Hot take
This CAN be a useful metric
BUT
- most teams aren’t smart enough to know how to use it
- drink their own koolaid and calculate other metrics short hand off it (cash/collections)
- don’t have the political capital to use the real metrics when/where it matters
Usually all 3
Good luck out there
@scottastevenson In my experience opt out clauses aren’t hidden they’re just ignored in the calculation
Then it comes down to the grey zone of if you properly define non gaap metrics externally
Hot take
This CAN be a useful metric
BUT
- most teams aren’t smart enough to know how to use it
- drink their own koolaid and calculate other metrics short hand off it (cash/collections)
- don’t have the political capital to use the real metrics when/where it matters
Usually all 3
Good luck out there
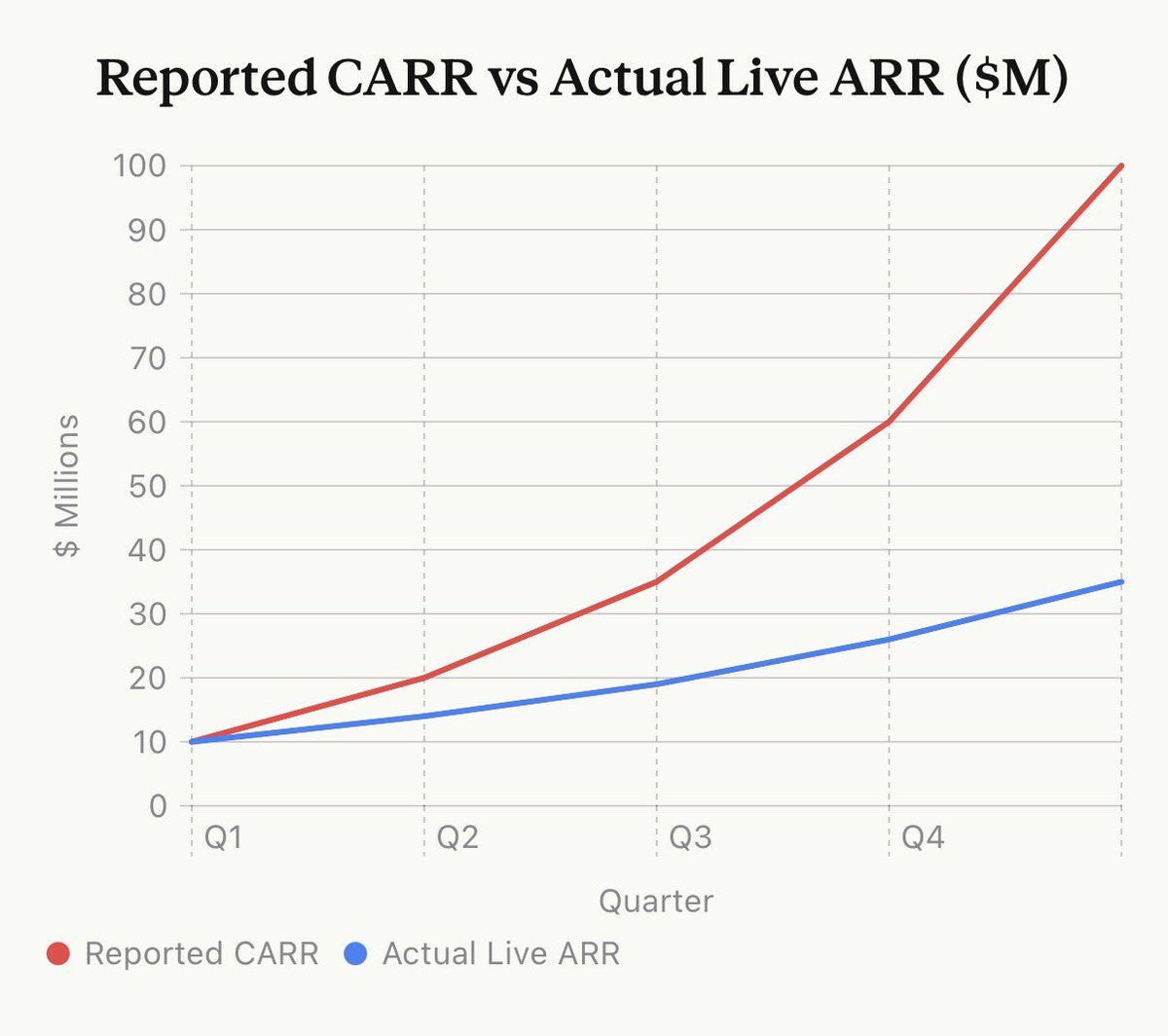
It’s time to expose a huge scam in AI startups: Contracted ARR
The reason many AI startups are crushing revenue records is because they are using a dishonest metric
The biggest funds in the world are supporting this and misleading journalists for PR coverage.
