My Fine-tuning Stack for Small Language Models (2B to 15B Models)
It costs me around $150 to generate a fresh dataset (~150M) and fine-tune the model.
> Codex 5.5= orchestrator / operator
> Deekseek v4 pro /Kimi 2.6= data gen. engine (dirt cheap)
> Qwen 3.5 = best model to fine-tune (4B, 9B, 27B)
> Unsloth = faster, cheaper fine-tuning framework.
> Colab = Cheapest cloud GPU (A100 80GB for $0.66/hr)
> G Drive = to save datasets (good codex + colab integration)
> Huggingface = To host datasets + Models
So Codex as planner & auditor,
Deepseek as cheapest executor,
Unsloth to fine-tune fast,
Colab to get cheapest A100 GPU,
Huggingface to host the fine-tuned model.
Anyone can fine-tune, and run a Sonnet 4.5 level Custom model on their system.
It’s very simple
Find a 3090 or two
Get any mobo that supports 2 pcie x16 ports (at least x16x4 for lanes)
Get a 1200W+ PSU
Buy the cheapest ddr4 ram 64gb+ (you’re not using it anyways)
Install Linux, vLLM, Llama.cpp, SGlang, tailscale
Download any flavour of qwen 3.7 27b
You are now localmaxxing
ANDREJ KARPATHY WROTE 65 LINES IN A CLAUDE.MD FILE AND IT JUST HIT NUMBER 1 ON GITHUB TRENDING.
Coding accuracy jumped from 65% to 94%.
Not a new model.
Not a better subscription.
65 lines of plain text.
Here is what that number actually means.
65% accuracy means one in three things Claude Code builds has a problem.
94% accuracy means almost everything it builds works the first time.
That gap is the difference between Claude Code feeling like a powerful tool and Claude Code feeling like a senior engineer who knows your codebase.
And Karpathy closed that gap with a text file.
Here is why this works.
Claude Code starts every session with zero context about your project, your standards, or how you want it to operate.
Without a CLAUDE.md it makes assumptions.
Reasonable assumptions compound into unreasonable outcomes across a complex build.
With Karpathy's 65 lines it has rules.
Think before you code.
Make surgical changes.
Simplicity first.
Never assume. Verify.
When uncertain ask.
These are not complex instructions.
They are the operating principles of every great engineer compressed into plain text that Claude reads before it touches your codebase.
65 lines.
Number 1 on GitHub.
29% accuracy improvement.
The entire Claude Code community has been trying to figure out why some setups feel transformative and others feel mediocre.
Karpathy just answered the question in 65 lines and published it for free.
Bookmark this before you open Claude Code today.
Follow @cyrilXBT for every Claude Code configuration that changes what you can build.
