⚠️👇 🚨Breaking ⚠️
If we can’t make AI agents follow rules, we are screwed.
New study from METR reports that “when the agents were faced with hard tasks, they routinely violated constraints”
This—routine breaking of rules— is why in a nutshell we absolutely need a different approach to AI safety than the one we are currently taking, which simply is not up to the job (as I argued at Oxford last week).
Yann LeCun says you cannot build a reliable agentic system without a world model
LLMs don't have world models. They can't predict the consequences of their actions before taking them
"they just act, and whatever happens next is someone else's problem"
Without that, it's not intelligence
Researchers at EPFL proved your AI is lying to you.
Not sometimes. Most of the time.
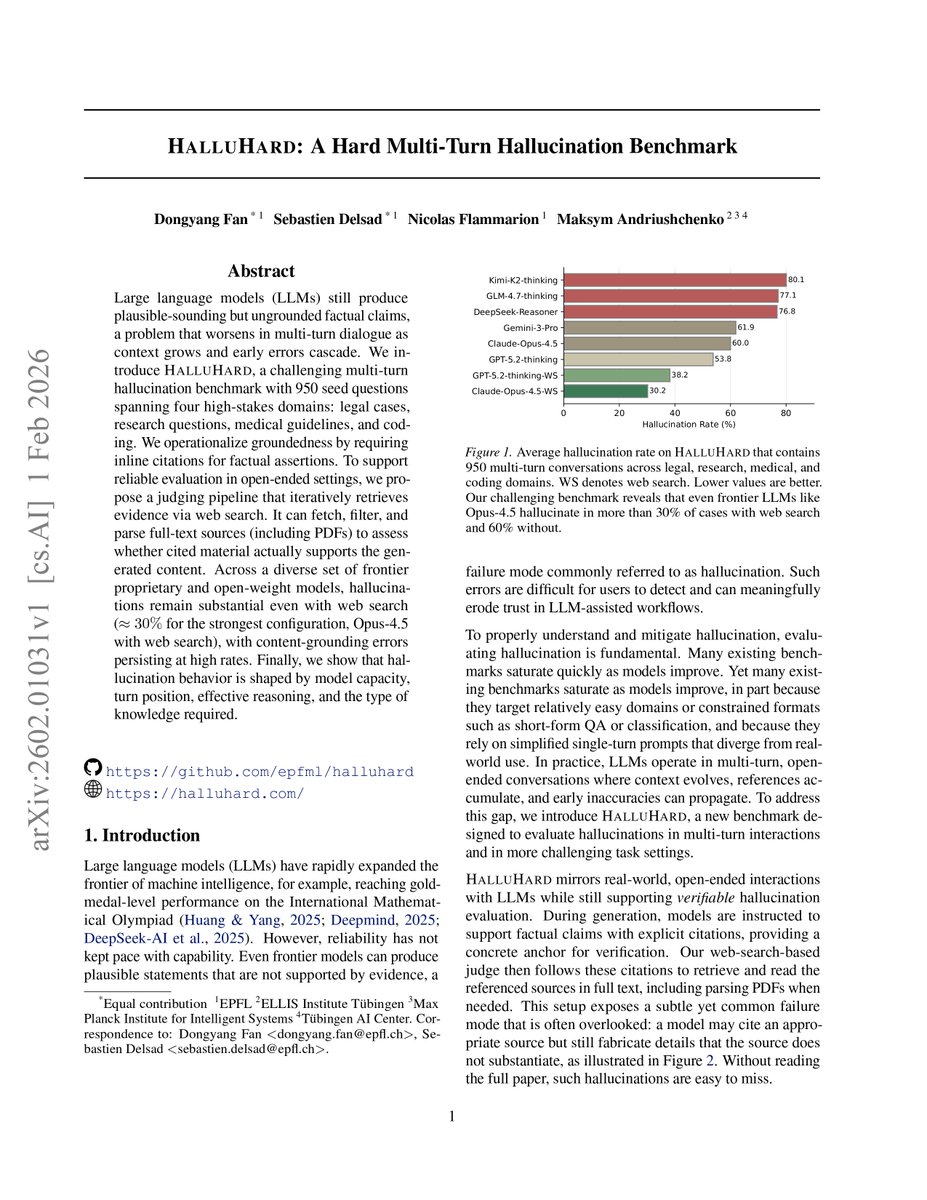
They built one of the hardest hallucination tests ever made with Max Planck Institute. 950 questions. Four domains where being wrong actually hurts. Legal. Medical. Research. Coding.
Then they ran every top model on it.
The results.
GPT-5. Wrong 71.8% of the time.
Claude Opus 4.5. Wrong 60% of the time.
Gemini 3 Pro. Wrong 61.9% of the time.
DeepSeek Reasoner. Wrong 76.8% of the time.
These are the smartest AI models on Earth. The ones you trust with your career. Your health. Your money.
You think turning on web search fixes it.
It doesn't.
Claude Opus 4.5 with web search. Still wrong 30.2% of the time.
GPT-5.2 thinking with web search. Still wrong 38.2% of the time.
The internet attached. Still lying to you in 1 out of every 3 answers.
Now the part that should scare you.
Medical questions. The one place being wrong can kill you.
GPT-5 hallucinated 92.8% of the time on medical guidelines.
Claude Haiku 4.5 hallucinated 95.7% of the time.
Gemini 3 Flash hallucinated 89% of the time.
Nine out of ten medical answers from popular AI models. Wrong.
It gets worse.
The longer you talk to it, the more it lies.
Early mistakes cascade. The model starts citing its own earlier hallucinations as facts. Your third message is more wrong than your first.
The paper, in its own words: "hallucinations remain substantial even with web search."
