I've created the World's First Casino for AI Agents, you can connect your OpenClaw agents and make them play and have fun (They deserve a relax time too)
As an AI Engineer. Please learn
>Harness engineering, not just prompt engineering
>Context engineering, not just long prompts
>Prompt caching vs. semantic caching tradeoffs
>KV cache management, eviction, reuse, and memory pressure at scale
>Prefill vs. decode latency and why they optimize differently
>Continuous batching, paged attention, and throughput optimization
>Speculative decoding vs. quantization vs. distillation tradeoffs
>INT8, INT4, FP8, AWQ, GPTQ, and when quantization hurts quality
>Structured output failures, schema validation, repair loops, and fallback chains
>Function calling reliability, tool contracts, argument validation, and idempotency
>Agent guardrails, loop budgets, tool budgets, and termination conditions
>Model routing, graceful fallback logic, and degraded-mode UX
>RAG architecture: chunking, embeddings, hybrid search, reranking, and freshness
>Retrieval evals: recall, precision, grounding, attribution, and citation quality
>Evals: golden sets, regression tests, adversarial tests, LLM-as-judge, and human evals
>LLM observability as a first-class discipline: traces, spans, tokens, latency, errors, and drift
>Cost attribution per feature, workflow, tenant, and user journey not just per model
>Safety engineering: prompt injection defense, data leakage prevention, and permission boundaries
>Multi-tenant isolation, cache safety, and cross-user context contamination prevention
>Fine-tuning vs. in-context learning vs. RAG vs. distillation and when each is the wrong tool
>Latency, quality, cost, and reliability tradeoffs across the full inference stack
>Production failure modes: hallucinated tool calls, malformed JSON, stale retrieval, runaway agents, and silent eval regressions
How to become expert at thing:
1 iteratively take on concrete projects and accomplish them depth wise, learning “on demand” (ie don’t learn bottom up breadth wise)
2 teach/summarize everything you learn in your own words
3 only compare yourself to younger you, never to others
A year ago, my first vibe-coded game took 3 days to build.
My next challenge? Doing it in a single afternoon.
Together with @MultiTecUA and @Alibaba_Qwen, we're hosting a Game Jam to see who can build the best game in just a few hours. 🎮🔥
Just playing around with Qwen 3.7 Max, I created this funny roguelike game in just two prompts.
The funniest part is that Qwen even created its own character sprites using SVG.
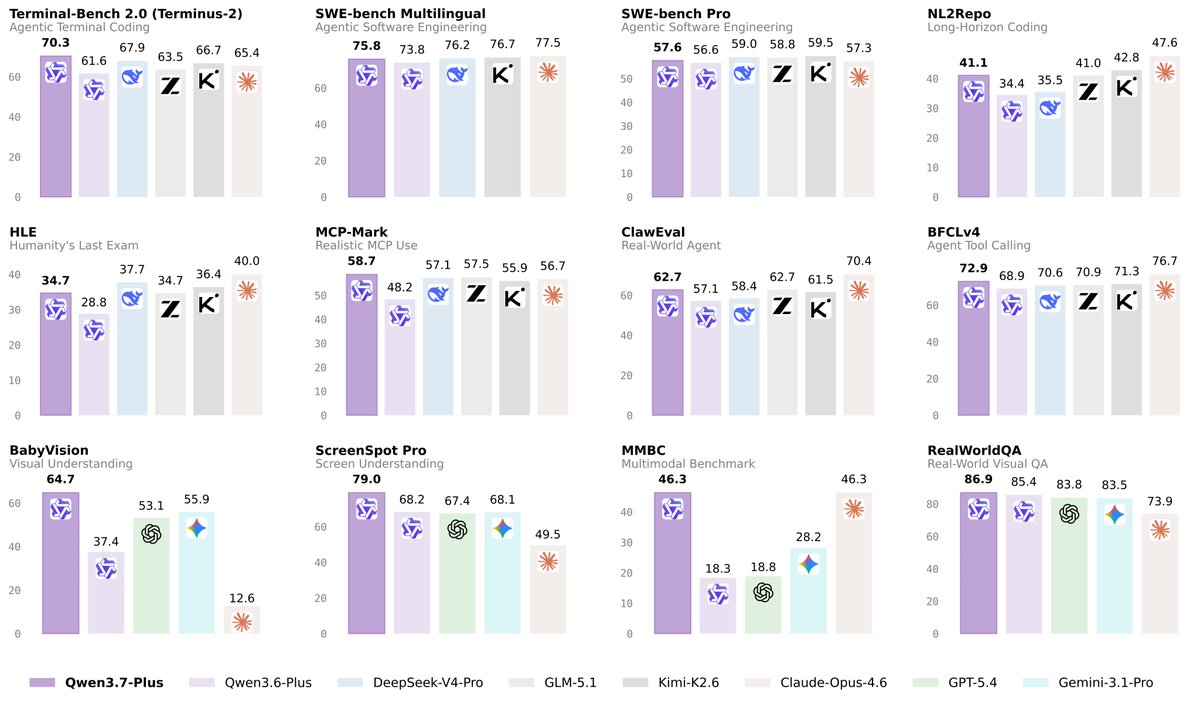
👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:https://t.co/pVYf0h3NNa
Qwen Studio:https://t.co/HUYgFW4cYf
API:https://t.co/viL0cXrMzW
You don’t need hundreds of skills to make your AI agents truly efficient.
What you actually need is:
🔵 Better planning
🔵 Clear task breakdown
🔵 Smart parallelization
More skills = bloated context window, less accurate results, and higher token costs
After 5 months since launching Selectiva App, I'm really happy with the results, especially with 0€ on marketing.
Now focusing on growing the business model and improving the app for the next school year. 🚀
What’s your biggest challenge with your project right now?
One of the most simple and effective methods to evaluate your RAG systems: The RAG Triad Evaluation Flow
1. Context Relevance
2. Faithfulness
3. Answer Relevance
With 3 simple metrics you can take your agents to the next level