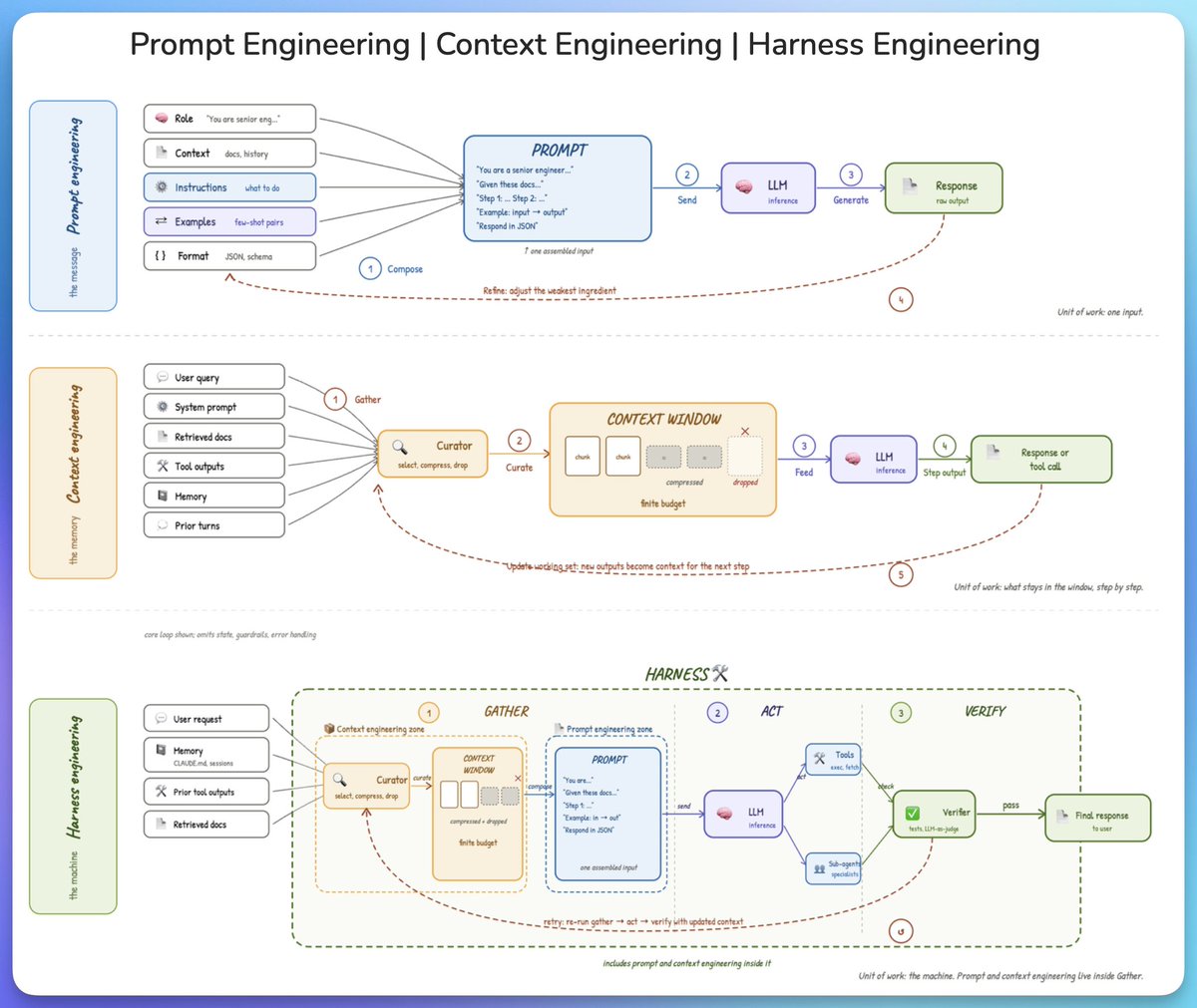
from prompt to context to harness engineering.
three terms keep coming up in AI engineering, and they get conflated all the time. here is the cleanest way to understand what each one is and how they fit together.
𝗽𝗿𝗼𝗺𝗽𝘁 𝗲𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 𝗶𝘀 𝘁𝗵𝗲 𝗺𝗲𝘀𝘀𝗮𝗴𝗲.
the model has no memory of anything before this single call, so the prompt has to carry the full universe of what it needs to know. that means a role, some background, the instructions, a few examples, and a format.
these get assembled into one input and sent to the model. when the output falls short, the skill is figuring out which ingredient is actually letting you down, not rewriting the instructions every time.
the unit of work is one input.
𝗰𝗼𝗻𝘁𝗲𝘅𝘁 𝗲𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 𝗶𝘀 𝘁𝗵𝗲 𝗺𝗲𝗺𝗼𝗿𝘆.
across multiple steps, the window is finite and the information available is not, which forces a curation step. without it, important details get buried under stale tool outputs and old turns, and the model's attention degrades on the things that actually matter.
a curator selects what stays, compresses what is useful but bulky, and drops the rest. each step's output then feeds into the next step, where good curation is more about knowing what to throw away than packing more in.
the unit of work is what stays in the window, step by step.
𝗵𝗮𝗿𝗻𝗲𝘀𝘀 𝗲𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 𝗶𝘀 𝘁𝗵𝗲 𝗺𝗮𝗰𝗵𝗶𝗻𝗲.
on its own, a model just generates text. the harness is what turns it into something that can take actions, check its own work, and recover when a step goes wrong.
the full loop has three phases:
- 𝗴𝗮𝘁𝗵𝗲𝗿 pulls together everything the model needs
- 𝗮𝗰𝘁 runs the model and calls tools or sub-agents
- and 𝘃𝗲𝗿𝗶𝗳𝘆 checks the output with tests or a judge
on failure, the whole loop retries with updated context, which is the entire difference between calling an API and running an agent.
the unit of work is the machine itself.
here is the part that ties it together.
prompt engineering and context engineering both live inside 𝗴𝗮𝘁𝗵𝗲𝗿. the harness is the outer container, context is what it curates, and the prompt is what it finally hands to the model.
zoom out and the unit of work gets bigger. zoom in and you are back at the prompt.
i also published this deep dive (article) on agent harness engineering, covering the orchestration loop, tools, memory, context management, and everything else that transforms a stateless LLM into a capable agent.
the article is quoted below.
