A person who spends thirty minutes scrolling before bed has not merely lost thirty minutes.
They may have lost the version of tomorrow morning where they woke up sharp enough to write.
They may have lost the version of next week where they finally tolerated boredom long enough for an original thought to appear.
The transaction is invisible because the price is paid in probability.
@scupytrooples As long as the blockchain itself is open and decentralized we have decades to get it right. Yes centralized solutions are faster to market, but truly decentralized apps will have staying power long after mainstream trends come and go.
@gordonliao Not in the DAO space but I suspect that identity verification is table stakes at this point for concave voting designs ie Gitcoin passport in Gitcoin Grant rounds
Lighter's escape hatch just got independently verified: if the sequencer ever dies, you can generate a ZK proof and withdraw directly on Ethereum.
Thanks to @L2beat for the writeup on our fully verifiable and permissionless onchain trading infrastructure.
I recently turned 33, and every year I want to go back to 21-year-old Patrick with a list of lessons.
If you're in your 20s, these are for you.
Most lessons only land after an ass-whooping. And even then, you usually miss them the first time.
@ClementWalter The most persuasive argument was stablecoins’ advantage of instant settlement in payments, swaps, etc (which she acknowledged) is weakened when the stablecoin itself can depeg, is fragmented amongst issuers, and rehypothicated in the background. All addressable though imo
🚨 I don't think people realize how bad things are at @aave right now.
All core markets are at 100% utilization, that includes $3 bil in USDT and $2 bil in USDC stuck!
That means you CAN'T WITHDRAW your money!
A long post on why and how we ended up here.
When the rsETH exploit happened and AAVE incurred bad debt, whales like Justin Sun, MEXC exchange, and others immediately withdrew billions from AAVE.
This instantly drained all available liquidity in key core markets like ETH, USDT, USDC and so on. Those first to withdraw got out, laggers got trapped.
Initially, the ETH market hit 100% utilization, meaning you could not withdraw your ETH from AAVE.
Worse, this also means the protocol can't process ETH liquidations should ETH price fall/crash. If you can't sell any ETH, you can't liquidate to cover debt obligations.
That means the risk of more bad debt incurred by AAVE is increasing the longer its markets remain stuck.
Nevertheless, users can still sell at a minor loss the aETHwETH tokens on Uniswap or similar aggregators. That exit door is the last one remaining for ETH depositors on AAVE.
The same cannot be said by depositors of USDT and USDC. They are stuck.
That's because AAVE lost over $6 billion in liquidity in the past 24h. As whales took out their money, USDT and USDC also hit 100% utilization.
These markets are now also stuck with money locked. Panic is spreading and desperate times call for desperate measures.
Some users decided to borrow against USDT/USDC and exit via other markets at a 10-25% loss (90-75% LTV). Basically you borrow GHO/DAI/USDe against your locked USDT/C.
But as more liquidity leaves AAVE, more markets get to 100% utilization and get locked/stuck due to low liquidity. This is quickly cascading across all available markets.
Luckily the crypto market was rather flat today so liquidation risks were marginal, but if things change there are billions in stablecoins and other assets locked on AAVE that can't process liquidations = more bad debt for AAVE.
If users or related protocols that are stuck need access to their money to prevent liquidations or other critical function, they have a huge problem on their hands.
Plus, nobody wants to deposit (or provide liquidity) in these markets now since your ETH, BTC, USDC/T could be stuck there for who know how long.
As soon as any available liquidity is made available, it is instantly taken out by bots fighting to get out. As I wrote this I saw 250k in liquidity on USDC vanish in seconds.
Then there is the bad debt question.
There's over $200 mil in bad debt incurred by AAVE via rsETH that's like a hot potato. Nobody knows who will eventually pay this bill.
If you didn't remove your assets from AAVE, you risk receiving at least part of that bill in some form. Not having access to your money is part of that risk too.
Contagion is also extremely high.
Many protocols and apps rely on AAVE for their earn mechanics. These protocols and their users are stuck too and may be forced to incur bad debt with no fault of their own.
October 10th was a CEX driven crash, this is a DeFi risk mitigation failure of epic proportions.
AAVE should have never onboarded rsETH as a collateral asset, at least not to the size of hundreds of millions that allowed the hacker to walk away (i.e. borrow) over $200M in ETH after posting fake collateral.
Rumors on X are saying rsETH was onboarded by AAVE due to a conflict of interest (lobbying) by a given service provider. If true, this is a major failure of its governance structure (nothing new).
