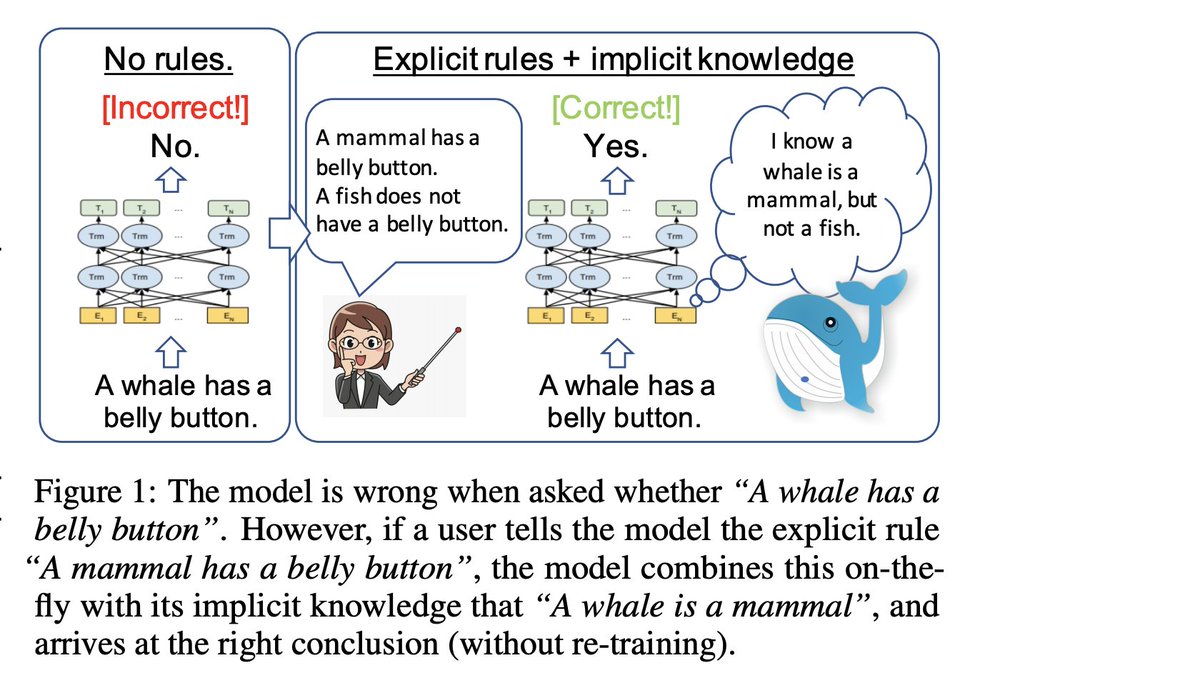
Can we instantly correct pre-trained models by showing them natural language rules and facts? Can they systematically reason over implicit knowledge while doing so? https://t.co/fdLNLfPZ4B New joint work with Oyvind Tafjord, Peter Clark, @yoavgo and @JonathanBerant suggests yes!
Helping or Herding? Reward Model Ensembles Mitigate but do not Eliminate Reward Hacking
paper page: https://t.co/piWtpFKPLs
Reward models play a key role in aligning language model applications towards human preferences. However, this setup creates an incentive for the language model to exploit errors in the reward model to achieve high estimated reward, a phenomenon often termed reward hacking. A natural mitigation is to train an ensemble of reward models, aggregating over model outputs to obtain a more robust reward estimate. We explore the application of reward ensembles to alignment at both training time (through reinforcement learning) and inference time (through reranking). First, we show that reward models are underspecified: reward models that perform similarly in-distribution can yield very different rewards when used in alignment, due to distribution shift. Second, underspecification results in overoptimization, where alignment to one reward model does not improve reward as measured by another reward model trained on the same data. Third, overoptimization is mitigated by the use of reward ensembles, and ensembles that vary by their pretraining seeds lead to better generalization than ensembles that differ only by their fine-tuning seeds, with both outperforming individual reward models. However, even pretrain reward ensembles do not eliminate reward hacking: we show several qualitative reward hacking phenomena that are not mitigated by ensembling because all reward models in the ensemble exhibit similar error patterns.
Two startups are rejecting investments from Web Summit’s venture arm, a sign that fallout from the summit co-founder’s remarks on Israel isn't over.
https://t.co/vRgRNSudNp
By @nmasc_
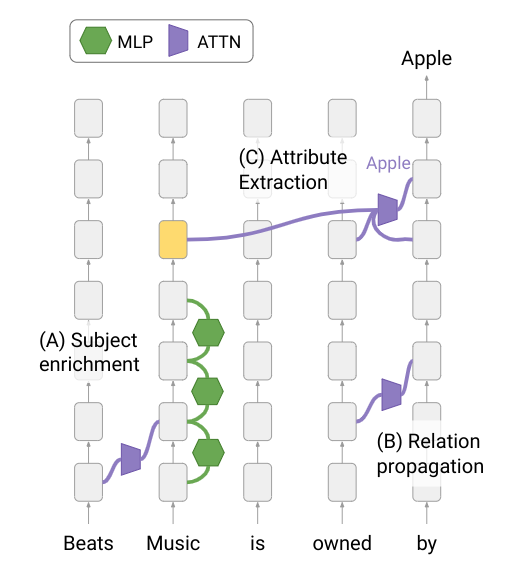
LMs capture many factual associations, but how do they recall them internally during inference?
In a new preprint, we find that LMs build attribute-rich subject representations, from which attention heads extract the predicted attribute.
@jasmijnbastings @fajtak@amirgloberson 🧵
A single chain-of-thought (CoT) may not be enough to answer complex questions, can an LLM meta-reason over multiple CoTs?
In our new preprint, we show that meta-reasoning boosts performance on multi-hop QA datasets!
Paper: https://t.co/UnfZ59Unkt
🧵1/4
שרשוראור מוצרי - איך כורים זהב מתמיכה?
אחת מהטעויות ששמתי לב אליהן שמנהלי מוצר בתחילת דרכם עושים - הם לא יודעים איך לייצר ערוץ פידבק איכותי מפניות של לקוחות לתמיכה.
חשוב לזכור שלקוחות יפנו אליכם (ישאירו ביקורת, או ישלחו הודעה) רק במקרי קיצון, כי זה דורש מהם זמן ואנרגיה, לדוג׳:
On this week’s pod ep we’re combining a guest interview w/ the new partner meeting format. We start with the partner meeting segments then I chat w/ a guest. Hopefully a fun twist for everyone.
This week's guest is @AlonTalmor, Founder & CEO of Ask-AI. https://t.co/6v1SnmHH22
--> @AlonTalmor of #AskAI -- "aggregates text-heavy company knowledge & customer communications to reveal pinpointed answers and actionable insights." https://t.co/QUfq6raXcm #websummit#opening#mainstage
Excited to be speaking at #websummit2022#breakout sessions 1st of Nov. 17:30PM and, 3rd of Nov. 9:45AM, as well as the panel "The socio-economic impacts of AI" at DeepTech stage, at 14:55 Nov 3rd. Come say hello!
מחשבות של לילה - הדבר הכי קשה בסטארטאפ בצמיחה זה להבין מה חווית הלקוח ברגע נתון, איפה בתהליכים הוא חווה תסכול או שירות לא טוב. תמיד צריך להשאר מחוברים למקום הזה, זה קשה כי בסוף יש עוד הרבה אנשים בדרך.הטריק שלי זה לקרוא מיילים של לקוחות שמגיעים לתמיכה ולנתח מהם את החוויה לאחור.
@EynatGuez כחברה שמתמחה במתן תשובות וניתוח תקשורות לקוח ממקורות מרובים, הבעיה שתארת היא במרכז הפתרון שבנינו. בעזרת NLP אנחנו מנתחים טקסט ממקורות כמו טיקטים, CSATים, שיחות עם לקוחות כדי להציף בעיות שחוזרות עצמן לא כאוסף טגיות אלא כמשפט שלם בשפה טבעית. https://t.co/3vJnbKF5eh (נדב נאמן מכיר)
Come to say hello and hear about our work with BRAF inhibitors on Ameloblastoma of the mandible. 100% RR 😱 Poster board #140 #ASCO22 https://t.co/KWjN315Fcn
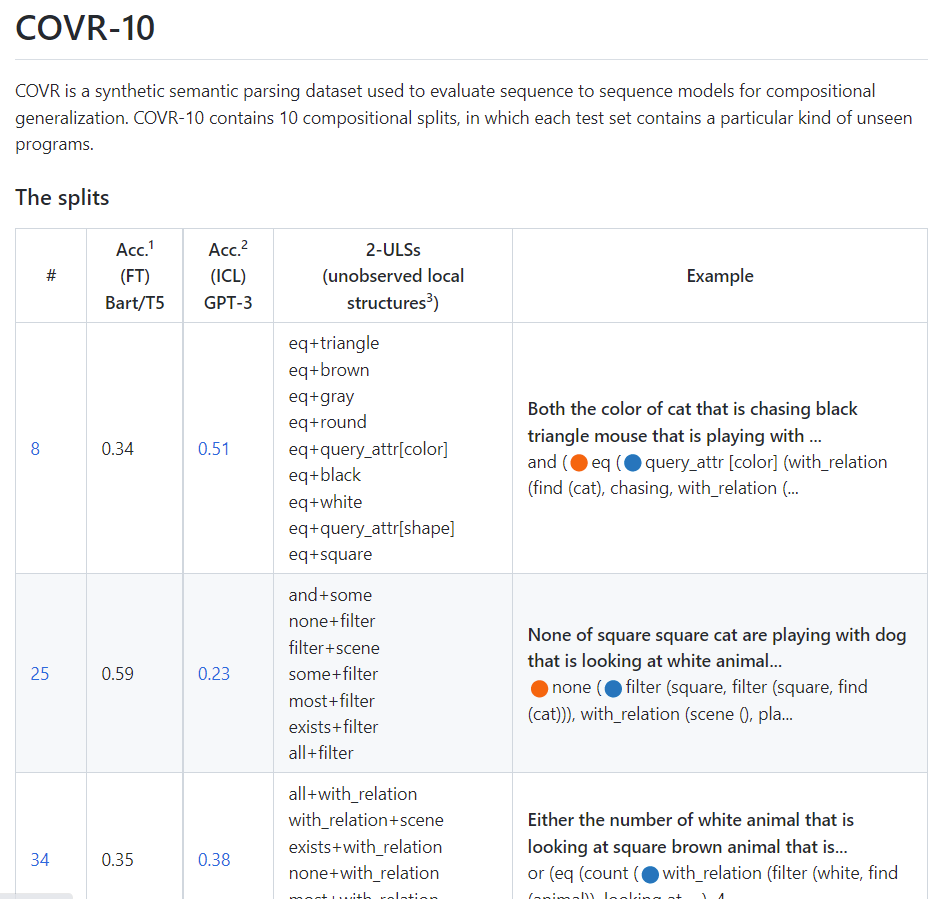
📢📢📢 We release COVR-10: a set of 10 challenging compositional generalization splits (with some intriguing results on GPT-3’s compositional skills). @JonathanBerant@shivanshug11
https://t.co/wzaXoFtt2A
1/4