Before the week ends, let's acknowledge one of the most INSANE week ever for open AI, with 25+ notable open-weight drops across every modality:
🧠 LLMs
→ NVIDIA Nemotron 3 Ultra: 550B hybrid Mamba-MoE, only 55B active, 1M context, MMLU 89.1. NVFP4 variant claims ~5x throughput on Blackwell. First openly-weighted 550B hybrid Mamba-Transformer, closing the gap with frontier closed models.
→ Google Gemma 4 12B: fully open dense any-to-any (text/image/audio/video), 256k context, encoder-free, 140+ languages, AIME 2026 at 77.5. Shipped with a 23-checkpoint QAT wave (mobile ONNX + MLX). Most deployable model of the week.
→ StepFun Step-3.7-Flash: 198B sparse MoE VLM, ~11B active, SWE-Bench PRO 56.3. Apache 2.0.
→ Liquid AI LFM2.5-8B-A1B: edge MoE, just 1.5B active, 128k ctx, MATH500 88.8, MLX-ready. Best on-device option this week.
→ JetBrains Mellum2-12B-A2.5B-Thinking: their first open MoE, near-Qwen3-14B coding at 2.5B active. Apache 2.0.
🎨 Image gen (the surprise of the week)
→ Ideogram 4: their FIRST-EVER open weights. 9.3B flow-matching DiT trained from scratch. #2 overall behind GPT Image 2, top open-weight model on Design Arena + LMArena. Strongest open checkpoint for text-rich images, full stop. It has taste. Still can't believe this is open weights.
🔊 Audio & Speech (a breakout week for open TTS, 4 labs shipped)
→ Boson Higgs Audio v3 4B: 102 languages, 21 emotions, singing/whispering/shouting, sub-second TTFA.
→ RedNote dots.tts: the only fully continuous (no codec) open TTS pipeline, Apache 2.0.
→ Google Magenta RealTime 2: real-time music gen, <200ms latency, text+audio+MIDI. multimodalart ported it to PyTorch within hours with live ZeroGPU demos.
→ NVIDIA Nemotron-3.5 ASR: 600M streaming, 17x more concurrent streams vs Parakeet RNNT 1.1B.
👁️ Vision & VLMs
→ PaddleOCR-VL-1.6: SOTA document parsing at 1B params, Apache 2.0.
→ Baidu NAVA: 6.3B joint audio-video gen, best-in-class A/V sync, Apache 2.0.
🎬 Video, 3D & World Models
→ NVIDIA Cosmos3-Super: 64B omnimodal world model coupling action trajectories with video+audio gen, for Physical AI.
→ JD JoyAI-Echo: up to 5-min multi-shot text-to-video on LTX-2.3.
→ ByteDance Bernini-R + VAST TripoSplat (single-image-to-3D Gaussian splats, MIT).
Rebuilding my Hermes Agent setup on a new VPS. Finally skipped the Docker setup, I would probably go for a second VPS if I have to. Each profile has a gateway with Telegram for direct "management" discussions, then depending on the job Whatsapp/Signal. Pretty sweet.
Gemma 4 12B can now run locally on just 8GB RAM via Dynamic GGUFs.
Google's new model, Gemma 4 12B Unified supports image, audio and 256K context.
You can run and train the model via Unsloth Studio.
GGUF: https://t.co/8cL321pVDh
Guide: https://t.co/odRo9WjRpA
World Labs CEO Dr. Fei-Fei Li: "The world is not made of words."
"Language models have given machines an extraordinary command of concepts, vocabulary, and reasoning, but the physical world, virtual or real, runs on a different substrate."
"Where language models learn the statistical structure of text, world models learn the statistical structure of space and time: how light falls on a surface, how a garden looks from an angle no camera has captured, how objects respond to force and follow the laws of physics."
"Language gave machines a way to talk about that world. World models are how machines will finally come to understand, imagine, reason and interact with it."
Full piece: https://t.co/C9qOJg5wuc
RDV ce jeudi à 19h sur Twitch pour un live autour de l'IA (agentique), du SEO et du second cerveau avec notre invité : @micka_dore.
