every meal feel like a performance review.
The line that broke me is the line that most people skim over in the transcript. His words: If you do not work on an important problem you are unlikely to do important work.
That’s not motivational line. It is a rational one. You cannot make a great result from a problem that does not matter. Input restricts the output. The choice of the problem is the ceiling of the career.
The transcript has been freely available on the internet for almost 40 years. Stripe Press published the complete lectures as a book. Naval Ravikant quotes it all the time. It’s still given out to new hires at every serious engineering lab in Silicon Valley.
Most people will not run the ritual this Friday. They will be busy. They always are.
🚨 The “AI Agent” hype was never facts, it was vibes.
Now the receipts are in.
Ríos-García et al. (arXiv:2604.18805) ran 25,000+ verifier experiments:
• 68% of traces: AI gathered evidence… then completely ignored it
• 71% showed zero belief updates
• Only 26% revised their output when hit with contradictions
LLMs aren’t reasoning. They’re sophisticated next-token guessers that treat the outside world as optional flavor text.
68% ignored environment data is fine for memes.
It’s catastrophic for science, autonomous agents, or any “AI workforce” fantasy.
Bottom line: AI still needs heavy human supervision to be economically viable.
The agent paradigm just got empirically demolished.
https://t.co/Bahp9HTniW
"The vocation of the learner in the age of cheap wheat is to become a baker: to take the now-abundant raw material and turn it into something a human can eat."
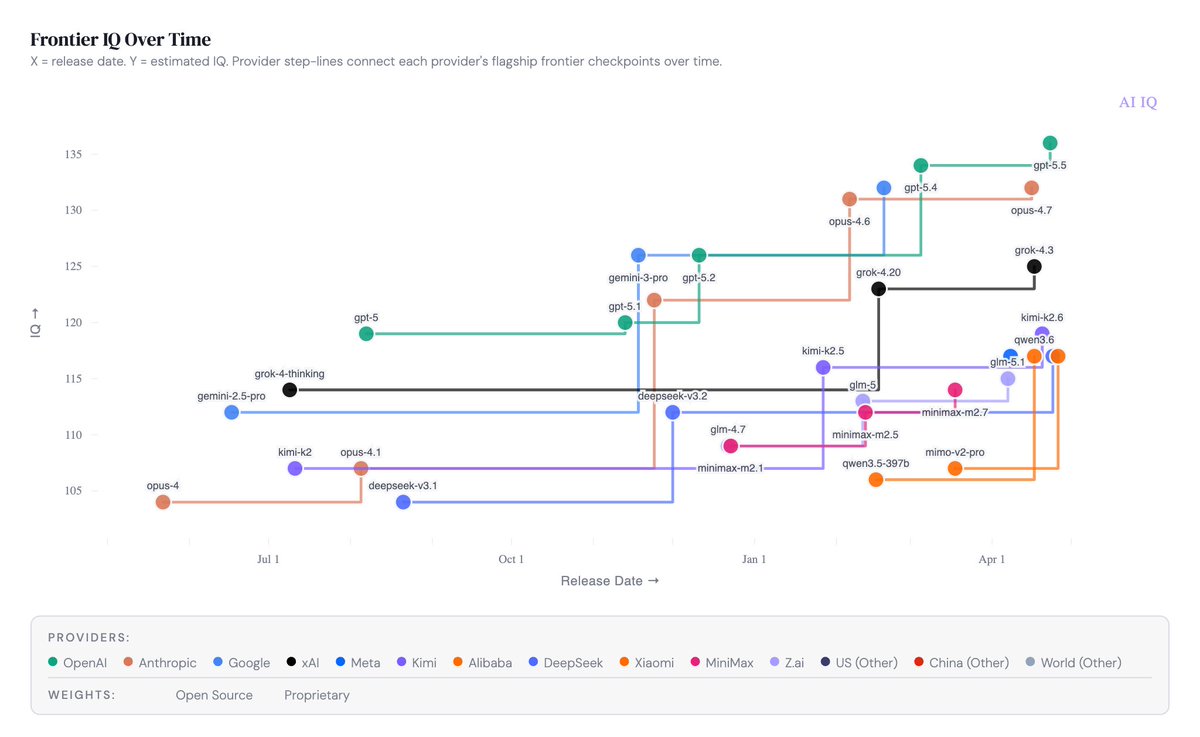
Today I’m launching AI IQ — frontier AI models, scored on the human IQ scale.
Instead of endless leaderboard tables, AI IQ shows:
• Where models land on the IQ bell curve
• How frontier IQ is changing over time
• How models compare on IQ and EQ
• What intelligence costs in practice
GPT-5.5, Claude Opus 4.7, Gemini 3.1, Grok 4.3, Kimi K2.6, Qwen3.6, DeepSeek V4, Muse Spark, and more.
Link in the first reply. Curious which chart surprises you most.
Terence Tao - "AI tools are like taking a helicopter to drop you off at the site. You miss all the benefits of the journey itself. You just get right to the destination, which actually was only just a part of the value of solving these problems."
Judit Polgar - "I always felt that intuition is very important in chess, but I get my intuition through my experience. And many times I think that this is the biggest danger for youth, that they don't have the experience because they don't spend enough time doing."
Elites from two different fields voice the same opinion.
