Talks at TTIC presents Naomi Saphra (@nsaphra) of NYU (@CILVRatNYU) with a talk titled "Interpreting Training." Please join us on Monday, February 27 at 11:30 am CT in Room 530 or via Panopto: https://t.co/lPlBCrQTdY
AISTATS 2021 is coming soon! Don't miss the great talks, new research, and social events—register now for the virtual conference: https://t.co/RmXpruD1IY
Courant Institute and Radiology at NYU are hiring postdocs in the area of learning unified representations of patients using healthcare data from multiple modalities (imaging, EHRs, sensors). An exciting opportunity to make real-world impact. Details at: https://t.co/OJw85URzD8
One of the coolest ideas I spent time on this last year considers a weird way to specify confounders. In most traditional causal estimation, the confounders and interventions of interest are different columns in a dataset of pre-outcome variables.
I had a wonderful time chatting with @krrish94 and @duckietown_coo at the @MontrealRobots Robot Learning seminar yesterday!
Talk is on recorded here: https://t.co/R9Hm6Plxr1
Translation equivariance has imbued CNNs with powerful generalization abilities. Our #NeurIPS2020 paper shows how to *learn* symmetries -- rotations, translations, scalings, shears -- from training data alone!
https://t.co/ur8sseuGRk
w/ @g_benton_, @Pavel_Izmailov, @m_finzi. 1/9
🚨New Library Alert🚨: We are excited to release jiant 2.0, a natural language understanding toolkit focused on multi-task training and transfer learning research!
https://t.co/8jgnxHLsAF
New paper! We propose to measure the quality of learned representations using the complexity of finding a nearly-optimal predictor on a downstream task.
Blog: https://t.co/3HrGoWgQA7
Paper: https://t.co/r7PHNsVIub
Library: https://t.co/oO3pfGIUYn
A new blog post! <Influence Functions Do Not Seem to Predict Usefulness in NLP Transfer Learning> by Vid Kocijan and @sleepinyourhat. We value negative findings as much as shiny results and strive to share them which would've otherwise been hidden. https://t.co/EffiSxSR2L
Stochastic Weight Averaging (SWA) is a simple procedure that improves generalization in deep learning over Stochastic Gradient Descent (SGD). PyTorch 1.6 now includes SWA natively. Learn more from @Pavel_Izmailov, @andrewgwils and Vincent:
https://t.co/1u5yRwfWXT
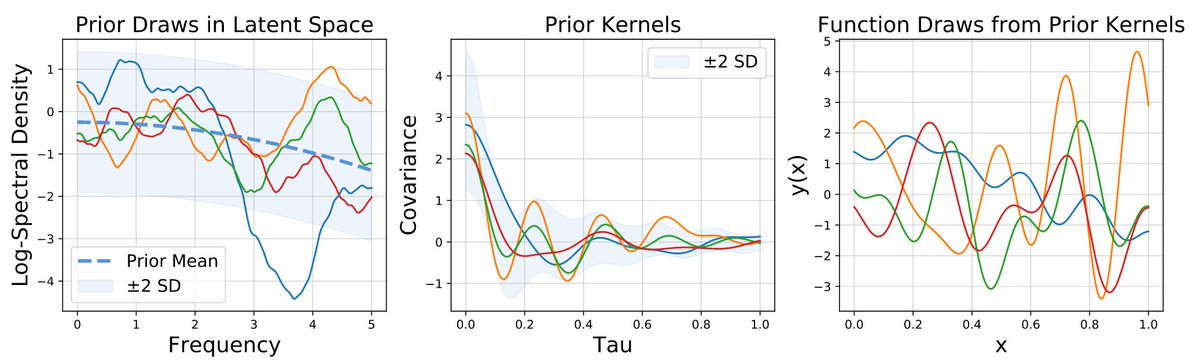
I'm so excited to be presenting on "Bayesian Deep Learning" and "How do we build models that learn and generalize?" at the @SMILESkoltech Summer School. 10 am ET tomorrow+Mon, livestreamed on YouTube! Functional kernel learning will make an appearance.
https://t.co/zlxRZobLFJ
New work in visual imitation learning!