The folks at @KelpDAO who manage rsETH also have a tough decision to make on who will actually pay for the $200M exploit. AAVE users? L2 rsETH users? Everyone affected gets a haircut to account for the loss?
The AAVE team and its founder, Stani, have been quiet for over 20h since the exploit after initially announcing the rsETH market freeze.
They have a pretty big problem on their hands since the whole protocol is at risk right now. Trust is already lost as AAVE is bleeding billions in TVL to the level of hitting 100% utilization on all core markets.
Maybe some key actors in the space will step in to provide liquidity to stabilize the markets on AAVE before this gets even worse.
I got lucky to get out of AAVE early when I first saw this. I also removed all assets from DeFi and will not touch any protocol in the next few weeks. Too much risk for a few percentage points in yield.
If you found this informative, like, share, and follow @duonine
I spend a lot of time talking about liquidity, tokenization, and financial plumbing, but I've never really written about how I got here. It's Friday, so.
I started trading at sixteen. Trading is probably too generous - I was buying stocks because someone told me that's what you do if you want to feel like a serious person, and I wanted, in the way that sixteen-year-olds want things, to feel like Wall Street.
I moved to bonds pretty quickly, liabilities seemed more interesting to me than equity, which is the kind of preference that tells you something about a person.
From bonds I ended up in FX, and FX is where things got strange, because FX forces a question on you that equities let you avoid for a very long time: why does money itself change price? Why does someone in another country accept fewer euros today than yesterday? What happened overnight?
I was tinkering with crypto at the same time, and the technology fascinated me, but my financial brain - the part that liked regulated products, clearing houses, central banks, legal certainty about who owes what to whom when someone defaults - kept dragging me toward the institutional side of things.
These preferences are not obviously compatible, but it turns out there is a field where they coexist, and the field is tokenized money, which is the question of what kind of cash you use to settle a transaction when the asset leg moves on a blockchain.
Tokenized money turned out not to be one thing. It was at least five or six things that sounded similar in conference presentations and behaved very differently once you asked the question that actually matters: who is funding settlement, with what kind of money, under what constraints, and at what cost?
Stablecoins were one answer - prefund the liquidity, warehouse the collateral, pay for continuous availability with trapped balance sheet.
Tokenized deposits were another - commercial bank money on new rails, which means you inherit the credit perimeter, the access model, the intraday funding profile, and the bank's cut-off logic along with the money.
Then there were CBDCs, wholesale and retail, each with a different set of assumptions about what the central bank is willing to build and operate.
Tokenized money market fund shares raised a question I found genuinely interesting, which is: can you actually settle a DvP with a fund share? A fund share is not cash. It is a claim on a pool whose NAV doesn't strike until 4pm, and the settlement mechanics get strange in ways that are not obvious until you think about what "delivery" means when the thing being delivered doesn't have a final value yet.
And then there was the hybrid - asset on-chain, cash through an RTGS, DvP coordinated across both rails. European style.
Anyway. I was somewhere in the middle of all of this when someone asked me a question I now think about more or less every day.
"Do you know what happens to a stock after you buy it? The post-trade process? Why does it take T+2 to settle?"
I had the standard answer ready. Legacy systems. They're old. They're slow. Modernize the technology and you could settle instantly.
That answer is wrong.
Not wrong because the systems aren't old - they are old, some of them spectacularly so.
Wrong because the age of the technology is not the reason settlement takes time.
The reason settlement takes time is that the system is using that time to do several things that are, collectively, extraordinarily valuable, and the most important of those things is netting.
Here is what netting does. A thousand participants trade a million times during the day. Some of them buy Apple and sell Microsoft, some sell Apple and buy Google, some do both sides of the same stock in the same afternoon.
At the end of the day, NSCC - the clearing house in the middle of virtually every US equity trade - takes all of those obligations, figures out what each participant owes and is owed across everything, and compresses the entire day's gross activity into a single net number per participant. On a normal day, gross trading is roughly $1.7 trillion.
After multilateral netting, the cash that actually has to move is something like two to 3% of that.
The other 97% cancels out.
I want to be clear about what that means, because I think it is the single most underappreciated fact in financial markets. Without netting, every participant would need to fund every trade individually, in real time, in full. The amount of cash the system would require to support the same volume of business would be roughly thirty times what it requires today.
