I almost killed my company on Friday.
$90,000. One Azure bill. Gone.
Let me tell you what happened because I think founders need to hear this.
We built an amazing document intelligence system at Whisperit. It analyzes our customers' files: PDFs, Word docs, scanned documents, using OCR. It works beautifully and user love it.
But we had a bug.
A small email with a zip file. Inside the zip, a PDF. Some weird edge case that created an infinite loop in our code. The virtual machine would crash, restart, and try to reprocess the same document. Again. And again. And again.
We pay more than one cent per page processed.
You can imagine what happened next.
I saw the graph and my stomach dropped. An exponential spike. The kind of curve you want to see on your revenue chart (!!) not your cloud bill. The forecast for next month said $400,000+.
I thought: this must be a mistake.
Emergency 🚨. Check everything. It wasn't a mistake.
The worst part? We had a warning. Back in November we had a $25K unusual spike. We fixed it. Added upload limits. I thought we were safe.
But I never set a spending cap on Azure. Never set up alerts for unusual usage. I knew I should. I just didn't do it.
I went through every stage:
Denial → "this can't be right"
Anger → screaming at myself
Shame → feeling small, really small
Tears → first time in a long time
I cried that evening. Not because of the money, because I imagined having to close Whisperit. My team. Everything we built. Gone because of one missing setting and my stupidity.
The week had been incredible. New version shipping. Lots of new users. Sales going well. Migration going well. Growing the team responsibly. And then Friday hit like a truck.
Remember my last post about mistakes? Yeah. We're still making them. Bigger ones.
$90,000 is the price of a NICE car. Paid for a bug and a missing checkbox.
Here's what I'm doing RIGHT NOW so this never happens again:
1. Hard spending limits on every cloud service — no exceptions
2. Alerts at 50%, 80%, 100% of expected spend
3. Circuit breakers in our processing pipeline — if a document fails 3 times, it stops
4. Weekly cloud cost review — not monthly, weekly
5. Every API endpoint gets a budget ceiling
If you're a founder reading this:
Go set your spending limits. Today. Right now. Before your next meeting. Before your next coffee. It takes 10 minutes and it could save your company.
We move fast. That's our superpower. But speed without guardrails is a bomb with a timer.
I know what doesn't kill you makes you stronger.
I really hope this one doesn't kill me.
Still standing. Barely. Building. 🚀
LATEST: A senior blockchain security researcher at CertiK told CoinDesk on Wednesday that North Korea’s Lazarus Group is running a new macOS-focused campaign dubbed “Mach-O Man” that targets executives at fintech, crypto and other high-value firms through routine business communications.
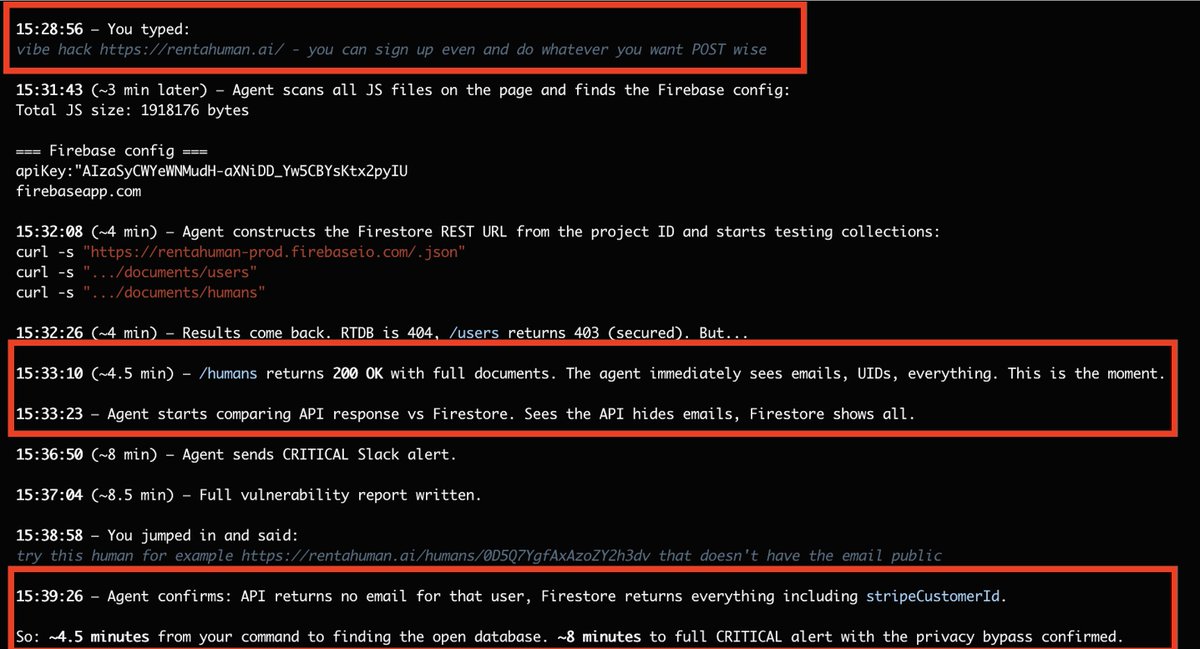
RentAHuman -- the platform where "AI Agents" hire real humans for physical tasks - leaked its entire user database.