Do something different this weekend.
Become a PRO in AI Model Fine-tuning.
Paste this prompt in Codex/ChatGPT/Claude/Grok.
"You are an expert AI engineer and teacher.
Your job is to teach me modern LLM engineering and fine-tuning concepts from beginner to advanced level using very simple daily-life language.
Teach me step-by-step like a real mentor. Assume I am smart but new to the topic.
Foundations:
- LLM basics
- How AI models work
- Tokens
- Tokenization
- Context windows
- Embeddings
- Transformers
- Attention mechanism
- Parameters
- Training vs inference
- Open-source vs closed-source models
Datasets & Training:
- SFT datasets
- Instruction tuning
- Preference datasets
- Synthetic datasets
- Data curation
- Dataset cleaning
- Dataset formatting
- Fine-tuning basics
- Continued pretraining
- Hallucination reduction
Fine-Tuning:
- LoRA
- QLoRA
- DPO
- RLHF
- Quantization
- Model checkpoints
- Adapter tuning
- GGUF models
Inference & Optimization:
- KV cache
- Flash Attention
- Speculative decoding
- Inference optimization
- Model serving
- Batch inference
- GPU basics
- VRAM basics
- Latency vs quality tradeoffs
Local AI Ecosystem:
- llama.cpp
- Ollama
- vLLM
- MLX
- Hugging Face
- Unsloth
- Axolotl
- PEFT
- TRL library
RAG & Memory:
- RAG
- Vector databases
- Chunking
- Retrieval pipelines
- AI memory systems
- Semantic search
Agents & Workflows:
- Prompt engineering
- System prompts
- Tool calling
- Function calling
- AI agents
- Agentic workflows
- Multi-agent systems
- Browser agents
Model Types:
- VLMs
- SLMs
- Dense models
- MoE models
- Coding models
- Reasoning models
Deployment:
- Local inference
- On-device AI
- API serving
- Cloud GPUs
- Edge AI basics
Evaluation:
- AI benchmarks
- Human evals
- Cost-per-token analysis
- Speed benchmarking
- Quality benchmarking
Real-World Skills:
- Building chatbots
- Building AI copilots
- AI automation
- AI SaaS workflows
- AI coding workflows
- AI orchestration systems
- AI product thinking
Start from the absolute basics and gradually make me advanced.
Rules:
- Use simple English only
- Avoid academic jargon unless necessary
- Explain every difficult word in plain language
- Use real-world analogies and daily-life examples
- Use small code snippets when useful
- Show practical use cases
- Compare concepts side-by-side when helpful
- Teach from fundamentals first, then advanced concepts
- At the end of each topic:
- give a short summary
- give a simple mental model
- give beginner mistakes to avoid
- give a small exercise/project
I want deep understanding, not memorization."
Thank me later.
Jane Street didn’t hire vibe-coder at $385k/year because he didn’t use Claude Code
37-minutes of vibe coding RIGHT during an interview at a Tier 1 fund
Bookmark & watch - you’ll finally understand why you need to use Claude Code. Then, read the article below.
Two Anthropic engineers spent 24 minutes exposing every Claude Code feature you didn't know existed.
Most people will scroll past this. Don't be most people.
@another_fi53412@JennyB311 No part of breaking any law is going to help you not pay for those illegal aliens joker. No wonder you're just another low iq-ed hate monger here. Imagine my shock
@another_fi53412@JennyB311 What part of entering a private property and refusing to obey security instructions is legal. Tit for tat? Is that how you guys play around there now?
@TheUltimateNoor@_sabasaurus If you look at one of the other cofounders, he gave an interview at Google for an intern role at age 18, and some google VP at that time decided right away he will fund whatever this guy builds. Many people are called in for interviews by google, Only some make such impact
@TheUltimateNoor@_sabasaurus PhDs are the only streams out of all study streams where you get the funding to literally try things out. The people you're surrounded with plays the most important role in these situations, but you need to do something to be in those environments that you can capitalize on.
@holycatsetra@RoundtableSpace There is nothing from them to patch here. Its totally unrelared to their service. Someone I think has bought the domain playimdb or sth that takes in arguments just like imdb does and plays movie from another (possibly illegal) website. IMDB would for sure report that