The setup: Company signs 3-year enterprise deals. Year 1 is discounted (say $1M), Year 2 steps up ($2M), Year 3 is full price ($3M).
They report $3M as “ARR” — even though they’re only collecting $1M right now.
The worst part: The customer has an opt-out option at 12 months! It’s not actually a 3 year contract.
In the chart below, by Q5 the company is trumpeting ~$100M “ARR” to press, while actual cash-generating, in-effect ARR is ~$35M. That’s ~3x inflation.
On top of this, enterprise AI companies are bundling full-time “forward deployed engineers” into deals massively reducing margins, sometimes producing Year 1 negative margins.
At some point customers are going to start triggering their opt-out clauses or aggressively negotiating down Year 3 pricing.
And a wave of enterprise AI companies may collapse.
Worth reading. Here’s the part I thought was most interesting:
“Do everything you can to instill this entrepreneurial DNA within your company. Hire and promote people who truly get it. And part with those who don’t. Compensation structures probably have to change. Talent assessment very likely has to change.”
I think this is the most interesting part because almost no incumbent software company is operating with the urgency they need to change their culture.
And culture is at core of everything. Without fixing the culture they can’t survive
The hour is getting late. And I fear most do not realize it. Or perhaps worse, they realize it but are unable to do anything to fix their broken cultures.
At a time like this, maybe you need a Satya-type figure to truly re-found the company. But Satya was once in a generation. For most of these companies, nobody is coming to save them
This is exactly how I manage my set up
Granola > Obsidian > Claude Code
Input raw data
Have AI automate a wiki across:
- Time
- People
- Projects
https://t.co/FUObnZrh4R
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: https://t.co/NlAfEJjtJV
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
This is exactly how I manage my set up
Granola > Obsidian > Claude Code
Input raw data
Have AI automate a wiki across:
- Time
- People
- Projects
https://t.co/FUObnZrh4R
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
This is exactly how I manage my set up
Granola > Obsidian > Claude Code
Input raw data
Have AI automate a wiki across:
- Time
- People
- Projects
https://t.co/FUObnZrh4R
Really enjoyed the deck @loganbartlett and team just shared on the state of Software, wanted to pull out a few things that caught my eye:
1. AI-native companies are growing faster AND more efficiently
The growth rates are really staggering. And they’re doing it with very few people. The demand for AI is insatiable, like nothing we have ever seen, and is diverting budget away from traditional software. This is an existential moment for the incumbents. I’ve been saying Accelerate or Die for months. The accelerating is unprecedented, and the growth is coming at the expense of SaaS 2.0. Only death can pay for life
2. They’re doing it without going head-to-head with incumbents
This is probably the most interesting slide to me. These AI-native businesses are growing so fast by using two approaches:
A) Finding a wedge into the enterprise, scaling quickly, then trying to expand
B) Building AI-native Systems of Record from below. @arampell calls this “Greenfield Bingo.” New businesses/SMB have zero/low switching costs, so AI-native CRM/HR/ERP companies can take share and march upmarket from below
Both of these are particularly tricky for incumbents to defend against. They simply aren’t able to move quickly enough to build compelling AI point solutions, and they’re struggling to defend downmarket while also defending the enterprise (bimodal go-to-market and running multiple service models in one company is incredibly difficult)
3. Incumbents scale by throwing people at the problem
This has been the dirty little secret of SaaS for 15 years. It’s basically impossible to grow revenue faster than headcount. Some companies like Shopify did it by layering on payments. Consumption-based companies have been doing it. The AI native companies have this figured out. The incumbent, seat-based, companies simply have never been able to decouple revenue from headcount. They will have to learn or die
4. Incumbents have the right to win but they are failing to capture the moment
As I’ve said before, the CIO wants to stick with their current vendors. They WANT to buy AI solutions from the incumbents. The problem is their solutions suck. @jasonlk has been all over this. These incumbents have a shrinking window of time where they have the advantage, but that window is shrinking. Rapidly.
