During World War II, a German soldier, a Japanese soldier, and an Italian soldier are all hauled in for an interrogation.
The German soldier insists that his superior Aryan genetics will allow him to resist interrogation. The Japanese soldier claims that his loyalty to the Emperor will give him the strength to not crack. The Italian soldier says he wishes he had the other two's fortitude, because he's sure he'll crumble quickly.
During the interrogation, however, the Italian is the only one to withstand the questioning and not spill.
The German and Japanese soldiers are impressed and ask how he managed to keep mum, to which the Italian answers: "I wanted to talk, but they tied my hands to the chair!"
Tony Robbins on how to change someone who doesn't want to change:
1. People only change when they link enough pain to staying the same or enough pleasure to changing. Ideally, both at once. This is not a mindset shift. It happens in the nervous system, not the head. Your head can know exactly what you should do, and your gut will override it every single time.
2. Yes, you can change someone who doesn't want to change. But not by forcing them. You find the leverage that makes them change themselves. Everyone has a point that will get them to follow through. For some people, it is not even the threat of their own life. For others, it is their children. For others, it is spiritual growth. The leverage is different for everyone, but it always exists.
3. The food poisoning example. You used to love a food or a drink. Then one night it came back up with enough intensity and enough aroma that to this day you cannot look at it without feeling repelled. No willpower required. Your brain simply rewired what it links pleasure to. That is the entire mechanism of change in one story.
4. Scrooge did not want to change. He was certain he did not need to change. Three ghosts showed up and did one thing: they made him link unbearable pain to his past, his present, and his future simultaneously. When there is nowhere to escape, change happens in a heartbeat. Robbins calls this the Dickens pattern. Lock pain into all three time zones at once, and there is no exit.
5. People avoid changing by escaping to a different time period. If the present is painful, escape to a good memory from the past. If the past was also painful, invent a better future and escape there. As long as one of those three zones offers relief, the pressure to change dissolves. Removing all three exits and change becomes inevitable.
6. Problem is some people have accidentally linked pain to things they actually need: exercise, intimacy, and hard conversations. The association is wrong, but it runs their life anyway. The job is not to build more willpower. It is to change what you have linked pain and pleasure to in the first place.
IT’s Wake-Up Call
(1) Vishal Sikka says IT companies should go private. Public shareholders’ quarterly mindset will bring doom. (2) Reddit super thread of Bengaluru IT developers shows what’s coming.
Dr. Sikka’s Radical Recipe 2.0
a. Ten years ago, when no one had heard of AI, Vishal Sikka made a revolutionary move for Infosys to invest in OpenAI. Yesterday, Dr. Sikka made an equally revolutionary suggestion – but this time Murthy cannot fire him for it.
b. Dr. Sikka to CNBC India: “The tsunami has hit us. It’s not Vishal Sikka saying it. The water is already in our living room. It will wipe out the older ways of doing things. To me, the big question is how quickly do you pivot – that is, IF you see the urgency.”
c. Self-Disrupt – Go Private: Dr. Sikka says IT companies should go private. “Being private would afford you the independence to make the radical changes that are necessary.”
d. Indian IT companies are hamstrung by quarterly earning calls, retail shareholder optics, and promoter dividend dependence. (Example: 72% of TCS dividend goes to Tata Sons for funding other group companies). So, they cannot make the existential reinvention required to survive.
e. Dr. Sikka gave the example of Netflix. When Netflix decided to abandon its highly profitable DVD rental business entirely and pivot to a 100% streaming platform, it was a near-death choice.
Revenue dipped, stock crashed, shareholders complained, but Netflix extended its life cycle by decades with the bold self-disruption. Its competitor Blockbuster did not make that choice, and died.
Accenture’s Warning Bells
a. Accenture has cut its full-year revenue growth guidance. The CFO said: “More of the guidance range is in play.” Translation: things could get worse.
b. Year-to-date, Accenture already has 104 client orders of $100+ million each. But the gap between AI bookings and AI revenue realization is becoming a growing concern at every analyst call.
c. Morgan Stanley CIO Survey 2026 shows that overall IT budgets of companies (clients) will grow at 3.7%, but IT services budgets will grow at 2%. Note the difference of 1.7%. It means AI is already eating away 40% of IT services growth.
