Imagine every pixel on your screen, streamed live directly from a model. No HTML, no layout engine, no code. Just exactly what you want to see.
@eddiejiao_obj, @drewocarr and I built a prototype to see how this could actually work, and set out to make it real. We're calling it Flipbook. (1/5)
Meet Fabula: an interactive AI writing tool helping authors structure & refine stories. Co-designed with 42 expert writers, the demo showcases how convergent iteration supports creativity. Catch the demo at the Google booth at 10:30AM! #CHI2026
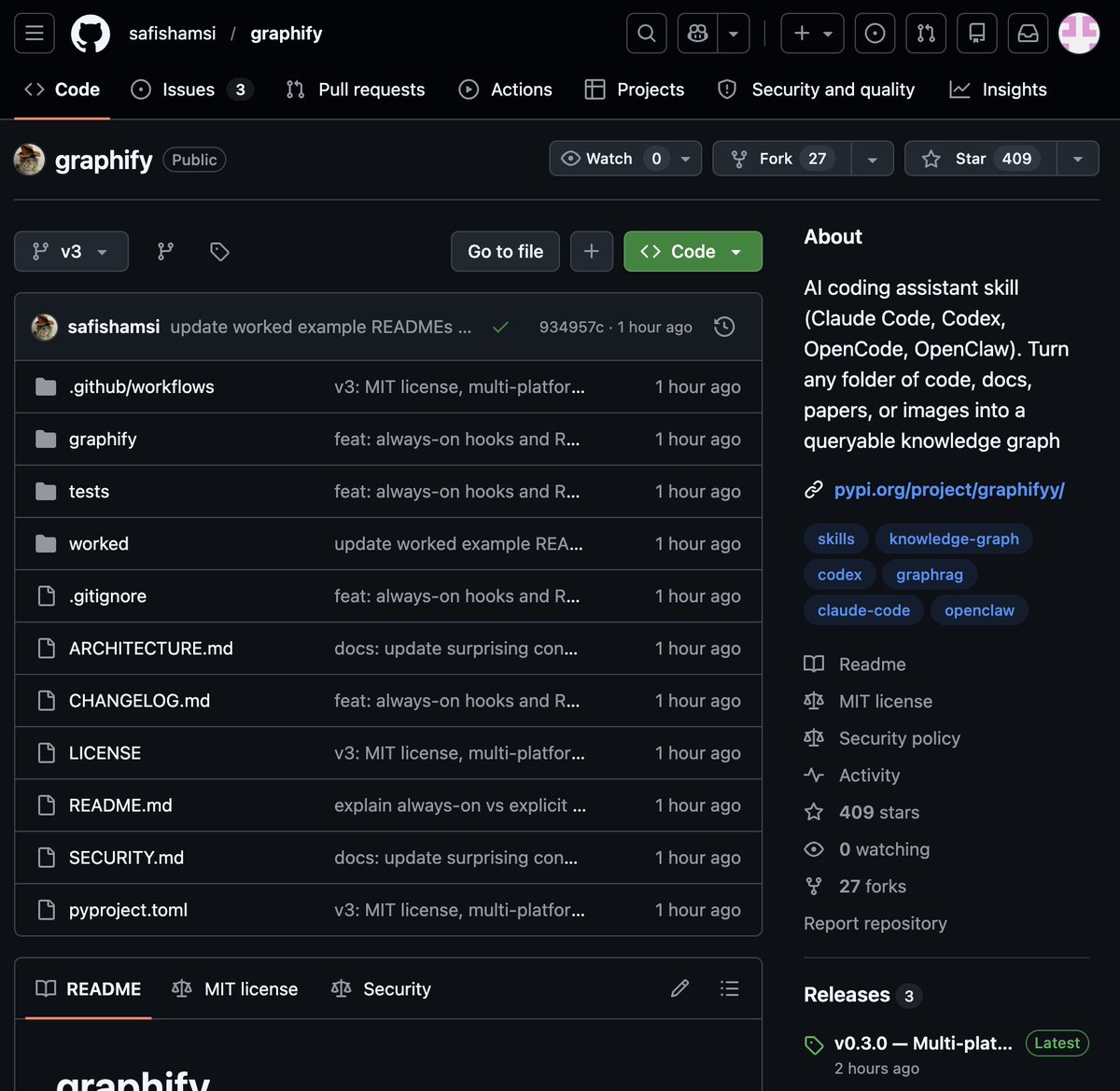
🚨 BREAKING: Someone just built the exact tool Andrej Karpathy said someone should build.
48 hours after Karpathy posted his LLM Knowledge Bases workflow, this showed up on GitHub.
It's called Graphify. One command. Any folder. Full knowledge graph.
Point it at any folder. Run /graphify inside Claude Code. Walk away.
