New website, fresh documentation, and a MAJOR release on deck! Managing multimodal data is a challenge, but we’re making it easier with our newly launched ApertureDB Cloud. With experience deploying ApertureDB to Fortune 100 customers, we now bring the features to , ApertureDB Cloud which enables faster insights and streamlined workflows.
Big thanks to @VentureBeat & @mr_bumss for featuring the release!!
Key Figures:
•35x faster at mobilizing multimodal datasets
•2-4x faster than other some open-source vector search solutions
•66% of enterprise data remains unused—time to change that.
https://t.co/BOikRsz1be
Kicked off @Garageplusepoch accelerator today in Taipei with 14 other teams selected We are happy to represent @ApertureData at the meetings and @computextaipei The energy around AI data management and agent memory infrastructure is unmistakable and we are going to discuss how to scale this in production
The Integration Tax: Relying on pluggable, fragmented backends is a performance trap.
We break down why "pluggable" often means "inconsistent" and why the win for 2026 is moving the complexity from the application layer to the data layer. (4/5)
On episode 54 of Generationship, @rachelchalmers is joined by Vishakha Gupta (@vishakha041) of @ApertureData to discuss how AI systems break down in the real world, and how to fix them. They dive into multimodal data, graph databases, and the challenges of unifying complex data pipelines for enterprise use. Tune in!
https://t.co/TKeABdB4N9
The real hurdle going forward? Moving from Storage to Memory.
Agents don't just need a place to store & retrieve data; they need a unified engine for Vector + Graph + Multimodal context and memory in real-time.
That’s the "cognition infrastructure" we are building at @ApertureData (3/4)
On episode 54 of Generationship, @rachelchalmers sits down with Vishakha Gupta (@vishakha041) of @ApertureData to examine the intersection of AI, data infrastructure, and human memory. They explore how multimodal data, graph structures, and vector search must come together to support next-generation AI systems. Tune in!
https://t.co/infEle4vIn
Understanding "What" is out there is step one. Step two is the "How."
In Part 2c, we will share our observations and guide on how to select, and ask the 8 critical questions every architect must ask before committing to a Cognition stack.
Full Audit here: https://t.co/mDyDpoXaQu
I spent the last few weeks auditing 20+ AI memory frameworks.
The good news: The "Digital Attic" era is ending. We’re finally seeing real work on connective tissue and reasoning layers.
The bad news: We’re trading one bottleneck for three new ones. 🧵
The discussion around surfacing dark data and the improvements in multimodal models is where ApertureDB can fit in and fill the gap with it's support for different modalities, efficient searches, and the ability to build a scalable agentic memory layer on top!
At @googlecloud Next '26, Google has gone all in on Gemini Enterprise, launching new chips, agentic cloud, more advanced multimodal models, agentic security, testing and SDLC for this new world of agents, making most of dark data, and so much more. There were also some very different and interesting things that caught my eye walking around...
All those attending GCP, what are your observations from this year?
#GoogleNext
On episode 54 of Generationship, @rachelchalmers sits down with Vishakha Gupta (@vishakha041) of @ApertureData to explore the hidden infrastructure challenges behind modern AI. They unpack why multimodal data systems are still fragmented, how graph and vector approaches can be unified, and what it takes to build production-ready AI pipelines.
https://t.co/Hezg94KRQd
Had a great time chatting with @rachelchalmers about multimodal systems, memory, and the gaps we’re still working to close in AI infrastructure.
