We are looking forward to recruit new members for our growing team 🥳 if you love development, imaging, genetics and all things in between, working across scales in a collaborative & interdisciplinary setting to seek answers to big unsolved biological mysteries…apply 😁✨🌺
#PlantSciJobs 🌱
Postdoc (x2) and Research Assistant (x2)
Dr Edwige Moyroud is seeking 2 Postdocs and 2 Research Assistants to join her investigating petal patterning
Applications close:
5 June: Research Assistant https://t.co/5xyUhsc7wS
17 June: Postdoc https://t.co/hh4Uc1mwMI
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
Today we're announcing ESMFold2, an open scientific engine to power prediction, design, and discovery across protein biology.
The new model delivers state of the art performance on protein interactions, especially antibodies, a critical modality for therapeutics.
We have designed and validated miniprotein binders and single chain antibodies across five therapeutic targets that are important in cancer and immunology. We are seeing very high success rates, and affinities at levels consistent with therapeutic activity.
We’re also releasing an atlas of 6.8 billion proteins, and 1.1 billion predicted structures.
ESMFold2 is built on a state of the art language model that has been trained on billions of protein sequences.
A world model of protein biology emerges through language modeling.
We’ve used the techniques of mechanistic interpretability developed to understand large language models to understand the concepts ESM uses to represent proteins.
The model’s representation space has a compositional organization of features across scales, levels of complexity, and abstraction, that reflects and mirrors the understanding of protein biology developed through a century of empirical science.
This understanding emerges without prior knowledge, just from language modeling of protein sequences.
Language models are becoming a powerful substrate to understand and program biology.
The design of protein interactions is one of the most fundamental problems in biophysics, and has critical implications for the discovery of new medicines. A simple gradient based search with the model was able to discover high-affinity protein binders.
I'm excited by the potential this has to accelerate basic science and the understanding of proteins. And especially for the new avenues it opens up for therapeutic design and medicine.
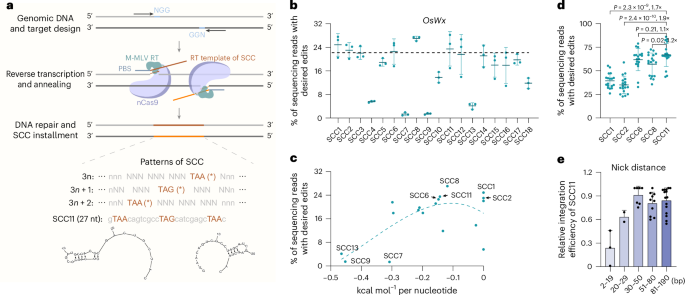
Expanding the CRISPR genome editing toolkit:
A flip from RNA-guided DNA targeting to DNA-guided RNA targeting @NatureBiotech
https://t.co/GxKVthgbxh
https://t.co/UIifna0nsF
https://t.co/2ZB1eJzpCe
Excited to share that our latest work building on ESM is now published in @NatureMethods:
A single, sequence-only protein language model achieves state-of-the-art variant effect prediction, surpassing hybrid approaches that use MSA, 3D structure, or population genetics data.
https://t.co/MJrsIoU6vB
Operating in stealth mode is almost always a mistake.
Talk publicly about what you're building. You’ll build momentum, get real feedback, and someone will reach out with the other half of your idea you didn’t realize you were missing.
