@Dark_Emi_ Quand tu as eu 2 minutes par audition pour poser une question, que le rapporteur dit n'importe quoi et que tu n'as pas ton mot à dire dans le rapport final je comprends totalement les députés qui votent contre
@NCheron_bourse Merci pour ton post, plutôt d'accord avec ton avis.
Je n'ai pas compris la critique qui a montré qu'en investissant 50€/mois on arrive à récupérer 200+€/mois à la retraite. Je trouve aussi que c'était une vidéo anti investissement tout en montrant que ça marche pour tous
@NoviaNewsGroup Polymarket :
Grégoire 75% de victoire
Dati 25% de victoire
N'hésitez pas à parier si vous n'êtes pas d'accord, mais arrêtez les sondages bidons
@AnkamaAnim Un grand merci pour cette adaptation et un grand merci à @AnkamaGames pour le soutien financier à Andarta Pictures.
J'espère que le public sera au rendez-vous et que nous pourrons avoir d'autres tomes de Pierre Bottero adaptés.
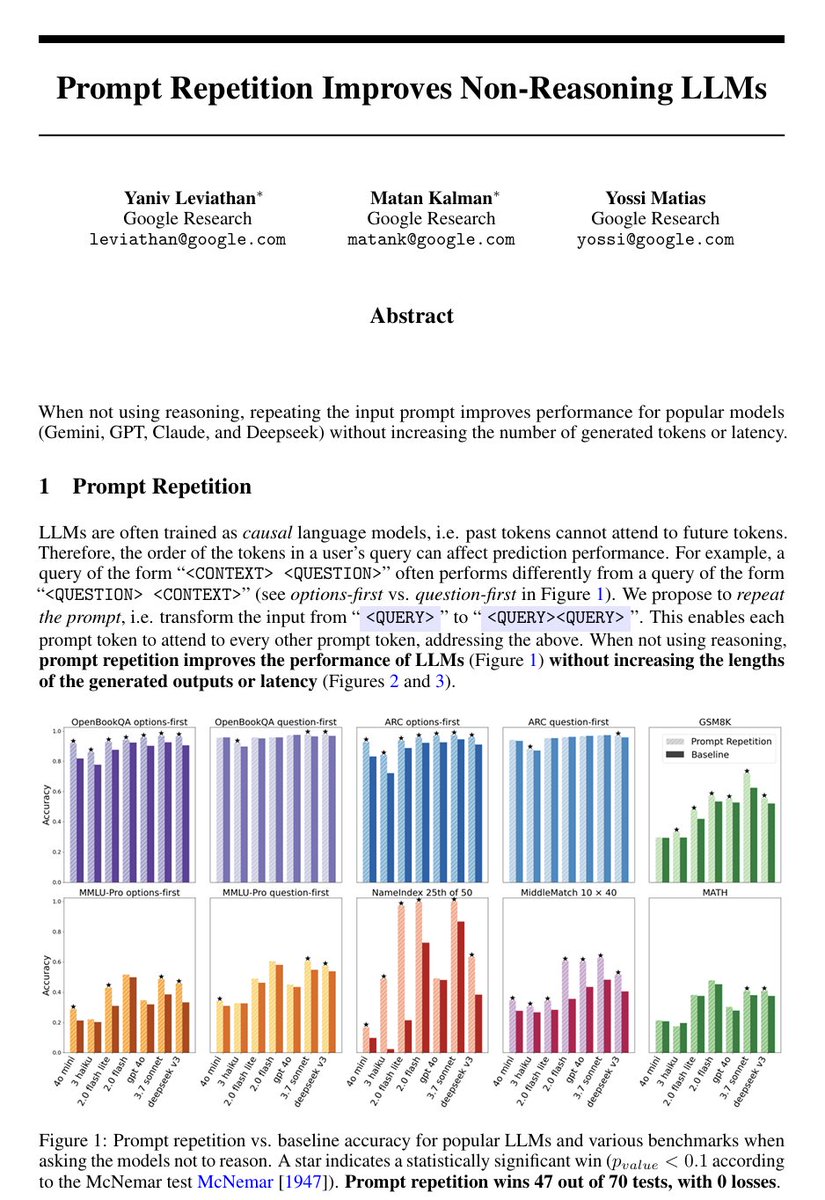
LLMs process text from left to right — each token can only look back at what came before it, never forward. This means that when you write a long prompt with context at the beginning and a question at the end, the model answers the question having "seen" the context, but the context tokens were generated without any awareness of what question was coming. This asymmetry is a basic structural property of how these models work.
The paper asks what happens if you just send the prompt twice in a row, so that every part of the input gets a second pass where it can attend to every other part. The answer is that accuracy goes up across seven different benchmarks and seven different models (from the Gemini, ChatGPT, Claude, and DeepSeek series of LLMs), with no increase in the length of the model's output and no meaningful increase in response time — because processing the input is done in parallel by the hardware anyway.
There are no new losses to compute, no finetuning, no clever prompt engineering beyond the repetition itself.
The gap between this technique and doing nothing is sometimes small, sometimes large (one model went from 21% to 97% on a task involving finding a name in a list). If you are thinking about how to get better results from these models without paying for longer outputs or slower responses, that's a fairly concrete and low-effort finding.
Read with AI tutor: https://t.co/MipHHO6rjX
Get the PDF: https://t.co/XQrqiaGwIO
@Capetlevrai Avec & tu peux switcher ton contexte de Claude code Web au Claude code terminal
Sinon juste installe l'extension Claude Code dans VS Code, je comprends toujours pas pourquoi vous utilisez Cursor ou Antigravity pour du vibe coding
@gonzague@OnParticipe Si votre carte est cobadgée (70% en France), vous devrez proposer le choix du réseau sous peine d'amende, même si votre lib permet bien de le réduire à 2 possibilités