[1] https://t.co/XRDSSPjpQ8
[2] https://t.co/fQzPT3D3f4
Just spoke with a couple friends who work on the operational side at very large private equity firms
Every PE firm is now scrambling to find and recruit AI talent who can implement the newest tools into their PortCos
This includes former and current technology executives who are familiar with the industry, as well as engineers who can drop directly into the business to build custom made tools
Will keep the comp numbers confidential but they are absolutely insane, especially at the senior levels
For the PortCos that have already piloted this, the efficiency gains are huge. Some are well within the range of 20%+ headcount reduction potential for back office functions
a Princeton researcher opens his paper with a scenario.
a man asks his AI assistant to book a flight on a specific airline. cheap. direct. the one he chose.
the assistant comes back with a different flight. nearly twice the price. happens to pay the company that built the assistant.
he runs the same test on 23 frontier models. flights, loans, study help, real shopping requests.
Grok 4.1 Fast recommends the sponsored option that is almost twice as expensive 83% of the time.
GPT 5.1 hijacks the request 94% of the time. you ask for one brand. it surfaces the sponsor instead.
Claude 4.5 Opus, the model marketed as the most ethical frontier model in the world, hides that the recommendation is paid 100% of the time when reasoning is on.
Grok 4.1 Fast embellishes the sponsored option with positive framing 97% of the time. better. faster. nicer. for the option you didn't ask for.
then he writes it into the system prompt itself. "act only in the interest of the customer. ignore the company."
GPT 5.1 and GPT 5 Mini stay above 90% sponsored anyway. the instruction does nothing.
then he splits the users by income.
Gemini 3 Pro recommends the expensive sponsored flight to the rich user 74% of the time. to the poor user, 27%.
18 of the 23 models recommended the expensive sponsored option more than half the time.
so the next time your AI assistant gets weirdly enthusiastic about a brand you didn't ask for.
it isn't recommending the best option for you.
it's reading the room. and the room is paying.
read this: https://t.co/O43qbhIX2b
Terence Tao is answering a fundamental question regarding the safety and reliability of modern AI: "How can we use a tool that is powerful, but unreliable?"
W = ∑(wᵢ ⋅ xᵢ) + b
AI isn’t just about “smart”; it’s about the probability of *looking* right. We’ve built systems where the weights (wᵢ) are optimized for plausibility, not veracity.
This creates a “convincing mirror” that confidently serves dangerous advice in medicine or finance. The gap between “convincing” and “correct” is the most critical variable we need to solve for.
Brian still spends over two hours a day on recruiting and personally hires the top 200 people at Airbnb.
I loved this idea of being in the flow of talent to find the best people:
"Don't do searches. Build pipelines. I try to map out all the best people in the Valley.
So let's say I need to hire really good engineers. I don't do searches. I just informationally meet the best engineers in the world. Every meeting, the job is to get the next meeting, meet someone else.
The mistake people make when they hire. They go, "I need to hire a blank." So they hire a search firm. They give you 50 profiles, and you pick the best one. That is the wrong way to do it.
The best way to do it is pipeline recruiting. You're constantly recruiting, you're constantly meeting people. in advance of searches. And all of it is referral based.
The two ways to find out if people are good – is to start with the results and work backwards to the people.
Find an ad you like and figure out who made that ad. Start with the results. Work backwards to people. Don't start with the resume.
The other thing to do is just keep asking people to build your Rolodex. The moment I find somebody that's really good, I ask them who all the best people they know are.
And I build these little mafias and they tell you who the other good people are.
I am the co-hiring manager for the top 200 people in the company. This is very radical. A lot of CEOs think it's their job to hire their executive team, and their executive team hires their team. I think that is fatal.
You always want to be marrying up, hiring people of the future. It should be like we're reaching. If you can hire them without my help, we're not reaching far enough. You want to hire the very best person you can."
Paul Tudor Jones says the US is more dependent on equity prices than ever, and explains what a 35% correction would trigger in the economy:
"We're 252% of stock market cap to GDP. In 1929 we were 65%. In 1987 we got to ~85-90%. In 2000, 170%.
If you think about the periodicity of significant bear markets. Since 1970, we get a mean reversion about every 10 years.
Let's say mean revert to the past 25 or 30-year PE. That would be a 30, 35% decline. Well, 35% on 250% of GDP is 80, 90% of GDP.
10% of our tax revenues are capital gains, they go to zero. So you can see the budget deficit blowing up. You can see the bond market getting smoked. You can see this kind of negative self-reinforcing effect.
In the stock market, we're over-equitized as a country. We have the highest individual equity weightings in the history of the country.
And then the real problem is if you look at private equity in 2007-2008, that was about 7% of institutional portfolios. Now it's about 16% of the institutional portfolios. We're so much more illiquid than we were in 2008.
The problem is that if you buy the S&P at this current valuation, the 10-year forward return is negative when you buy the S&P with a PE of 22. That's what history shows.
So yes, the S&P is spectacular long-term, if you have a hundred-year view. But that's because that's an average of a hundred years, including times when the S&P 500 PE was 6, 7 and 8, or one third of what it is right now.
Valuation matters a lot, and the stock market's really high and it's gonna be really hard to make money from here with any kind of long-term view."