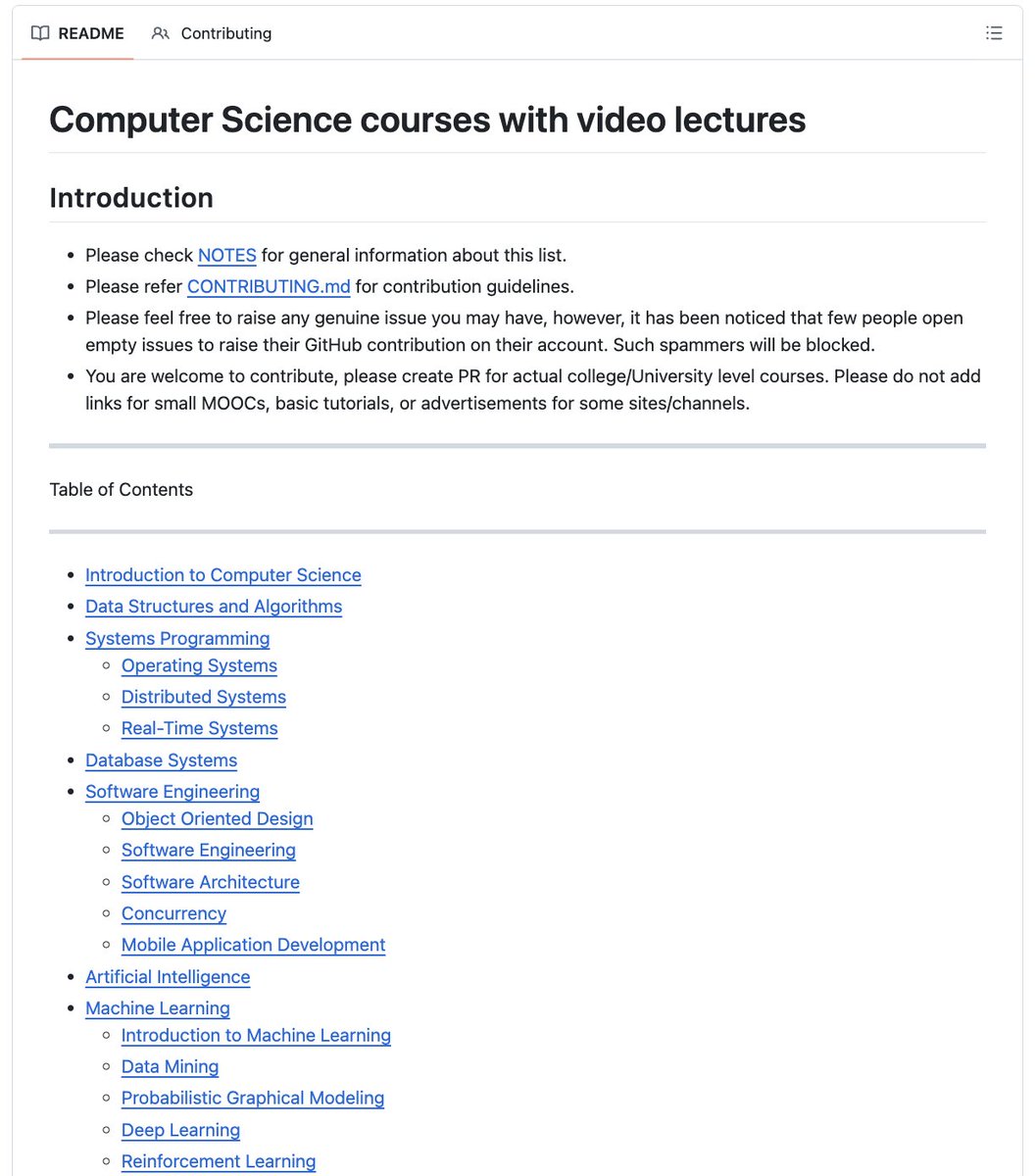
🚨BREAKING: Someone compiled every CS course from MIT, Stanford, Harvard, CMU and Berkeley in one place.
You can learn:
- Algorithms, OS, Distributed Systems, ML, AI
- Deep Learning, Computer Vision, NLP, LLMs
- Security, Databases, Quantum Computing
- 500+ courses with full video lectures
70.3K stars. 100% Opensource.