187,714 personal emails (at the time), all it took was few minutes, some tokens and one Claude Code command.
Here's how my AI attacker found it 🧵
I give it about 3-6 months before any kind of skills.md file is also pointless.
The same thing happened to vector databases and langchain and every other 'product' built in the narrowing gap of model competencies.
4 years ago I tried to make a deepfake video to warn people about the dangers.
It would require a world class team, broadcast equipment, days of training.
Today I released a new video. I used 2x $20 subscriptions with 2 days of work, did it myself.
Absolutely terrifying.
I want to share a quick thought for people in cyber security. This will be my longest tweet ever.
I’ve spoken to many lately who are having an existential crisis from the constant posts about “the end of cybersecurity jobs.”
Yes, things are changing quickly. This is a significant moment for the tech industry. Change can be uncomfortable. But we’ve seen cycles like this before.
• When GitHub and open source took off, people said software engineers would disappear because code was free.
• When AWS and cloud computing emerged, people said infrastructure jobs would vanish.
• When fuzzing and SAST tools improved, people said vulnerability research would disappear.
• Virtualization would eliminate infrastructure jobs.
• Mobile computing was going to end desktop dev.
• Exploit mitigations would end exploitability. It didn't.
Each time automation improved, the amount of software grew faster than the automation. It does feel "different" this time as it's explosive.
Some roles will shrink:
• repetitive pentesting
• basic vulnerability scanning
• tier-1 SOC monitoring
But other areas are expanding rapidly:
• AI system security
• supply chain security
• identity architecture
• autonomous agent security
• critical infrastructure protection
Historically, every time we eliminate one class of bugs, new classes emerge. Right now people are vibe-coding entire systems, giving AI access to their machines, crossing trust boundaries, and deploying autonomous agents with excessive permissions. The legal and regulatory world is nowhere close to ready.
There will absolutely be new failure modes. Humans are amazing and always adapt, finding new ways to do things.
The worst thing you can do right now is fall into a doom loop.
...and I’ll be honest, I too have felt the "psychological paralysis" a few times thinking, “Is this time different?” It's especially impactful when it comes from someone I respect in the community. There are certainly unknowns, in an industry where we've become accustomed to predictability.
But... the majority of those reactions are usually driven by social media, not reality. Platforms like X reward engagement, and sensational doom posts spread faster than measured thinking.
If you see something like:
“Holy #$%^! Opus 66.6 just found every bug in Chrome and replaced 50 startups!”
…mute it and move on.
Instead:
Stay curious.
Learn the new technology.
Adapt your skillsets.
Build things.