Here is what comes out the other side:
-> A navigable knowledge graph of everything in that folder
-> An Obsidian vault with backlinked articles
-> A wiki that starts at index. md and maps every concept cluster
-> Plain English Q&A over your entire codebase or research folder
You can ask it things like:
"What calls this function?"
"What connects these two concepts?"
"What are the most important nodes in this project?"
No vector database. No setup. No config files.
The token efficiency number is what got me:
71.5x fewer tokens per query compared to reading raw files.
That is not a small improvement. That is a completely different paradigm for how AI agents reason over large codebases.
What it supports:
-> Code in 13 programming languages
-> PDFs
-> Images via Claude Vision
-> Markdown files
Install in one line:
pip install graphify && graphify install
Then type /graphify in Claude Code and point it at anything.
Karpathy asked. Someone delivered in 48 hours.
That is the pace of 2026.
Open Source. Free.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
Vers un apprentissage robotique au millimètre près
L’un des défis majeurs de la robotique moderne réside dans le « dernier millimètre » : cette précision chirurgicale nécessaire pour insérer un câble Ethernet ou visser une minuscule vis, que les modèles généralistes peinent à maîtriser. La startup californienne Physical Intelligence vient de lever cet obstacle en dévoilant sa méthode baptisée « RL Tokens » (RLT).
Reposant sur l’apprentissage par renforcement, cette innovation permet d’affiner les compétences d’un robot pour une tâche extrêmement précise en seulement quelques heures, voire une quinzaine de minutes de pratique « en conditions réelles ». Plutôt que de réentraîner l’intégralité de son modèle fondamental (fort de plusieurs milliards de paramètres), l’entreprise a eu l’idée d’y greffer un jeton de sortie spécifique (« RL token ») qui alimente un petit réseau neuronal exclusivement concentré sur la phase critique du mouvement.
Les résultats sont spectaculaires : sur des tâches d’insertion complexes, la méthode RLT multiplie la vitesse d’exécution « par trois » et augmente drastiquement le taux de réussite. Mieux encore, lors de l’assemblage, le système s’est révélé plus rapide que la médiane des opérateurs humains, marquant un tournant dans la robotique industrielle !
Cette application IA vaut 2 milliards de dollars.
Halter, une startup néo-zélandaise, fabrique des colliers IA pour vaches. Alimentés par énergie solaire.
L'agriculteur ouvre une appli. Trace une ligne sur une carte. Cette ligne devient une clôture invisible.
Quand la vache s'approche de la limite, le collier vibre. En 10 jours, l'animal ne teste même plus la frontière. Il reste à l'intérieur.
Un bouton sur l'appli et les vaches se rassemblent pour la traite. Toutes seules.
Le fondateur ? Un ancien ingénieur spatial de Rocket Lab. Il a quitté l'aérospatiale parce qu'il trouvait que l'agriculture était un plus gros problème à résoudre.
Les chiffres :
→ 600 000 colliers déjà déployés sur plus de 5 000 fermes
→ 18 000 km de clôtures virtuelles construites aux US, l'équivalent du périmètre des États-Unis
→ 220 millions de dollars d'économies en clôtures physiques
→ Un employé en moins nécessaire pour 400 vaches
→ Abonnement : 5 à 8$/mois par animal
Leur algorithme propriétaire s'appelle le "Cowgorithm". Oui, vraiment.
Peter Thiel mène cette levée via Founders Fund. Le tour est tellement sur-souscrit qu'ils n'ont même pas encore fixé le montant final. Valorisation doublée en moins d'un an.
L'IA ne change pas que la tech. Elle change l'agriculture. Et les vaches n'ont rien demandé à personne (lol).
Il y a une fatigue bizarre dont on ne parle presque pas, liée au fait de coder avec l’IA.
Ce n’est pas la fatigue de taper du code. Ce n’est pas non plus la fatigue classique du debugging, des erreurs de syntaxe, ou des heures passées à chercher pourquoi « ça ne compile pas ».
C’est une fatigue beaucoup plus subtile. Une fatigue cognitive.
Avant, programmer était un mélange de pensée et d’exécution. Nos mains participaient au raisonnement. On écrivait, on hésitait, on corrigeait, on avançait lentement. La vitesse d’écriture servait presque de régulateur naturel à la complexité de notre pensée.
Aujourd’hui, l’IA peut produire 1 000 lignes en quelques secondes.
Le bottleneck, ce n’est plus l’écriture. C’est la clarté.
Parce que l’IA ne fait qu’exécuter votre intention. Et la moindre ambiguïté dans votre esprit devient une ambiguïté dans le système. La moindre imprécision devient un bug. La moindre zone floue devient de la dette technique.
Du coup, votre rôle change profondément.
Vous passez moins de temps à écrire du code, et beaucoup plus de temps à maintenir un modèle mental complet du système. À spécifier précisément ce que vous voulez. À anticiper les cas limites. À relire. À valider. À douter.