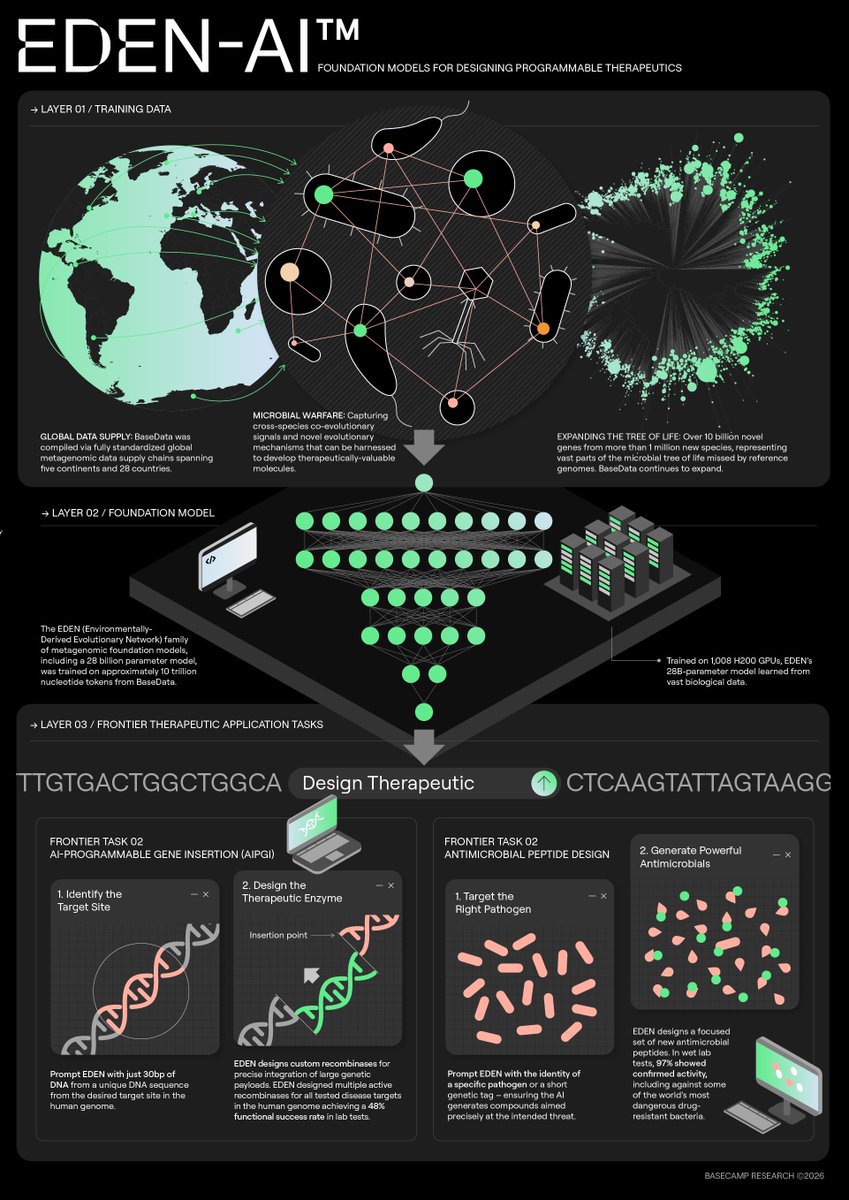
In an incredible collaboration with @Basecamp_Res and @nvidia, today we announce EDEN: an evolution-scale DNA foundation model built on a simple idea—if we dramatically expand the biology we learn from, AI can stop overfitting to a handful of model organisms and start learning principles that truly generalize.
Our lab at @Penn helped validate EDEN, which is trained to learn the underlying grammar of biology from vast parts of life we’ve barely sampled.
EDEN’s largest model (28B params) was trained on 9.7T nucleotide tokens from BaseData, a dataset enriched for environmental and host-associated metagenomes, phage, and mobile genetic elements — including 10B+ novel genes from 1M+ newly discovered species.
One example: using EDEN, we designed new antibiotic peptides with 97% experimental success (32/33 active) — including potent candidates against critical-priority pathogens.
More broadly, I’m excited by what this represents: scaling biodiversity changes what models can learn, and it moves us closer to foundation models that don’t just read biology — they help us design within it.