We use commodity reacher-grabbers to both collect demonstrations in the wild, and as an end-effector for robotic manipulation. This means no domain shift b/n the demonstrations and the robot's observations!
https://t.co/ZoOvQknuws
1/5
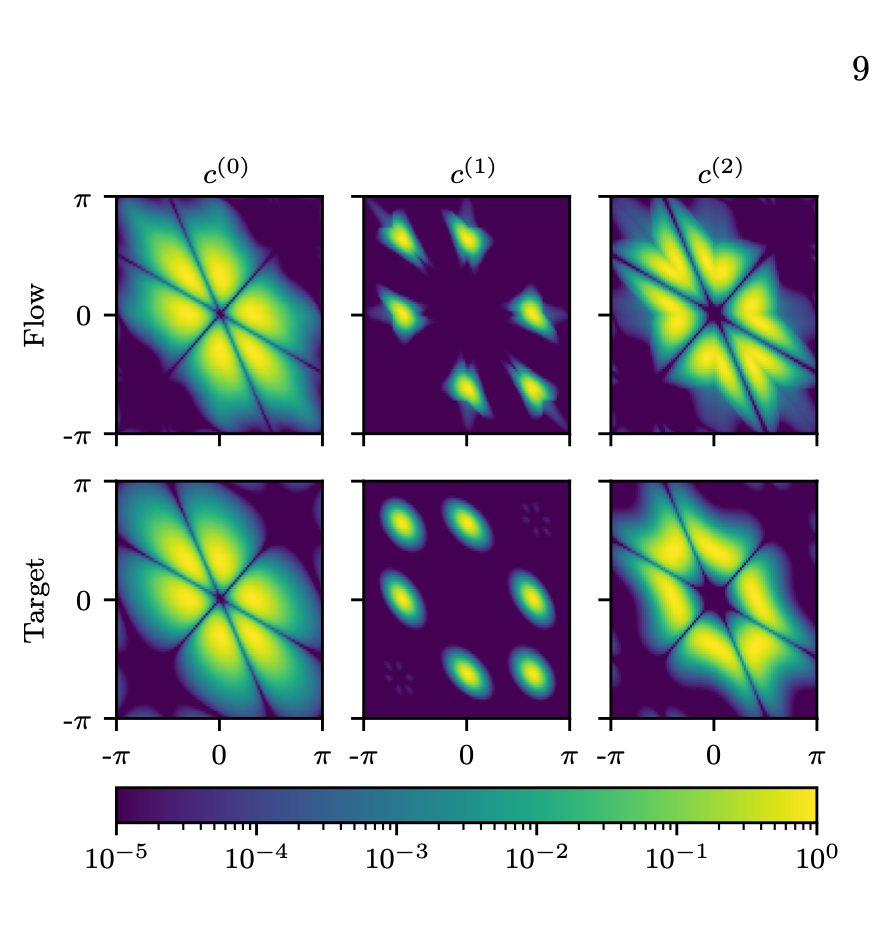
Very excited to share our newest paper
combining machine learning & physics. We develop normalizing flows that impose the elaborate of symmetry groups you find in fundamental particle physics.
It's a beautiful mix of math, ML, and physics
https://t.co/1keqEEEYM3
I had a wonderful experience presenting the ICML tutorial on Bayesian deep learning and probabilistic model construction. Thank you all for your encouraging comments. The video is now online!
https://t.co/2AUgasARBV
The #ICML2020 tutorial on Bayesian Deep Learning and Probabilistic Model Construction is tomorrow!
July 13, 11 am - 2 pm and 9 pm - 12 am EDT
https://t.co/O2oHub4X3G
See you there!
hello world! this is a twitter handle of the machine learning lab, CILVR, at @nyuniversity. see our homepage at https://t.co/FjCLJnxyK2 and in particular our newly created blog at https://t.co/8Dsj5bvW4g
@chhaviyadav_@nyuniversity because we don't have a CILVR-wide system to keep the website up-to-date with any dynamic info, we keep only the minimal info on the group webpage and refer people to individual faculty pages for more up-to-date, dynamic info. for instance, see https://t.co/JJfRSy8pOc