L’effort n’a pas disparu. Il s’est déplacé.
Avant, on pouvait se cacher derrière la lenteur de l’exécution. Aujourd’hui, la vitesse de l’IA expose brutalement la qualité de notre pensée.
Vous pouvez générer de mauvais systèmes extrêmement vite. Et c’est vous qui en portez la responsabilité. C’est ça qui fatigue.
Pas parce que vous travaillez plus. Mais parce que vous êtes en permanence dans un état de vigilance intellectuelle. Il n’y a plus de refuge dans le mécanique. Plus de repos dans l’exécution.
Vous êtes confronté directement à la précision, ou à l’imprécision, de votre propre esprit.
Ironiquement, vous écrivez moins de code que jamais. Mais vous pensez plus que jamais.
Et cette transition, de l’effort mécanique vers l’effort purement cognitif, a un coût. Une fatigue silencieuse. Nouvelle. Et profondément étrange.
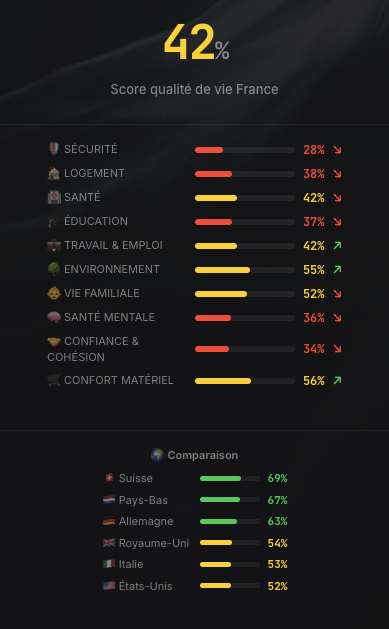
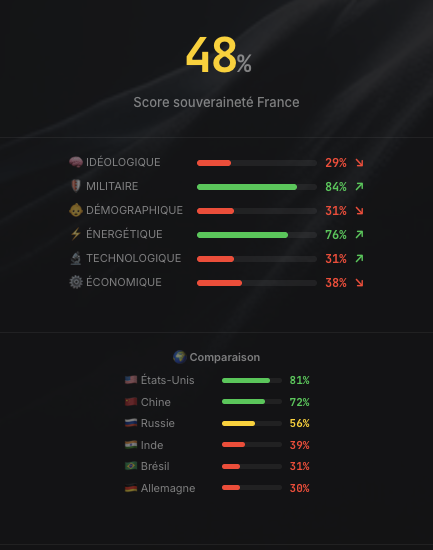
J’ai le plaisir de vous partager la version alpha du projet « Tableau de bord de la France ».
Son objectif est de donner une version claire, chiffrée, sourcée et sans concession d’où se trouve la France aujourd’hui, et comment elle se compare aux autres pays. Cela nous permet de savoir où nous allons, où nous concentrer et par la donnée attirer l’attention sur les vrais sujets.
Cette version alpha a été réalisée avec sérieux, mais peut contenir des erreurs ou des approches méthodologiques qui pourront être ajustées. Je vous serais donc très reconnaissants pour tous vos bienveillants retours.
Par ailleurs, cette version est encore très incomplète, et elle s’enrichira au fur et à mesure.
Merci encore pour votre soutien et vos précieuses contributions et surtout partagez le tableau de bord très largement, que le maximum de personnes aient conscience d'où nous en sommes. https://t.co/YNv7c369FP
Avant le braquage du Louvre, il y a eu un autre grand braquage : celui de Nicolas Sarkozy.
Il a vendu 600 tonnes d'or de la France au prix de 400$ l'once, aujourd'hui il vaut 4300$ l'once.
Automated farming in greenhouses in Shandong China.
From the high-speed rail, I passed two hours of greenhouses recently. Shandong is levelling up its agricultural output.
Deux marques d'eaux de Nestlé, Contrex et Hépar, sont bourrées de micro-plastiques. En cause, plus de 400 000 m3 de déchets que le groupe a laissé pourrir lentement autour de ses usines d'embouteillage dans les Vosges. Quel scandale https://t.co/uZko0IAuCf
LEAKED: 100s of premium AI Agents EXPOSED...
These Agents sell for $5,000+ per build, easily...
Inside the file you’ll get:
→ Lead qualification agents
→ Content generation pipelines
→ Appointment booking automation
→ Cold outreach sequences
→ Data extraction & web scrapers
→ Customer support agents
→ +100s more plug & play systems
BONUS: An n8n Masterclass, so you know how to run, customize, and scale every workflow.
These are the same systems 6-figure agencies use to deliver high-ticket builds.
Follow + RT + Comment “VAULT” and I’ll send you the drive for FREE!
PS: If you’re still building agents manually… Consider this your early retirement package.