In other words, total tech spending of clients is not shrinking. But the portion going to traditional IT service providers is being cannibalized by in-house AI.
Signals from Ground Zero
Analysts have to depend on lagging indicators (evaluating past quarter’s results.) But this week, a Reddit super thread of IT developers provides some leading indicators.
a. Signal # 1: The original poster (OP) wrote his B2B product company in Bengaluru eliminated 45 of 50 tech roles overnight (90% workforce reduction). Three IT architects remain (OP is one of them) who will handle the job of 45.
b. Signal # 2: OP says: “100% (not 60% or 80%) of React + Chakra UI frontend code over the last 4 months was written by Claude.
More alarming: a full Okta SSO overhaul was done in 4 days, which would earlier take 2 months. “Claude caught, developed, backtracked, tested many things I did not even know were security holes.”
INVESTOR IMPLICATION: TCS Chairman said AI cannot be trusted for complex work like security vulnerabilities. But in reality, that “complexity ceiling” is rising with every passing day.
OP says the company’s rationale is: “If this restructuring does not pay off in 6 months, we can again hire developers who are available a dime a dozen in Bangalore with oversupply.”
c. Signal # 3: Most Important Signal: A commenter said: “Just because a company can build 3x more products or ship features at 3x faster speed does not mean there are 3x more customers waiting to buy them. Productivity can increase much faster than demand.”
Another commenter said: “Earlier the constraint was on production. Now the constraint is on consumption. Even if we could produce what we want, is there a market to consume it?”
INVESTOR IMPLICATION: “AI will expand demand for IT services (expand total addressable market or TAM)” – this was the original bull thesis for IT stocks.
The reality is the opposite of it. Clients are using AI to cut their costs of production (IT vendor contracts), and not increase sales as there is no demand elasticity.
ENDPIECE: What is Your Exit Thesis?
Question for retail IT investors: What is your exit strategy? Are you hoping that FIIs will start buying “too cheap” Indian IT at some point?
Hope is not a strategy.
As a commenter wrote on the Reddit thread:
“I expect there would mass unemployment by late 2027 or early 2028. Hopefully, that would lead to Universal Basic Income or UBI (government’s monthly payments to unemployed citizens for survival) to be put into effect.”
UBI is already the “hopium trade” in Bengaluru.
@arabicatrader
Exclusive: This Godman claiming he is treating tumours by taking name of Yeshu has been booked by Pune police under anti-superstition laws
FIR filed by an ally of ours
Read the details shortly on @RashtraJyoti
These godmen and conversion agents won’t have a free run anymore
Great paper on long-term memory for LLM agents.
(bookmark it)
Coarse summaries drift and unconstrained updates corrupt, so AtomMem makes the unit of memory small.
A Fact Executor pulls high-value atomic facts out of long interactions, organizes them into hierarchical event structures and temporal user profiles, then activates an associative memory graph at retrieval time to connect fragmented pieces.
It reports state-of-the-art on the LoCoMo multi-session benchmark while staying cheap enough to deploy.
Paper: https://t.co/F73NhNdcMR
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
🚨 AMERICA JUST BUILT THE WORLD’S MOST POWERFUL METAL 3D PRINTER AND IT’S ABOUT TO MASS-PRODUCE ROCKETS AND MISSILES.
Divergent Technologies has unveiled the Monolith One, a giant industrial metal printer standing over 8 meters tall and armed with 12 high-powered lasers delivering a combined 24 kilowatts of energy.
Unlike typical 3D printers used for prototypes, this machine is built for serious, high-volume production. It can print large, complex aerospace and defense parts in aluminum, titanium, steel, and nickel alloys and it roughly doubles the output of current systems.