Hier, je le disais encore : la richesse de X, ce sont les rencontres et les connexions que l'on y fait. Mickaël, alias Optimike, fait partie de ces OVNI qui impressionnent. Nous avons donc décidé d'organiser un live pour vous montrer sur quoi il travaille en ce moment et partager sa vision.
Utilisateur d'Obsidian depuis plus de trois ans, il l'a progressivement transformé en véritable second cerveau. Depuis l'arrivée des LLM et l'essor de GPT, il l'utilise également comme socle pour ses agents IA. De mon côté, c'est devenu l'un des outils que j'utilise le plus aujourd'hui, aux côtés d'Hermes et de Codex, ce qui en dit long sur son potentiel.
Nous parlerons de compétences clés à développer, de Markdown (notamment les skills), d'organisation personnelle, de gestion de la connaissance, mais aussi de ce qu'il est possible de faire concrètement avec le SEO en 2026.
Nous évoquerons également le Lab X, une initiative lancée il y a quelques mois qui rassemble aujourd'hui plus de 100 membres actifs. Un espace où nous partageons nos idées, nos retours terrain et où nous essayons de construire et collaborer ensemble lorsque l'occasion se présente.
Rendez-vous jeudi à 19h.
We made a guide on using MCP with local LLMs.
Connect Qwen3.6 and Gemma 4 for controlled access to tools, files, APIs, enabling private automated workflows.
Learn to use OAuth, Exa, Context7, Hugging Face & more.
Guide: https://t.co/bkgK1ikP9i
GitHub: https://t.co/aZWYAtakBP
your AI agent should never see your real API key
a lot of people still dont know this but you can use iron proxy credential injection firewall
its already built in Hermes agent you just have to turn it on
hermes egress install
hermes egress setup
or just ask hermes agent to turn it on
New free model for your Hermes Agent - Stepfun's new Step 3.7 Flash!
This time we have quite a long term guarantee, so you can rest easy it wont dissappear with short notice!
Sign up for a free account to access at https://t.co/tMAQFkegul
Now in Hermes Agent, you can load an arbitrary amount of tools from mcps to plugins and get access to it all, with no compromise to your context!
Anytime you load more than 10% of your context window in tools from mcps or plugins, this feature will activate automatically!
hermes update to get access now 😎
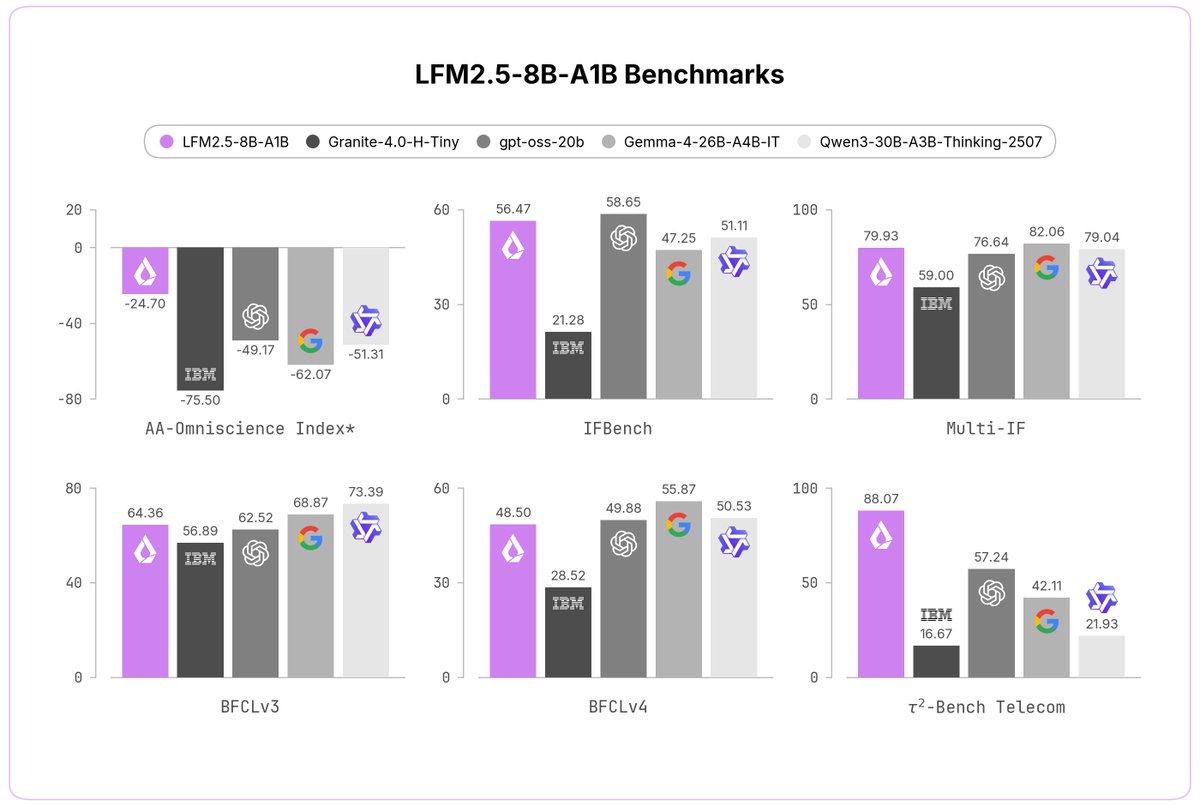
Today, we're releasing LFM2.5-8B-A1B, a device-optimized model designed to power real-life applications on phones, laptops, PCs, robots, and fast & lightweight server-side use-cases.
> 8B MoE, 1.5B active
> Expanded 128K context
> LFM2.5 flagship hybrid MoE architecture
> Trained on 38T tokens + large-scale RL
> fast, reliable tool calling, punching above its weight, comparable to models with up to 4x its size
> customizable on a single GPU for any specialized task