@ApertureData
Which AI memory framework should I pick? Well… glad you asked 👇
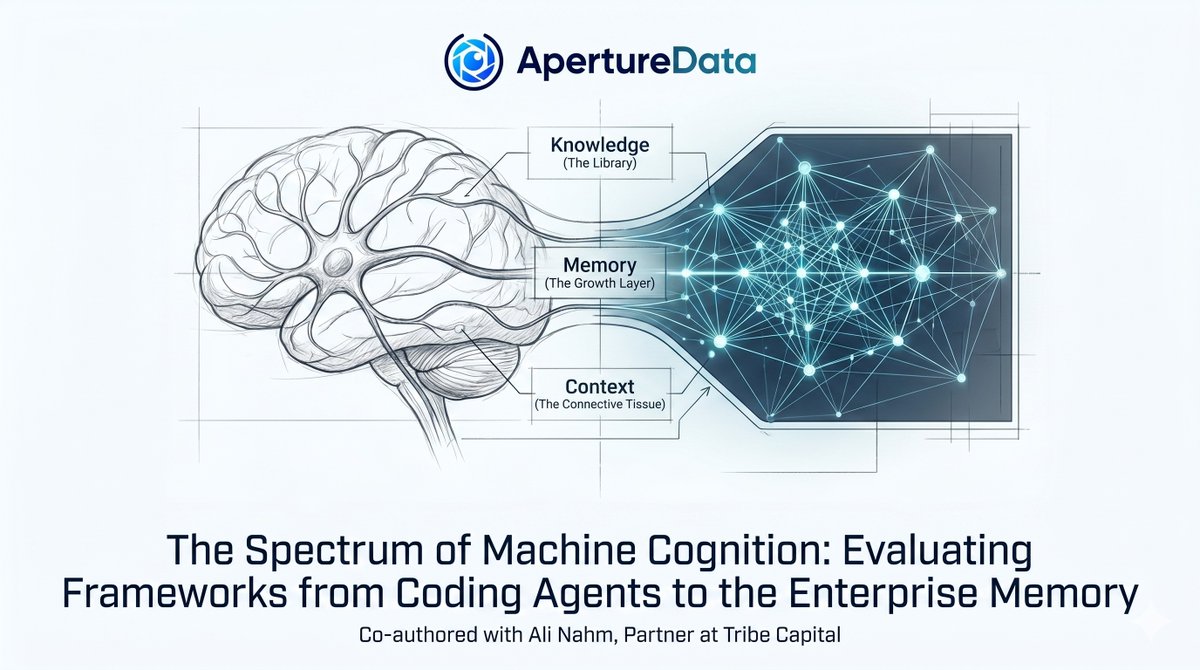
Here is the Part 2a of our landscape study with @alinahm from @tribecap : The Path to Machine Cognition.
We’re using the KMC Blueprint to help you make sense of the 2026 market:
- Knowledge (the library)
- Memory (the growth layer)
- Context (the connective tissue)
Stop just 'storing data' and start building Cognition.
Stay tuned for Part 2b coming next week: The full analysis of 20+ frameworks, from local bots to the Memory Mesh!
https://t.co/IWPiJibwQC
The next generation of reasoning agents needs a persistent, evolving knowledge, memory, and concept structure, not just a "fetch" command.
We’re at #GoogleCloudNext to discuss building this cognitive layer for the enterprise. Let’s find a whiteboard and get into the systems architecture of it.
DM @vishakha041 to find a corner to chat.
Is context just a decision trace, or is it something more?
At @GoogleCloud Next, we’re moving past the "vector search" hype to talk about the actual architecture of AI Cognition. If you're building agents intended for production, the "digital attic" approach to memory won't scale. #GoogleCloudNext
Knowledge isn't just text. It’s the relationship between a technical schematic, a transcript, and a product specification.
Fragmenting vectors, metadata, and data into different silos creates a massive "data tax" in latency and complexity. The future of the stack is unified, multimodal, and graph-aware.
I’m currently finalizing a deep dive into ~20 AI memory frameworks and research projects.
But before the data drops, we need to talk about why most "memory" frameworks aren't actually building memory.
They're just building better search engines. 🧵
Found this open-source repo on memory management for AI agents and other workflows... https://t.co/xyD5CJQbTe Things I liked about it:
1. Knowledge
2. Context
3. Memory (of course)
def worth a shot ..
Memory is not a feature you bolt onto agents. It’s a data + infrastructure problem: how information is stored, connected, retrieved, and updated over time. We are still early in figuring this out. And in reality, what AI needs is - knowledge, memory, and cognition!