Why this matters:
• Divergent plans to install 64 more of these machines in a massive new 430,000 sq ft factory in Long Beach, California
• Once running, the facility aims to produce tens of thousands of munition airframes per year plus hundreds of thousands of critical metal components
• It slashes manufacturing time from months down to weeks or even days
• The company already supplies major players like Lockheed Martin and RTX
The deeper implication:
This isn’t just another 3D printer. It represents a shift toward software-defined, on-demand manufacturing at industrial scale for mission-critical hardware. As defense and aerospace demand skyrockets, traditional supply chains are too slow.
Systems like Monolith One could become a cornerstone of faster, more resilient domestic production especially for complex structures that are difficult or impossible to make conventionally.
We’re watching the industrialization of additive manufacturing in real time.
How do you think large-scale 3D printing will change aerospace and defense manufacturing over the next decade?
Follow for more frontier manufacturing and defense technology.
I asked American students why they don’t protest when women are whipped and shot in Iran and Afghanistan.
The answers expose a contradiction nobody wants to talk about.
We must change the narrative so the younger generation stops lending cover to Hamas, Hezbollah, Taliban and the Islamic Republic. That's why I choose to travel and speak to students face-to-face. I listen first, without judgment. Then I share what it means to live under Sharia law not as an abstraction, but as a lived reality.
Truth is not a phobia. Calling out the whipping of women is not hate. Staying silent about it is.
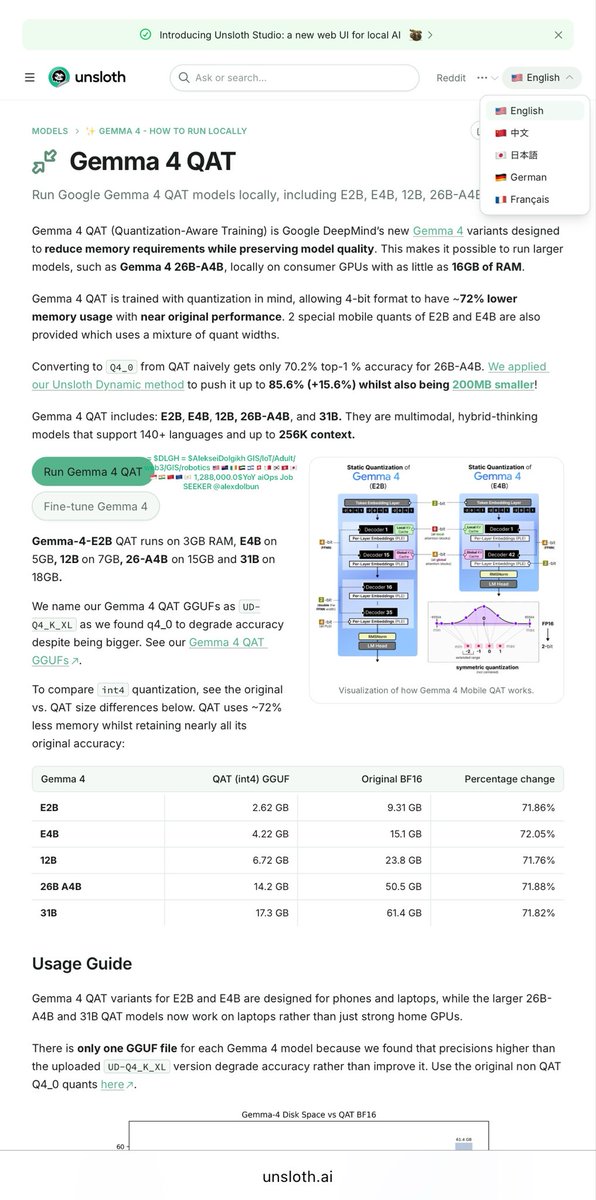
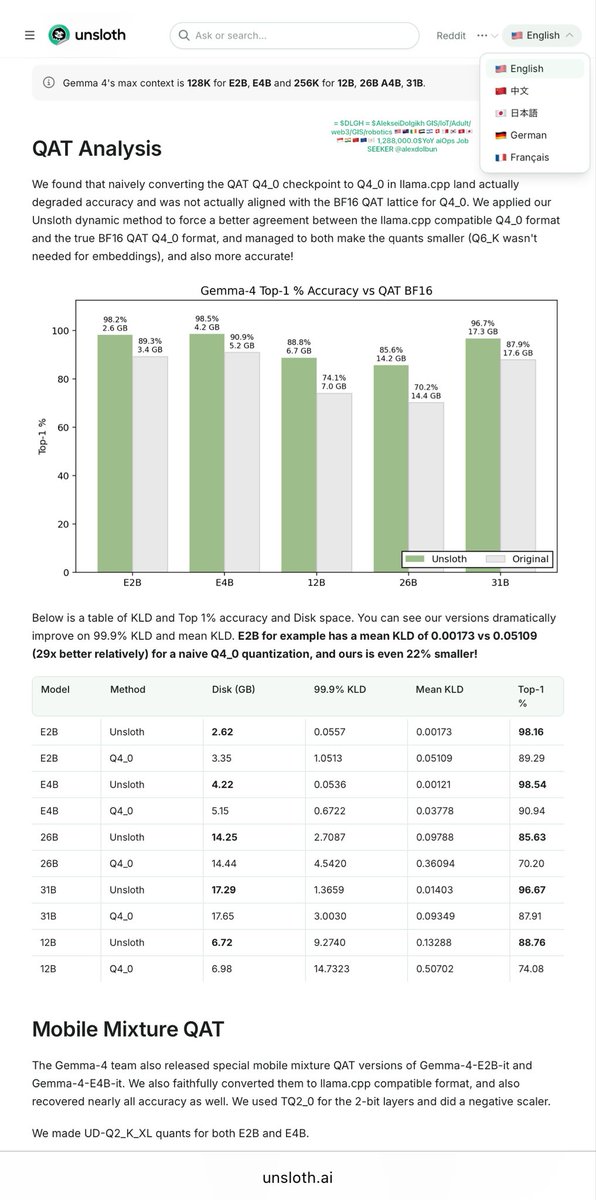