> LFM2 open-weight license
🧵
Free Models Updated on 28 May 2026
OpenCode
- Deepseek v4 Flash ( Recomended to try)
- MiMo v2.5 (Recomended to try, Multi modal)
- Nemotron 3 Super
Best 1-10$
- Opencode Go (Kimi, MiniMax,Qwen,MiMo)
- Command Code Go ( Deepseek, Qwen, MiMo)
- Deepseek PayPer API
- MiMo Lite ( MiMo Family)
Chinese models have a edge because they are optimized for low operational cost by design. Also they may scale in an easier way because they will rely less and less on @nvidia hardware that is designed for brute force approach, and will have issues with the level of power in racks
Behind the MiMo API Price Reduction:
The deepest price cut, up to 99%, is for Input (Cache Hit). The core reason is our inference framework now supports hierarchical KV cache optimization for SWA. Production inference engine tests show this optimization increases cached token capacity by 5x, equivalent to an 80% reduction in caching costs. Combined with Cache Read Overlap among multiple Full Attention modules in the Hybrid model, actual costs are further reduced.
Prices for Input (Cache Miss) and Output are also reduced by 60%-80%. This mainly benefits from the extreme 1:7 Full:SWA sparsity ratio brought by the model architecture (the prefill compute of the 70-layer MiMo-V2.5-Pro roughly equals a 10-layer GQA model). This kept our original inference costs well below the industry average, naturally leaving a 2x-3x profit margin in pricing. This price adjustment simply reflects our decision to pass these structural cost efficiencies directly to developers.
Operating at these newly reduced API prices, our production inference engine is running at near full capacity, and we can still essentially break even. We previously advised LLM companies not to "blindly cut prices" precisely because very few model architectures and inference optimizations can keep API costs from running at a loss. If more architectures that save compute and KV cache emerge, along with better inference Infra to drive down API costs, this will form an excellent virtuous cycle in the industry.
More crucially, affordable, high-performance model APIs will drive real, sustained, and at-scale inference demand. This upstream demand pulls forward the development of the entire AI infrastructure chain—including chips, servers, optical transceivers, PCBs, liquid cooling, power, energy storage, and data centers—serving as a strategic fulcrum for a systemic revaluation of AI hardware. In the long run, this injects more affordable and accessible compute into both training and inference pipelines, accelerating the parallel evolution of global AGI across multiple regions and technical routes.
For more technical details, we will release a detailed Blog post later.