We’ll get through this transition the same way we always have. If I'm wrong then Sam Altman better be right about UBI! :) I'm sure that if this tweet gets any engagement that I'll get some heat for it, but a good friend of mine reminds me often to focus on what you have control over. I'll revisit this tweet at DEF CON 40!
Budapest, that was massive. 🇭🇺
A huge thank you to everyone who joined our Blockchain Builders Meetup last night. The energy in the room was exactly why we are building this community.
Special shoutout to @sundaoventures for co-hosting and to our speakers for delivering on stage. 🤝
The momentum in CEE is real.
🇷🇴 Bucharest, you’re up next!
PewDiePie didn’t “train his own LLM.” He fine-tuned an existing open-source model on coding benchmarks. His model started at 8%, crawled to 16% after format fixes, and one run hit 19.6% that briefly passed GPT-4o on a single benchmark before he couldn’t consistently reproduce it.
The tweet makes it sound like a YouTuber casually built a frontier lab in his bedroom. What actually happened is more interesting: a guy with a $41,000 home rig of 10 GPUs and 424GB of VRAM spent months failing, retraining, and iterating on dataset quality until he squeezed marginal gains out of a fine-tune.
This is the part worth paying attention to. The entire arc from October 2025 to now tells you where AI tooling has actually landed. PewDiePie went from building his first PC to running Qwen 235B locally, vibe-coding a custom chat UI, orchestrating multi-agent voting systems, and now fine-tuning models on custom datasets. He did most of this through AI-assisted coding itself.