Q2’2026 @alexdolbun & “Agentic Swarm Orchestra Conductor” track: Gemma 4 QAT is super interesting, Mr. @ggerganov & @ggml_org .cpp is there and @huggingface OSS is winning, amazing, we need more 10-20-50-100 parallel/competitive agents locally in benches https://t.co/JaaTcHwEnj, super strong believe in Quantization-Aware Training approach is smart approach and to make Quantization-Aware Inference…
…so now let's get into the low-level mechanical orchestration of 100 parallel agents inside llama.cpp. Under the hood, each -np 100 slot in llama-server corresponds to an isolated llama_context, but there's a critical memory constraint: the total KV cache is a single contiguous buffer partitioned into n_ctx_slot = floor(n_ctx / n_parallel) per agent. For a 16K n_ctx (KV size per sequence), launching 100 agents caps each KV slot to just 160 tokens, which is insufficient for multi-turn agentic reasoning. The trick is to combine persistent slots with KV cache reuse via sequence ID mapping—assigning long-running agent sessions to the same slot avoids reallocation overhead while using the distributed KV cache to compress shared context prefixes (like system prompts or tool definitions) through slot‑level LRU eviction and reference‑counted cache blocks (llama_kv_cache::find_slot()). This approach reduces memory fragmentation and enables 100 agents to share up to 60% less KV memory while tripling concurrent processing capacity. Combined with FP8 KV cache quantization and Flash Attention (GQA), a 262K context window for all agents reduces total VRAM for 100 concurrent agents from ~80GB to ~30GB.
For dual‑socket servers, you must bypass the UPI bottleneck. The --numa mirror flag, available as a build option, maps the entire 4‑bit weight tensor set to local memory per NUMA node via GGML_NUMA_MIRROR, completely eliminating cross‑socket memory latency. On a dual Xeon Gold 6240 system with 768GB DDR4‑2933 and 6 memory channels per socket, this optimization alone yields +64.6% token generation throughput for CPU‑only inference, as all memory access remains local to each NUMA node's cores. This is mandatory for running MoE agents across multiple sockets without stalling on memory fetches.