I put a lot of heart into my technical writing, I hope it's useful to you all.
📌 Here's a pinned thread of everything I've written.
(much of this will be posted on the Claude blog soon as well)
Claude in PowerPoint is now available in research preview for Max, Team, and Enterprise.
Claude reads your layouts, fonts, and slide masters to stay on-brand — whether you're building from a template or generating a full deck from a description.
I've been reflecting on ten years of privates investing & my first 18 months at Coatue. 11 thoughts:
1/ Idea size > everything: Lots of funds talk about “big swings” but few operationalize it. I'm of the mind that idea sizing should be the atomic unit of consideration for every fund/stage.
2/ Think about the Trends: Transcendent companies ride massive secular shifts. Internet; Mobile; Cloud; LLMs. Great investments often sit at a convergence of multiple trends: the further out you zoom, the clearer trends become.
3/ the Path to Platform: the greatest source of privates alpha is identifying a platform company *before it's a platform. Every investment thesis is really just "the path to this being a Platform"... what’s wild is how compressed the timeline has become: platforms used to take a decade to emerge, but now signals show up in just a few years (why some Series B valuations are so high!)
4/ Avoid Losing: You don’t need to win deals -- you just need to not lose! In the interest of winning deals, not going to share more on how to avoid losing with peers on X (:
5/ Privates are far more zero-sum than publics: There's a tech narrative that we’re all in it together. Like Teletubbies, with Ramp cards. In reality, privates are much more zero-sum than Wall Street. But you can still choose to be nice! It helps you avoid losing (:
6/ Great founders share a trait, rate of learning: the best founders are, without exception, learning machines. They just keep getting better in a way that almost runs away from you (especially if you're a schmuck investor like me)
This is the one signal effectively impossible to fake -- and why investors actually want to meet CEOs well ahead of a fundraise; “we just want to get to know you” ;p
7/ You cannot make money on a spreadsheet: the alpha in spreadsheet investing was competed away years ago. People understand gross dollar retention now. To understand the Platform-anatomy of a company: help you, excel spreadsheets will not (Yoda)
8/ "Pattern Matching" is overused, but underrated: Investing is an exercise in reducing complexity: "the best models have fewer rows" .. Pattern matching is an overused term -- but the act of "seeing simplicity" is evergreen underrated.
9/ Diversification is a tax: concentrate winners! Diversification is not your friend: this is a known fact in venture (and increasingly true in publics)
10/ Decision Quality > everything: for all the hustle culture, busy calendars and "value add resources" at funds .. all the leverage is in decision quality. Great decisions compound. Avoiding losing compounds. It feels bad (but is correct) to say 95-99% of "passes" don't matter in power law investing. Know when you're around a BFI and get the decisions right!
11/ the Future is built by weird people, doing things that are obvious (in hindsight): if you’re not at least a little weirded out, it’s probably bad, actually!