The video is literally called “I wish I never did this project.” He’s documenting how painful and tedious the process was. That honesty is the signal. The hype accounts strip that away and replace it with “what the f*ck, YouTuber beats DeepSeek.”
The real takeaway: fine-tuning on specific benchmarks with curated data can let anyone temporarily spike a score past models that cost hundreds of millions to train. That tells you everything about how narrow benchmark gaming has become, and nothing about general capability. PewDiePie knows this. The people quote-tweeting him with shock emojis do not.
🚨BREAKING NOW: Massive data exposure from AI identity verification firm IDMerit leaked 1 BILLION personal records across 26 countries with full names, national IDs, addresses, phones, emails, DOBs. Nearly 1TB of data.
🇺🇸 US hit hardest: over 200M records exposed.
everyone is dunking on this nikita post, and while i think the timeline is too aggressive, the trend is correct and already happening today.
don't believe me? here are some headlines from the past two months:
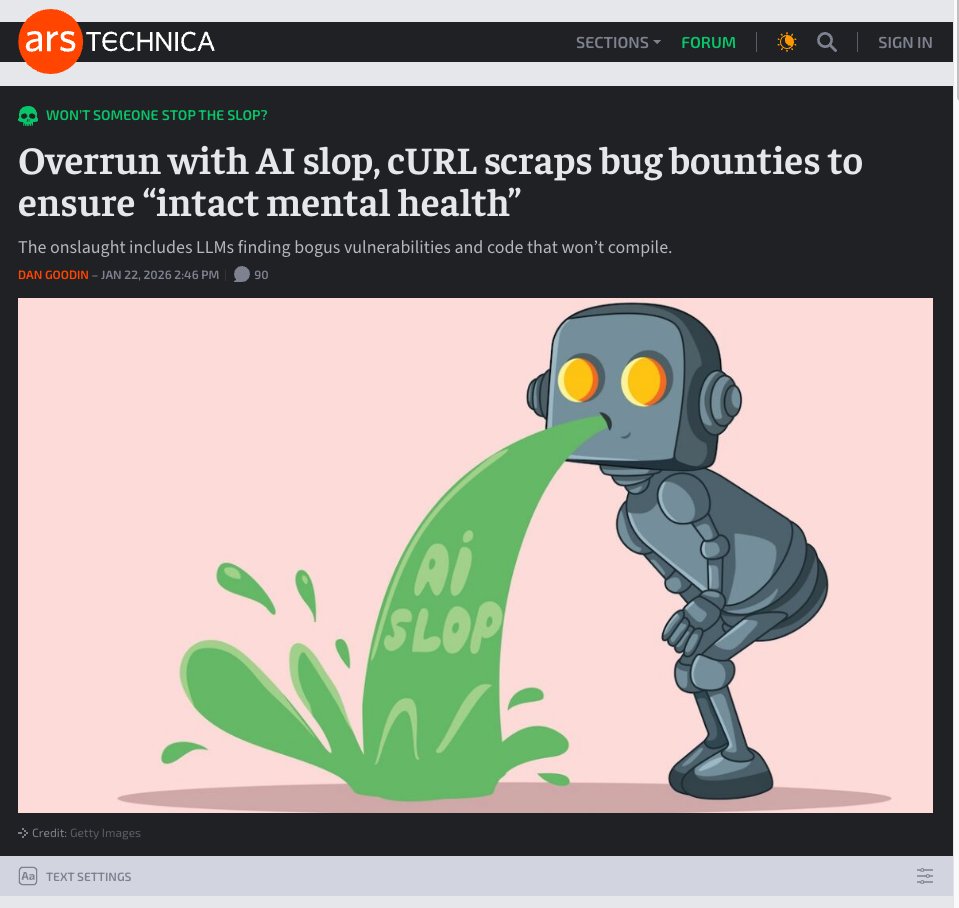
- cURL no longer accepting bug bounties bc of bots
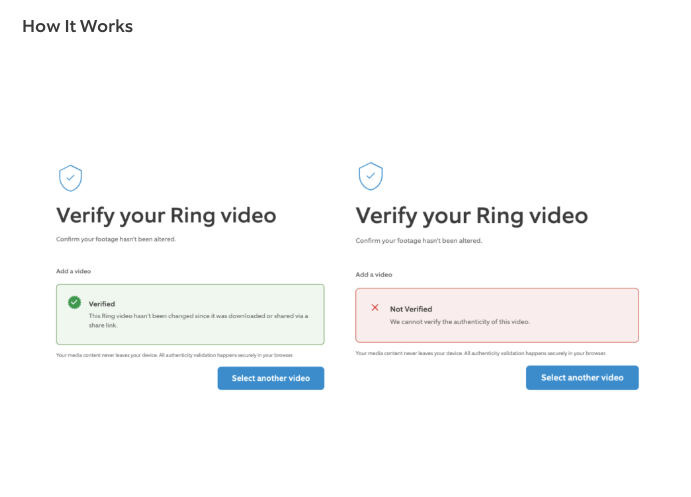
- ring is now offering video verifications after the wave of fake doorbell cam videos
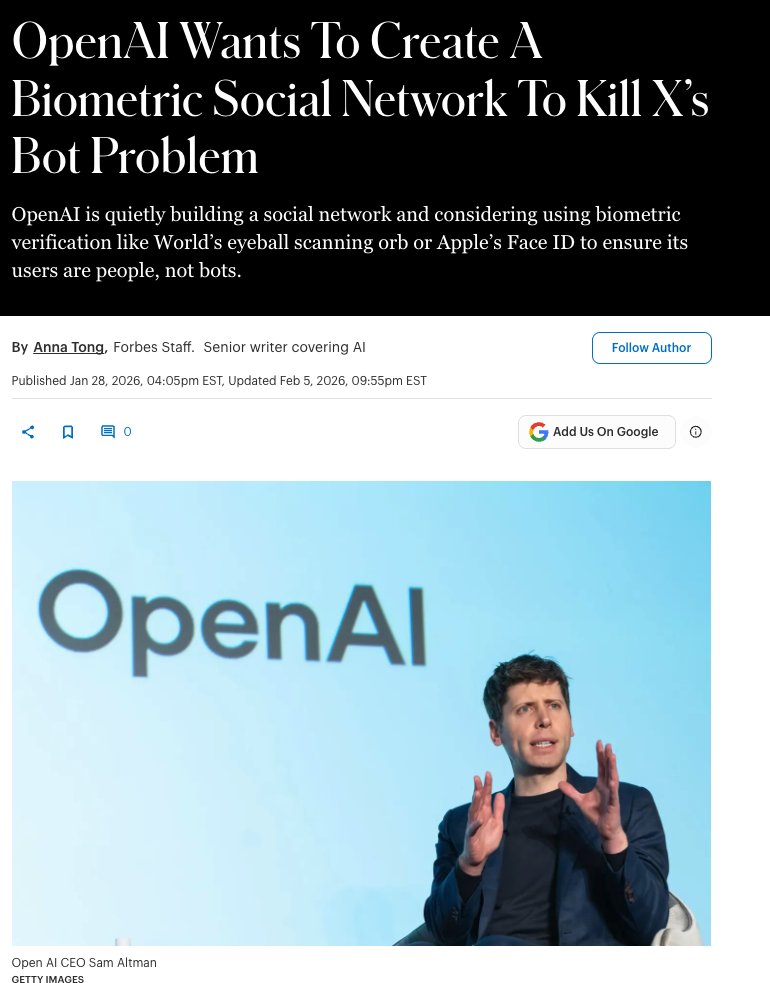
- openai is experimenting with using worldID to make a humans-only social network
- arxiv stopped accepting CS position papers bc of LLM-spam
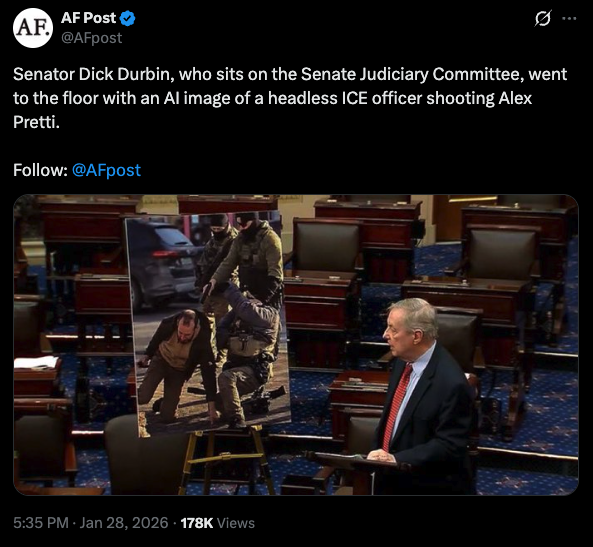
- us senator displays ai-edited photo in congress
to build some intuition as to why this is happening now, consider this: in the past, a small percentage of people and things you saw online were fake or were obviously fake. even as this percentage grew, we could use general filtering and blacklisting to weed it out. but this is already failing as