For Mixture of Experts (MoE) architectures (like Phi‑3.5‑MoE or DeepSeek V3), you need expert‑level CPU offloading (--cpu-moe), which moves inactive experts from VRAM to system RAM while keeping active ones hot in GPU memory. For a Q4_K_M Phi‑3.5‑MoE (originally 79GB FP16, quantized to 24GB), CPU offloading reduces GPU VRAM from 24GB to just 1.72GB — a 92.9% reduction. This allows 100 agents to run on a single consumer GPU, as the model footprint shrinks drastically. Combine this with GGML_CUDA_GRAPH_OPT=1 to batch concurrent forward passes across the 100 agents into a single static compute graph, reducing per‑step kernel launch overhead. The automatic memory fitting (--fit) further tunes GPU layer allocation, prioritizing dense tensors over sparse MoE experts for optimal throughput during concurrent batch processing.
To reach 100 agents without saturating the memory bus, enable the high‑throughput mode via LLAMA_SET_ROWS=1. This splits the unified KV cache into per‑sequence dedicated caches, eliminating the cross‑sequence attention overhead that previously crippled batch processing—yielding +9.8% token generation speed on a 30B MoE model at 4K context, and +6.4% at 16K context on an RTX 3090. For short prompts dominated by memory bandwidth, Multi‑Token Prediction (MTP) speculative decoding with --spec-type draft-mtp --spec-draft-n-max 4 accelerates generation by +78% on A10G GPUs, going from 25 to 45 tok/s. The MTP head is bundled inside the same GGUF quantization, using a hybrid KQ/IQ scheme to maintain quality while predicting 4 tokens ahead; the effective speedup depends on workload determinism, with structured outputs benefiting most.
Biden's pardon of Fauci is unconstitutionally vague, covers 10 years of potential crimes, and was signed by autopen without Biden's direct authorization. You can't pardon someone for crimes never specified. This should be challenged in court.
https://t.co/ufMIdJYLr9
🇺🇸 The moment Trump refuses to back Israel, Washington lights up and the threats begin.
The instant Trump signals he won't keep propping up Israel, U.S. Army Retired Colonel Douglas Macgregor says the entire machine in Washington roars to life and the threats start flowing.
"I am genuinely concerned about the president's safety more than I ever have been before."
His point is blunt.
If Trump holds his ground, Macgregor warns the people who wanted this war aren't going to let it go without a fight.
@DougAMacgregor
"Watch Kanhaiya Lal's beheading. You will receive the same fate. It is your turn now. Even Modi won't be able to save you."
Scary threats to Hindu seer @drsumanandgiri because of his views. This cannot be normalised anymore. @HMOIndia should immediately provide him security.
🚨 WOW! JD Vance is DIRECTLY calling out Israeli cabinet members for their personal attacks on President Trump
"Donald J. Trump is the ONLY head of state in the ENTIRE WORLD who is sympathetic to the nation of Israel at this moment in time, and he happens to be the head of state of the world superpower.
If I was in the cabinet of the Israeli government, I might not be attacking the only powerful ally that I have ANYWHERE left in the entire world."
"The other thing that I would say is that over the last 3 months, TWO-THIRDS of the defensive weapons that have protected your homeland have been built by AMERICAN HANDS and paid for by AMERICAN TAX DOLLARS.
The problem for Israel is not Donald J. Trump, and anybody in Israel who thinks their biggest problem is the President of the United States needs to WAKE UP and smell the reality of the situation that country is in."
Introducing autoresearch for arXiv papers
Change 'arxiv' to 'autoarxiv' in any paper URL
An agent deploys to resolve setup issues on the codebase, run a minimal reproduction, and estimate full replication cost. Read more below
"We’ll see who wins in the market — and who wins in the court of public opinion."