The settlement cycle is the time the system needs to match and affirm trades, novate obligations into the clearing stack, net them down, fund the net positions, borrow and move securities into the right accounts, coordinate cross-border FX, repair exceptions, manage fails, and get every instruction clean before final delivery. T+1 is not the fastest the technology could go. T+1 is the fastest the market decided it could operationally absorb without turning every late instruction and unmatched allocation into a settlement break.
The settlement cycle is not ONLY dead time. It is also coordination time. And the coordination saves more liquidity than anything else in the system.
But of course, that works because the system was built around risk, which leaves us wondering whether risk can take a back seat... I'll leave that for another time.
Of course, this is exactly where tokenization gets interesting. If you settle atomically on a blockchain - real-time, trade by trade, instant finality - you eliminate counterparty risk, which is genuinely valuable. Nobody is exposed to the other side of the trade for a day while the clearing house nets and settles. But you also eliminate netting, because there is nothing to net: each trade settles on its own as it happens. And without netting, the funding requirement goes up by a factor of roughly thirty. Prefunding replaces netting. Intraday liquidity replaces overnight funding of a net debit. The risk does not disappear. It changes shape.
That is, I think, the central question in tokenized market infrastructure. Not "can we put stocks on a blockchain." Not "can we demonstrate atomic DvP in a pilot." Can you get the finality and speed and programmability of blockchain settlement without giving up the liquidity compression that the current system provides through netting? Can you get atomic finality without the atomic funding requirement?
Every model of tokenized money is a different bet on that question.
Stablecoins say: accept the prefunding cost, buy availability.
Tokenized deposits say: keep using bank money, accept the balance sheet economics.
CBDCs say: use the cleanest settlement asset in the system, accept the governance consequences.
Tokenized MMF shares say: maybe close-to-cash is good enough - but close-to-cash is still not cash, and the gap shows up at exactly the moment you need it least.
The hybrid model says something I increasingly respect: maybe the asset should move where programmability matters and the cash should stay where settlement liquidity is deepest, and the real engineering problem is synchronizing the two without reintroducing the principal risk you were trying to eliminate.
None of these is obviously right. Each one solves something and creates something else. And underneath all of them is the same question I couldn't answer when someone first asked me about T+2: what is the relationship between settlement, liquidity, and time, and how fast can you go before the cost of going that fast exceeds the benefit?
I don't know the answer yet. I think it's possible to get most of the way there - preserve the liquidity efficiency while getting the speed and the programmability and the around-the-clock availability.
I think the people working on it are closer than the market gives them credit for. But I also think the answer starts with understanding why the plumbing works the way it does, not with assuming it's broken, and "legacy systems" is what you say when you're looking at the surface of the problem rather than the function underneath it.
I know, because I used to say it.
Best,
Neira
The Cost of Intelligence is Heading to Zero | Hyperspace P2P Distributed Cache
We present to you our breakthrough cross-domain work across AI, distributed systems, cryptography, game theory to solve the primary structural inefficiency at the heart of AI infrastructure: most inference is redundant.
Google has reported that only 15% of daily searches are truly novel. The rest are repeats or close variants. LLM inference inherits this same power-law distribution. Enterprise chatbots see 70-80% of queries fall into a handful of intent categories. System prompts are identical across 100% of requests within an application. The KV attention state for "You are a helpful assistant" has been computed billions of times, on millions of GPUs, identically.
And yet every AI lab, every startup, every self-hosted deployment - computes and caches these results independently. There is no shared layer. No global memory. Every provider pays the full compute cost for every query, even when the answer already exists somewhere in the network.
This is the problem Hyperspace solves where distributed cache operates at three levels, each catching a different class of redundancy:
1. Response cache
Same prompt, same model, same parameters - instant cached response from any node in the network. SHA-256 hash lookup via DHT, with cryptographic cache proofs linking every response to its original inference execution. No trust required. Fetchers re-announce as providers, so popular responses replicate naturally across more nodes.
2. KV prefix cache
Same system prompt tokens - skip the most expensive part of inference entirely. Prefill (computing Key-Value attention states) is deterministic: same model plus same tokens always produces identical KV state. The network caches these states using erasure coding and distributes them via the routing network. New questions that share a common prefix resume generation from cached state instead of recomputing from scratch.
3. Routing to cached nodes
Instead of transferring KV state across the network for every request, Hyperspace routes the request to the node that already has the state loaded in VRAM. The request goes to the cache, not the cache to the request.
Together, these three layers mean that 70-90% of inference requests at network scale never require full GPU computation.
This work doesn't exist in isolation. It builds on research from across the industry: SGLang's RadixAttention demonstrated that automatic prefix sharing can yield up to 5x speedup on structured LLM workloads. Moonshot AI's Mooncake built an entire KV-cache-centric disaggregated architecture for production serving at Kimi. Anthropic, OpenAI, and Google all launched prompt caching products in 2024 - priced at 50-90% discounts - because system prompt reuse is so pervasive that it changes the economics of inference.
What all of these systems share is a common limitation: they operate within a single organization's infrastructure. SGLang caches prefixes within one server. Mooncake disaggregates KV cache within one datacenter. Anthropic's prompt caching works within one API provider's fleet. None of them can share cached state across organizational boundaries.
Hyperspace removes this boundary. The cache is global. A response computed by a node in Tokyo is immediately available to a node in Berlin. A KV prefix state generated for Qwen-32B on one machine is verifiable and reusable by any other machine running the same model. The routing network provides the delivery guarantees, the erasure coding provides the redundancy, and the cache proofs provide the trust.
What this means for the cost of intelligence
Big AI labs scale linearly: twice the users means twice the GPU spend. Every query is a cost center. Their internal caching helps, but it's siloed - Lab A's cache can't serve Lab B's users, and neither can serve a self-hosted Llama deployment.
Hyperspace scales sub-linearly. Every new node that joins the network adds to the global cache. Every inference result enriches the cache for all future requests. The cache hit rate rises with network size because query distributions follow a power law - the most common questions are asked exponentially more often than rare ones.
The implication is simple: as the network grows, the effective cost per inference drops. Not linearly. Logarithmically.
At 10 million nodes, we estimate 75-90% of all inference requests can be served from cache, eliminating 400,000+ MWh of energy consumption per year and
avoiding over 200,000 tons of CO2 emissions. The first person to ask a question pays the compute cost. Everyone after them gets the answer for free, with cryptographic proof that it's authentic.
Training is competitive. Inference is shared
Open-weight models are converging on quality with closed models. Labs will continue to differentiate on training - data curation, architecture innovation, RLHF tuning. That's where the real intellectual property lives.
But inference is a commodity. Two copies of Qwen-32B running the same prompt produce the same KV state and the same response, byte for byte, regardless of whose GPU runs the matrix multiplication. There is no moat in multiplying matrices. The moat is in training the weights.
A global distributed cache makes this separation explicit. It doesn't matter who trained the model. Once the weights are open, the inference cost approaches zero at scale - because the network remembers every answer and can prove it's correct.
No lab, no matter how well-funded, can match this. They cannot share caches across competitors. They scale linearly. The network scales logarithmically. The
marginal cost of intelligence approaches zero.
That's the endgame.
Ethereum planned to cut L1 deposit wait times by 98%.
Not with a hard fork.
Not with a new chain.
Not by breaking anything.
Just by counting attestations differently.
The Fast Confirmation Rule (FCR) is the upgrade shipping to @ethereum right now ↓
🚀 New Plonky3 release just dropped.
This is probably our most impactful and ambitious release so far:
- MUCH faster lookups
- High-arity folding
- N-ary Merkle trees + Merkle caps
- Major Poseidon2 optimizations
- Poseidon1 support
- And many more…
Let’s break it down 👇
Craaazy 365 days of @leanEthereum progress. Cheers to the builders. Cheers to the dreamers. Cheers to anti-fragility, too :)
Devcon, Bangkok — Nov 12, 2024. The suspense is real. The room overflows; hundreds can't get in. An "announcement of an announcement" had sparked wild speculation about my "most ambitious initiative".
Who knew the beam chain vision would evolve into lean Ethereum? Next-level ambition, seeping into all layers of L1. Snarks for consensus and execution. Fort mode and beast mode.
What's new? zkEVMs. Real-time proving. Full validation in a tab, on a phone. Let's pump L1 gas with the exponential snark curve. Starting in months, not years. To me it all points to 10K TPS, the gigagas frontier.
Dream bigger dreams for L1. Believe in something.
———
part 1—lean consensus
devnets
→ clients: 4 new lean CL clients (Zeam, Ream, Qlean, Lantern)
→ languages: 3 new CL languages (Zig, C++, C)
→ specs: by @tcoratger + 14 others; 3SF-mini subspec by @vitalikbuterin
→ testing: revamped test framework by @fselmo2; @Sib_Katya metrics
→ devnets: multi-client 3SF with 4s slots and 12s finality; PQ soon™
coordination
→ hires: EF Protocol coordinators @corcoranwill and @ladislaus0x
→ CL teams: led by @Gajpower, @unnawut, @kamil_abiy, @mstore80
→ 7 consensus calls: teams, PQ, p2p, exit queue, APS, 3SF, PQ specs
→ Cannes workshop: 1 day at EthCC in June; interop kicked off
→ 13 interop calls: by @corcoranwill on Wednesdays at 2pm UTC
→ Cambridge Oct workshops: 1 day leanVM, 3 days PQ, 3 days CL
cryptography
→ leanSig: 3 papers on hash sigs by Benedikt, @khovr, @kudinov_mikhail
→ leanVM: fast minimal aggregation zkVM by Emile
→ WHIR: fast Plonky3 implementation by @tcoratger
→ optimisoors: @AngusGruen, @GiacomoFenzi, @lambdaclass, @kiliconu
→ Poseidon2: 4 cryptanalysis workshops by @khovr, @asanso
→ maths: $1M Millennium-like proximity prize; papers flowing
→ formal verification: ArkLib by @QuangVDao
research
→ consensus team: hires @yannvon and lead @robsaltini join @luca_zanolini
→ faster finality: 1- or 2-round designs with Ethereum-grade liveness
→ 3sf-gold: new fast inclusion by @fradamt, @vitalikbuterin from Cambridge
→ p2p: @qdrvm_io simulator; @raulvk ethp2p; @soispoke leanp2p
→ rainbow staking: new Cambridge ideas; specs by Dan Goron & Alex Vlad
———
part 2—lean execution
zkEVM tech
→ real-time proving: ~100 engineers pushing across ~10 zkVM teams
→ GPU proving: 16 5090s (10kW) proving mainnet; $0.01/block
→ guests: revm (Reth), levm (Ethrex), evmone (Zilkworm), ZKSync OS
→ more guest programs: Geth, Besu, Nethermind and others soon™
→ RISC-V: de facto ISA of choice for zkEVM proving
→ Picus: prolific Veridise tool to identify under-constraints
→ formal verification: $4M across 40 grants by @alexanderlhicks
Ethproofs community
→ zkVM integrations: Airbender, OpenVM, Pico, R0VM, SP1, Ziren, ZisK
→ other integrations: Cysic, Fermah, Marlin, Snarkify, Zilkworm, ZkCloud
→ website: driven by @fbwoolf under new EF Ethproofs team
→ 7 calls: zkVMs, RTP, gigagas, RISC-V, native rollups, proximity gaps
→ Ethproofs day: Nov 22 at Devconnect; register at ethproofs[.]day
→ zkAttester demo: my home validator on zkEVM proofs at Ethproofs day
EF zkEVM team
→ new team: led by @kevaundray with Cody, Han, Ignacio, Radek, Sophia
→ EF blog post: real-time proving requirements by @_sophiagold_
→ zkLighthouse: modified Lighthouse client by @kevaundray
→ zkEVM/acc: @ignaciohagopian benchmarks; @codytouchgrass tests
→ more zkEVM/acc: @kevaundray standardisation; Ere by @han__0110
future of EL
→ Fusaka: per-tx gas limit (EIP 7825); MODEXP killer (EIPs 7823, 7883)
→ EVM 2.0: @vitalikbuterin proposal to enshrine RISC-V under the EVM
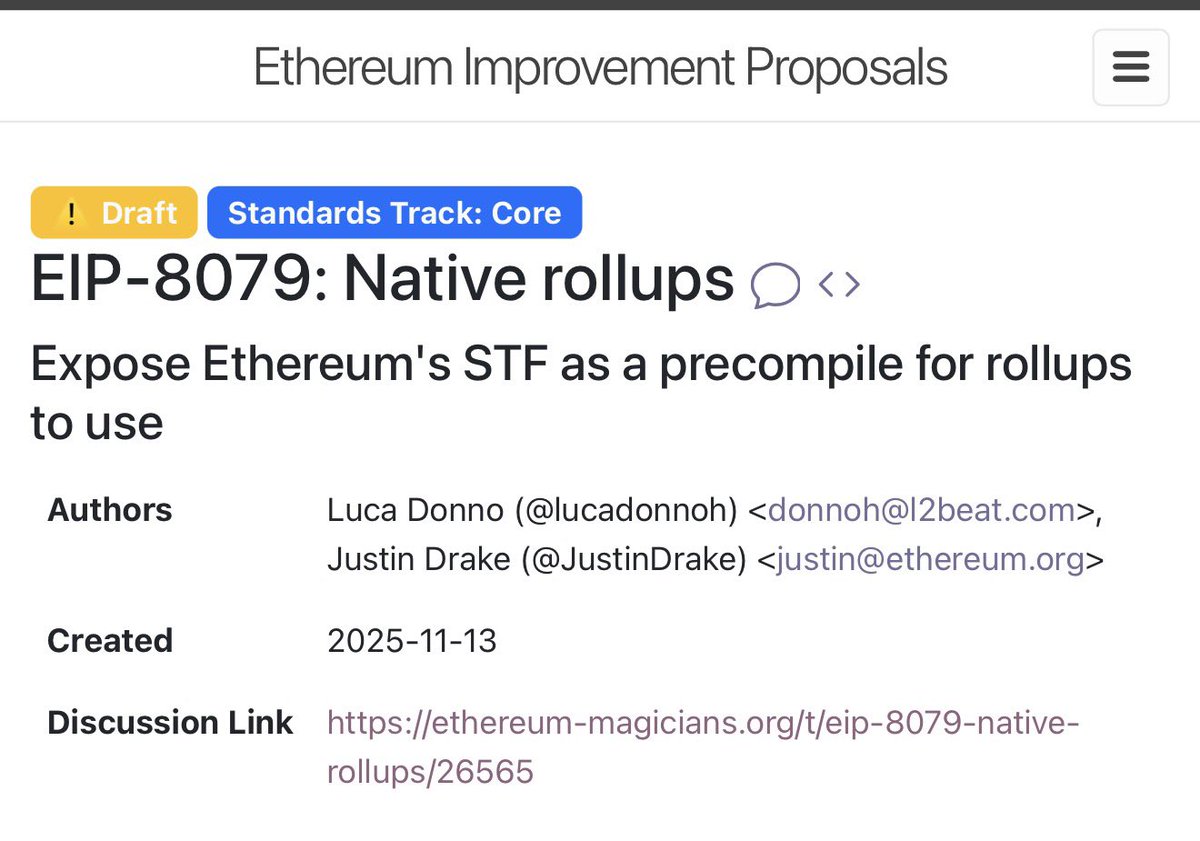
→ native rollups: championed by @lucadonnoh; wrote book and draft EIP
→ gas auto-pumps: 3x/year gas pumps (EIP-7938 by @dankrad)
→ gigagas L1: champion wanted—reach out :) [email protected]
. @Lighter_xyz, a ZK rollup using Ethereum blobs, is doing 4k+ TPS posting just ~100MB per day, all thanks to state diffs and the app-specific architecture.
for comparison:
- @arbitrum: 37 TPS @ 436MiB/d
- @base: 155 TPS @ 2.11GiB/d
- @soneium: 39 TPS @ 241 MiB/d
Today, around 7:48 AM UTC, an exploit affected Balancer V2 Composable Stable Pools.
Our team is working with leading security researchers to understand the issue and will share additional findings and a full post-mortem as soon as possible.
Because these pools have been live onchain for several years, many were outside the pause window. Any pools that could be paused have been paused and are now in recovery mode.
All other Balancer pools are unaffected. This issue is isolated to V2 Composable Stable Pools and does not impact Balancer V3 or other Balancer pools.
Balancer is committed to operational security, has undergone extensive auditing by top firms, and had bug bounties running for a long time to incentivize independent auditors. We are working closely with our security and legal teams to ensure user safety and are conducting a swift & thorough investigation. We’re grateful to our partners and the broader DeFi community for their support.
Security notice: Fraudulent messages claiming to be from the Balancer Security Team are circulating. These are not from us. Do not interact with unsolicited communications or click unknown links.
Official updates will be posted only via:
- This official Balancer account on X (Twitter)
- Our official Discord server
Be careful with communications from other sources, they can be fraudulent.
We will provide a comprehensive update with more details as our investigation progresses.
The Balancer Team.
programmable Ethereum
part 1: programmable Ethereum, VMs, and ISAs
part 2: zk everything (costarring: RISC-V, EVM)
part 3: scaling lean Ethereum with leanVM and EVM 2.0
1/30