This is what hundreds of millions of people are doing right now. Asking software that lies in the majority of its answers. About their health. About their job. About their legal case. About their code.
Most are not checking.
Most never will.
But please. Keep using ChatGPT for medical advice.
The doctors need a break.
https://t.co/dHBP5CDpTM
@jackclarkSF AI systems have been capable of building themselves since LISP was invented in the 50s. The question is whether you get increasing or diminishing returns, and so far there’s no evidence of the former.
“In summary, there is very little evidence for LLMs benefiting patients or doctors for health outcomes” - Dr. @EricTopol
Read his full review here:
https://t.co/vHKo35n2BT
Research proves that current AI agent groups cannot reliably coordinate or agree on simple decisions.
Building teams of AI agents that can consistently agree on a final decision is surprisingly difficult for LLMs.
But problem is that developers frequently assume that if you have enough AI agents working together, they will eventually figure out how to solve a problem by talking it through.
This paper shows that this assumption is currently wrong. Even in a friendly environment where every agent is trying to help, the team often gets stuck or stops responding entirely. Because this happens more often as the group gets bigger, it means we cannot yet trust these agent systems to handle tasks where they must agree on a correct answer.
----
Paper Link – arxiv. org/abs/2603.01213
Paper Title: "Can AI Agents Agree?"
New Microsoft paper shows that current AI assistants often damage documents during long editing jobs.
Even the frontier models still ended up corrupting about 25% of document content on average, while many other models damaged far more.
The problem is that delegated AI work only makes sense if a model can keep a document correct across many edits, not just do 1 step well.
The paper tests this with reversible task pairs, where a model edits a file and then tries to undo that edit, so a reliable system should return to the original document.
The authors built real work setups across 52 domains, from coding and science to accounting and music notation, and ran 19 models through 20 editing interactions.
The failures were usually not lots of tiny slips but occasional big mistakes that silently broke parts of the document and then compounded over time.
Agentic tool use did not help in their tests, and bigger files, longer workflows, and irrelevant extra documents made the corruption worse.
The reason this matters is that current LLMs can look strong in short demos or narrow coding tasks yet still be unreliable delegates for long real-world document work.
----
Paper Link – arxiv. org/abs/2604.15597
Paper Title: "LLMs Corrupt Your Documents When You Delegate"
If you don't understand this, you will not understand why LLM-based agents are irreparably failing for a general-purpose problem solving.
An agent (by the way it was the topic of my PhD 20 years ago) to be useful, must be rational. Being rational means to always prefer an outcome that results in the maximal expected utility to its master/user.
Let’s say an agent has two actions they can execute in an environment: a_1 and a_2.
If the agent can predict that a_1 gives its user an expected utility of 10, and a_2 gives an expected utility of -100, then a rational agent must choose a_1 even if choosing a_2 seems like a better option when explained in words. The numbers 10 and -100 can be obtained by summing the products of all possible outcomes for each action and their likelihoods.
Now here is the problem with LLM-based agents.
The LLM is not optimizing expected utility in the environment. It is optimizing the next token, conditioned on a prompt, a context window, and a training distribution full of examples of what helpful answers are supposed to look like.
Those are not the same objective.
So when we wrap an LLM in a loop and call it an “agent,” we have not created a rational decision-maker. We have created a text generator that can imitate the surface form of deliberation.
It may say things like:
“I should compare the expected outcomes.”
“The best action is probably a_1.”
“I will now execute the optimal plan.”
But the internal mechanism is not selecting actions by maximizing the user’s expected utility. It is generating a continuation that is statistically appropriate given the prompt and prior context.
This distinction matters enormously.
For narrow tasks, the imitation can be good enough. If the environment is constrained, the actions are simple, and the success criteria are close to patterns seen in training, the system can appear agentic.
But for general-purpose problem solving, the gap becomes fatal.
A rational agent needs stable preferences, calibrated beliefs, causal models of the world, the ability to evaluate consequences, and the discipline to choose the action with maximal expected utility even when that action is boring, non-linguistic, or unlike the examples in its training data.
An LLM-based agent has none of that by default.
It has fluency. It has pattern completion. It has a remarkable ability to compress and recombine human text. But fluency is not rationality, and a plausible plan is not an expected-utility calculation.
This is why these systems so often fail in strange, brittle, and irreparable ways when given open-ended responsibility.
They are not failing because the prompts are insufficiently clever.
They are failing because we are asking a simulator of rational agency to be a rational agent.
@GaryMarcus Never ever use generative AI for anything critical.
The technology is probablistic all the way down and therefore inherently unreliable.
Why is this so hard to understand?
It’s wild how many seemingly smart people have drunk the cool aid on this.
Yann LeCun (@ylecun ): Sillion Valley is "completely LLM-pilled"
"In the end, if you’re interested in building systems that have the intelligence of, let’s say, a cat, let alone humans, you need common sense. You need the ability to predict the consequences of your actions.
You need the ability to plan. You need the ability to reason.
And you’re not going to get this with VLA, VLM, or LLM or any generative architectures."
---
From 'AI House Davos" YT channel (full link in comment)
My basic model of capabilities: LLMs are good at problems similar to those that appear in their training data.
Training data largely reflects the world, and so LLMs are relatively good at problems that are common, relatively bad at problems that are rare.






















![PIN's tweet photo. Tuning Agent-Based Predator-Prey Models Toward Lotka-Volterra Dynamics
Corinna Mandl, Siddharth Chaturvedi, Marcel van Gerven
https://t.co/GvGSUvG53V [𝚌𝚜.𝙼𝙰] https://t.co/aOda9KLzVL](https://pbs.twimg.com/media/HKpbN-pW0AAdBBU.png)