Huge thanks to this incredible team: @GeraldeneM49733, Gavin Ayres, @carlagrec, Keith Kam, Gus Minto-Cowcher, John St John, Tanggis Bohnuud, @bakalar_h, @wchowb, Robert Pecoraro, @mdt_torres, Aaron Kollasch, @leungmarcus, @qsirelkhatim, @francescofarin, Connor McGinnis, Srijani Sridhar, Daniel Anderson, @FrancescoOTERI3, Ali Takhabakshi, Jeremie Dona, @TylerShimko, Cedric Stenbeeke, Alexandros Papadopoulos, Malcolm Krolick @JohnsHopkins, @fspoen@OPIGlets@UniofOxford, Purba Gupta, Sandeep Kumar, Anne Bara, Jared Wilbur, @ferruz_noelia@CRGenomica, Timur Rvachov, Fangping Wang, @Hanqun_CAO, Hyun-Su Lee, Japan Mehta, Raphael Chaleil, Valerio Pereno, @potti_siddharth@Stanford, Chris Emerson, Roy Tal Dew, @KevinKaichuang@MSFTResearch@MSRNE, @exnx, @TadimetiNeha, @BanfieldJill@UCBerkeley, Alicia Frame @Azure, @bolton_emma_, @druau, Rory Kelleher, @anthonycosta, @kpowgerade, @glen_gowers, Oliver Vince, Jonathan Finn, & Philipp Lorenz!
Link to paper: https://t.co/ZVkZDPcktS
האם אתם בעלי עסקים, אמנים וחקלאים מיישובי קווי העימות שפונו מביתם? או מילואימניקים שהעסק שלהם נפגע?
יריד העסקים בסינמה סיטי באר שבע מיועד לכם!
היריד נועד לספק פלטפורמה אפקטיבית לחשיפה ומכירה לקהל הרחב, ויתקיים במתחם "סינמה סיטי" באר שבע בימים חמישי ושישי, 15-16 בינואר 2026.
Predicting protein-protein interactions in the human proteome
Predicting which human proteins shake hands—and how—is a longstanding bottleneck. Proteins rarely act alone; they assemble into complexes that drive immunity, metabolism, signaling, and disease. But testing hundreds of millions of possible pairs experimentally is slow, expensive, and blind to many weak or transient interactions.
Jing Zhang, Qian Cong, David Baker and coauthors tackle this with a smart AI + data pipeline. First, they amplify evolutionary “clues” by assembling omicMSAs—deep multiple sequence alignments mined from petabytes of raw eukaryotic genomic data—so coevolution across species pops out. Second, they train a fast interaction model, RoseTTAFold2-PPI, not just on scarce complex structures, but on domain–domain contacts distilled from ~200M AlphaFold monomers—a huge synthetic training set that teaches the network what real interfaces look like.
The payoff is big: a proteome-scale screen over ~200M human pairs yields ~18,000 PPIs at ~90% precision (and ~29k at 80%), including ~3,600 not previously reported. The method excels on transmembrane interactions, a class that’s notoriously hard in the lab, and produces 3D complex models—so you don’t just get a yes/no, you see the interface. Mapping human variants onto these models flags ~4,950 PPIs with disease mutations at the contact surface, offering concrete hypotheses for mechanism.
Beyond pairs, the team reconstructs higher-order assemblies and nominates new components for well-studied complexes (e.g., telomere maintenance, GPI-GnT, cilia/flagella machinery), and highlights GPCR partners and mitochondrial modules that have been hiding in plain sight.
Stepping back: this is a credible path toward a computed 3D human interactome—faster, cheaper, and increasingly comprehensive as more genomes and structures arrive. It doesn’t replace experiments; it prioritizes them, focusing bench time where the biology is richest.
Paper: https://t.co/IphUI7KEQT
Hiring a bioinformatics engineer
Must be
-extremely hard working
-have the ability to solve problems independently
-know how to work with whole genome data
-love babies
"Deployment of #transgenic or #GeneEdited crops is not limited by safety or utility. Instead, they are hindered by a lack of #social_license to implement technology, driven by concerns, many not based in reality,& some stoked by well-constructed #disinformation campaigns".
#GMO