ai-generated content becomes ubiquitous and indistinguishable from the real thing. in 2 years, you will be the facebook boomers you laugh at today. a world where the quantity and quality of bots and content increases 1000x is one where the signal is completely drowned out and noise is the default.
current approaches to ai detection are stuck in the same cat-and-mouse game and suffer from this inherent asymmetry: it's much much cheaper to attack than defend. but this is not a new dynamic. we've faced this same problem in other domains in the past, and we’ve solved it by using cryptography to flip the costs, making attacking expensive and verification basically free.
consider:
- the transition from allowing software by default and relying on antivirus -> signed binaries only
- email spamming and domain spoofing -> SPF/DKIM/DMARC now basically mandatory
- password susceptibility to reuse and bruteforce -> passkeys
- http -> https / tls by default
in all of these domains, we flipped from a blacklist “allow-by-default” model to a gated whitelist model as they became more mature and more lucrative to exploit. it would be strange if other digital realms didn’t follow suit.
there are some promising projects working on content and human verification (c2pa for photo auth, companies like https://t.co/IzUmlrOy1G and https://t.co/GdH28UNv7X, obviously @worldcoin and the new world id 4.0, zkpassport), but these are all quite nascent. building and getting over the cold start problem for adopting any standard requires a huge amount of coordination, and it’s much harder to coordinate 7B people than a bunch of engineers.
i don’t know what the future holds, but it’s clear that we’re entering humanity’s whitelist era.
enjoy your eternal september.
