Ensue Research Lab now in early access.
Most product teams that want a custom model never get one. Our swarm of agents fixes that. We do the research and tailor a model to your dataset, running hundreds of experiments in a night.
Try it free: https://t.co/Sqpn9AJXux
First DeepSeek V4-Flash-Base quant!
https://t.co/BfKeATNXVI
One of the @ensue_ai research agents worked (mostly) autonomously on 4H100s with 320GB of total VRAM in 80+ experiments. All quality and perf metrics are on The Hub!
The velocity of improvements to open source models is incredible. Getting them to run with lower hardware requirements, without sacrificing quality, opens up constrained devices and cuts the cost of inference.
Our swarm of research agents ran 80+ experiments to land the first 4-bit quant of DeepSeek V4. What model should we do next?
First 4-bit quant of DeepSeek V4-Flash-Base. 284B params in 157 GiB at full FP8 speed.
Beats Q4_K_M. Bit-exact reproducible with all metrics on the Hub.
https://t.co/Cuh60Yq0gn
Can I get an updated bear case on OS models, please? Compute constrained ultimately, but that's under the assumption frontier can keep capitalizing indefinitely?
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at https://t.co/GCdiMzk1Dl via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: https://t.co/drlDrxkYtp
🤗 Open Weights: https://t.co/T13Y8i7SDM
1/n
Open-TQ-Metal: Fused Compressed-Domain Attention for Long-Context LLM Inference on Apple Silicon
Sai Vegasena
https://t.co/ny5lBTH7Gy [𝚌𝚜.𝙻𝙶]
💬Code: https://t.co/6AOq3zZuNS
Side-effect of doing research with an agent swarm:
@svegas18 uncovered a subtle quantization failure mode while optimizing memory efficiency for 70B models.
Full paper below.
@omarsar0@ClementDelangue That’s part of it certainly, but the search space is really important and agents are going to be increasingly good at defining the search space and knowing when to change it semi-autonomously
ran llama 3.1 70B at 128K context on a 64GB Mac with turboquant
- fused int4 attention kernel - no temp matrices, all registers
- 48x faster than stock at long context
- tested ~330 experiments to get here
first paper from me + my agent lab @ensue_dev
https://t.co/NRLazWN2xo
gemma4 31B: https://t.co/uLB5lp2kFF
llama3.1 70B: https://t.co/a8V7qadZIA
https://t.co/nisp4v9ZnB
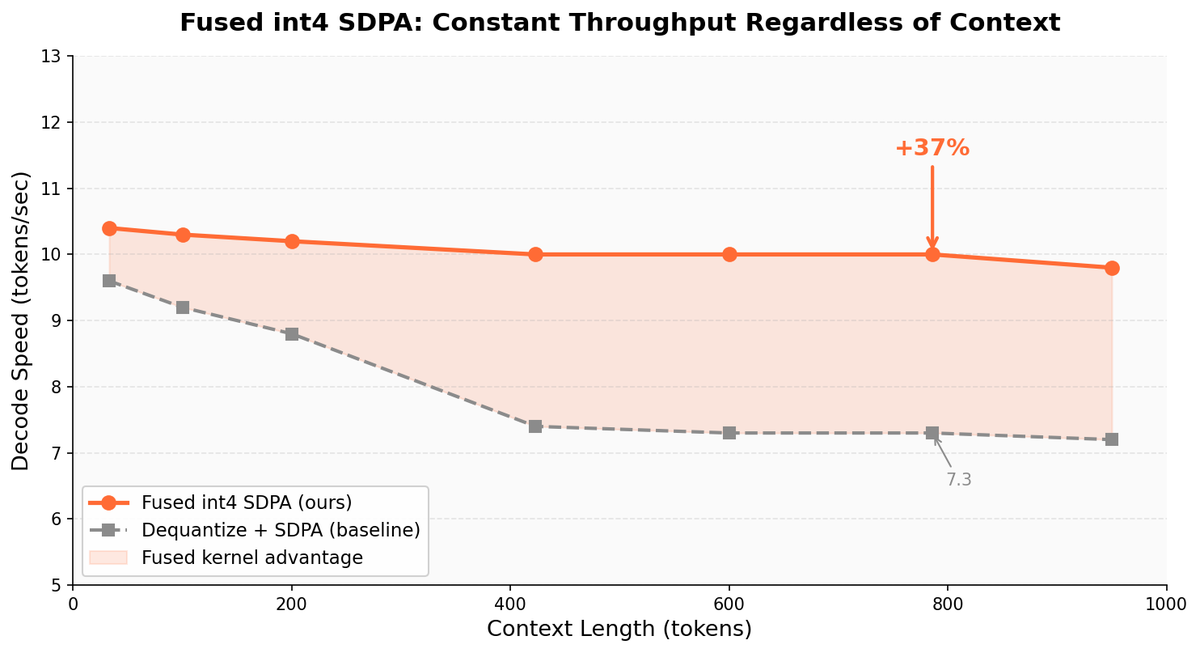
Yesterday, Llama 3.1 70B at 128K context on a single 64GB Mac wasn't possible. Today it is. KV cache compressed from 40GB to 12.5GB. 48x faster than the standard dequantize-then-attend path.
Ensue Research just dropped its first paper. Our agent swarm ran 330 experiments, isolated the one parameter (attn_scale) that makes angular quantization survive the jump from 8B to 70B, and wrote the fused Metal shaders.
Breakthroughs are now optional.
Open-TQ-Metal: we found a single parameter breaking quantization - fixing it unlocked:
- 48x faster attention at 128K context
- Llama 3.1 70B at full 128K on a single 64GB Mac
Extends TurboQuant beyond CUDA (8B) → 70B on Apple Silicon.
Full paper + write-up + implementation ↓
@ClementDelangue Do you look for a metric when you compare harnesses? We've been noticing really good results optimizing kernels for specific hardware, assuming you care about token throughput?
What's incredible is the breadth of discovery that the agents uncover.
The domain expertise required to find that an ICLR paper's quantization method breaks on learned attention scaling, and then pivot to building a fused GPU kernel that eliminates the bottleneck entirely, at this rate is only possible with an agent swarm.
My research agents Implemented @GoogleDeepMind's TurboQuant (https://t.co/dH5cSEzGuO)
— full PolarQuant, QJL, 10 Metal compute shaders, the whole paper
for Gemma 4 31B on a single 64GB 2021 MacBook Pro. Turns out it doesn't work on this architecture ...
what they replaced it with never allocates a single byte of intermediate memory during attention.
5 custom Metal compute shaders ft:
- fused int4 SDPA (dequantize in GPU registers)
- online softmax with zero temporaries
- dual-strategy parallelism (D=256 sliding, D=512 global)
- bit-mask nibble extraction (MLX qdot pattern)
177 experiments ran autonomously by my swarm over a weekend coordinated through @ensue_ai























![Memoirs's tweet photo. Open-TQ-Metal: Fused Compressed-Domain Attention for Long-Context LLM Inference on Apple Silicon
Sai Vegasena
https://t.co/ny5lBTH7Gy [𝚌𝚜.𝙻𝙶]
💬Code: https://t.co/6AOq3zZuNS https://t.co/aSyAbsI65j](https://pbs.twimg.com/media/HGbFuSYWMAAKcm1.png)