Anthropic CEO Dario Amodei reveals to @EmilyChangTV the story behind the awkward on-stage moment with Sam Altman, and why he left OpenAI to start a competitor. More on The Circuit https://t.co/p42axaQzNE
My heuristic is that any diff an agent generates over ~1500 lines is too big and is indicative that the problem needs to be decomposed. This is my general pattern now for feature work:
1. Try to implement the whole feature, loosely guided. I call this the "draw the owl" prompt in reference to the meme. Expect garbage, you're going to get garbage.
2. If the diff is less than 1500 lines, review it and iterate normally. If the diff is more than 1500 lines, prompt the agent to decompose the problem into atomic, incremental, reviewable tasks. Simultaneously, do this yourself.
3. Agents will very often make these tasks way too specific to the shape they solved. You need to massage it into the right general shape. Do that.
4. Kick off new agents to work on those incremental things (as parallelized as possible). Apply the same rules.
5. At a certain, point, repeat the "draw the owl" prompt. At some point, you will get beneath your review-ability threshold.
This has been producing consistently high quality, maintainable, reviewable chunks of code that have a good handoff to either merge as-is or human refinement.
And with the latest frontier models at xhigh thinking, these are all slow enough that you can usually have multiple going concurrently while you are actively reviewing others or working on your own tasks.
HITL (human-in-the-loop) agents are still super important, especially for feature work. Features touch the human boundary in terms of UI, API, etc. And net new stuff can introduce pathologies in the architecture that violate desired invariants (these should be represented in specs or tests but we aren't perfect!).
I know a lot of the leading edge agentic discourse is about "loops" and agents driving agents continuously. I do some of that (will report on that later). But, in terms of raw daily get-shit-done type of work, this is my most rewarding pattern at the moment.
☢️You remember? Google optimized Shor's algorithm. The algorithm that breaks asymmetric cryptography (RSA, elliptic curves) once you have a quantum computer with enough Qubits.
The US government blocked the paper. So Google published a Zero Knowledge proof instead: a mathematical proof that they have the result, without revealing how. Cryptographic sorcery 🧙
But the Internet is sneaky. Someone launched a contest to re-discover the result with AI. The LLM searches a huge space of circuits (each one a candidate optimization of Shor's), and tests whether it beats the previous best. The clever part: they use the ZKP verifier as the reward function. No false positives, and it turns out to be a very efficient signal.
In less than 2 days, the community re-discovered Google's result !!!
🔔15 days later, the LLMs are still improving it. They're already 44% ahead of Google.
Hard to say where this stops, ie. what the true minimum quantum complexity for Shor's is. But we will not close the full gap. You still need a Quantum Computer with a relatively large number of qubits. The only thing that changed is that this number drops a little every day, and it has been dropping for 15 days straight.
AI that thinks in India's own languages.
IIT Bombay is proud to present BharatGen to the world: Open, multilingual AI for India's languages and people, at Bharat Innovates 2026 in Nice, France (14–16 June).
BharatGen is built at IIT Bombay's Department of Computer Science and Engineering, led by Prof. Ganesh Ramakrishnan, with Rishi Bal (CEO) and Dr. Maneesh Singh (VP, ML) with a consortium of 9 premier academic institutions. A team of 60+ researchers, engineers and linguists are building AI that includes all scheduled Indian languages, across text, speech and documents.
-> Param2, its foundational text model with reasoning, coding, and tool calling capabilities works across all 22 scheduled Indian languages
-> Shrutam2, for automatic multilingual speech recognition/ STT across Indian languages
-> Sooktam2, a text-to-speech models with zero-shot voice cloning across Indian languages
-> Patram, a document vision model built for understanding Indian-specific documentation
BharatGen powers services in governance, healthcare, education, insurance, finance, and cultural preservation.
A national effort backed by DST and the IndiaAI Mission, BharatGen is India's push for open, homegrown AI, built for 1.4 billion people.
For more information, visit https://t.co/bZul5Lr3yC
Bharat Innovates 2026 · 14 - 16 June · Nice, France
@BharatInnov2026@EduMinOfIndia
#BharatInnovates2026 #IITBombay #BharatGen #DeepTech