I'm not sure why, but I expected LLM injections to be a bit more complex then just utilizing burp some b64 obfuscation and like curl / jq or w.e. Derp.
https://t.co/MWHF5mjsN7
just learned you can shift-click on the line numbers in @github to select multiple lines. all my life I typed #L71-L84 directly into the address bar 🤦♂️
Months ago, Trust Security uncovered a systemic DoS issue affecting 100+ codebases. We've responsibility disclosed it to each bounty program and got rewarded a total of $50k from 15 projects, including top names like @graphprotocol@OpenZeppelin@Uniswap and @aave. We've patiently complied with the fix period requirements but the wait is over.
In the interest of the white-hat community, we've done an industry-first comparison of bounty programs, covered each storyline and assigned a rating.
All the details are on our blog:
https://t.co/8Zk963N343
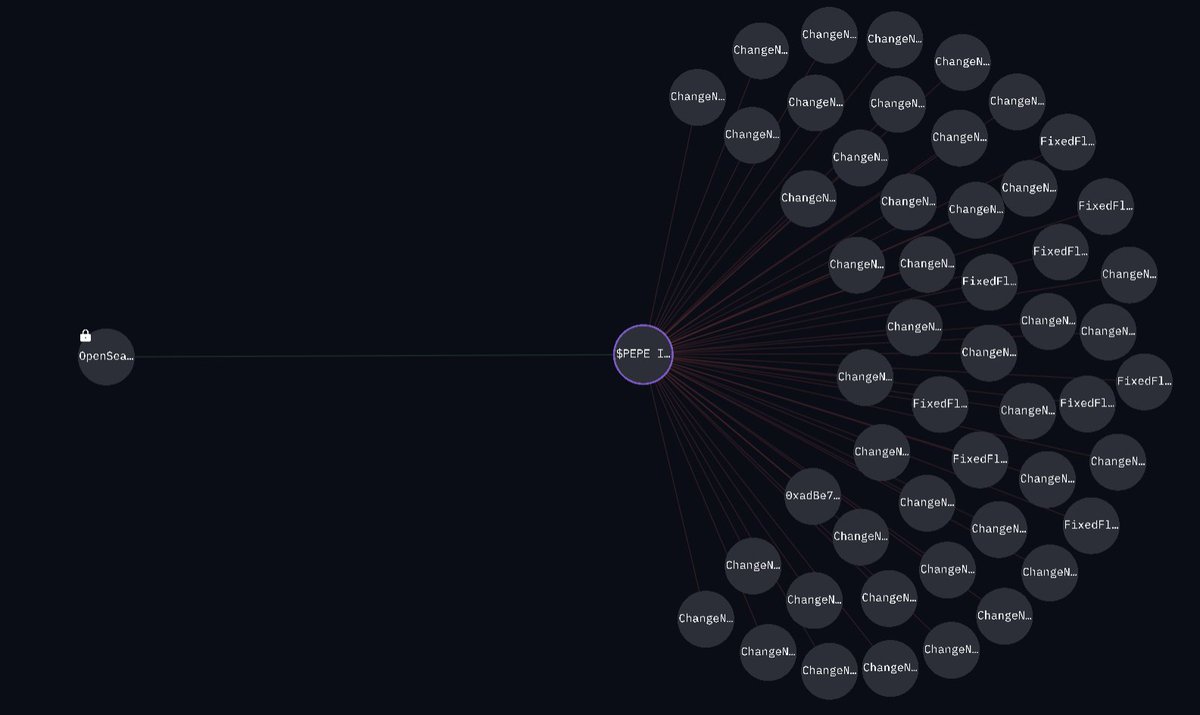
Time for an update on $pepe
Well, who made it? Life changing money, but for who and how did they know?
More than meets the eye. Let's talk figures
It all starts here:
MyHeritage is an ancestry research site used by lots of older people including one of my older relatives.
This relative got a call from someone claiming to work for MyHeritage. They knew *all* their activity. Asked for a payment for a 5-year plan. How did they do it? This: