🎞️✨ Have you ever imagined what happens if an object is NOT there?
Check out VOID, work led by our amazing intern @sammtmd to see how video diffusion models rewrite scenes after objects are removed!
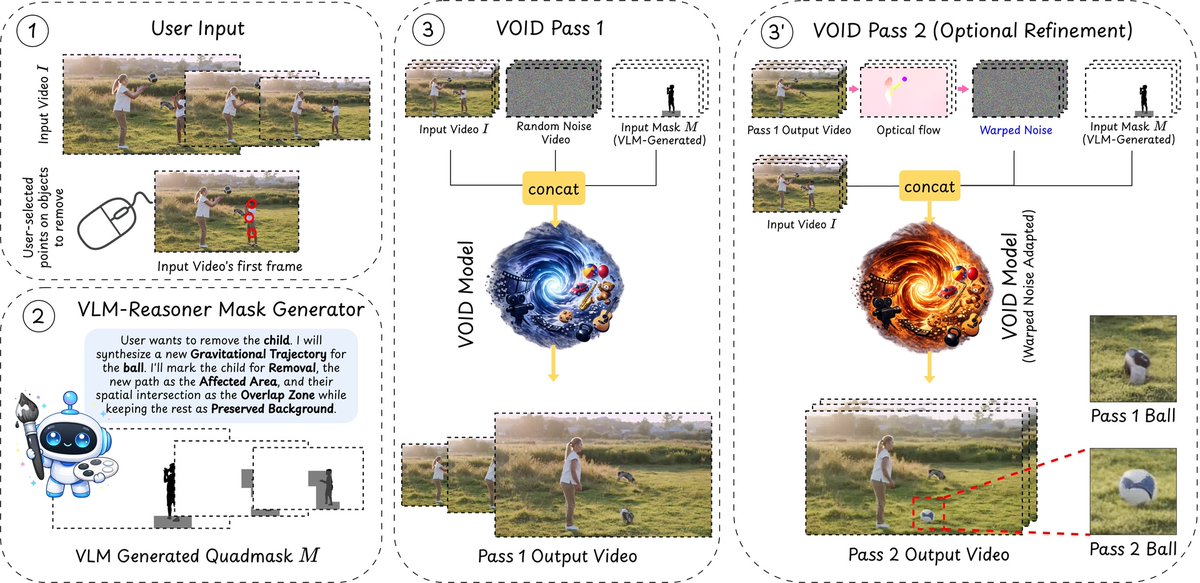
🎥🪄 What should happen when you remove an object from a video?
Example 1:
A domino chain is falling → remove the middle blocks → the last block should remain standing
Example 2:
Two cars are about to crash → remove one car → the other should drive away 🚙
Current video object removal models fail at these dynamic scenarios.
We introduce VOID: a model that removes objects and updates the scene as if they were never there.
🏆 Preferred 64.8% of the time vs Runway Aleph, Gen-Omnimatte, ProPainter, and more.
🌐 Project page: https://t.co/PBAWjuwUea
💻 GitHub: https://t.co/nYTv4miPSt
🤗 Demo: https://t.co/9DZpYCBUeN
📄 arXiv: https://t.co/UymkQC6Yku
w/ @willarvey@ZhuoningYuan@ChengTim0708 and collaborators at @NetflixResearch and @INSAITinstitute
Netflix just released VOID on Hugging Face
A video inpainting model that removes objects and their physical interactions
Not just shadows, but things like objects falling when a person is removed
Slides from my talk on "Language as a Visual Format" at the Visual Generative Modeling workshop at CVPR (mostly derived from slides made by @hyojinbahng and @carolinemchan): https://t.co/CpKe1CZ5Ow
Imagine a Van Gogh-style teapot turning into glass with one simple slider🎨
Introducing MARBLE, material edits by simply changing CLIP embedding!
🔗 https://t.co/VOHGwUGFVZ
👏 Internship project with @prafull7, @markb_boss , @jampani_varun at @StabilityAI
🚀 Glad to see our All-Angles Bench (https://t.co/2GeMZmS31b) being adopted to evaluate 3D spatial understanding in Seed-1.5-VL-thinking along with OpenAI (o1) and Gemini 2.5 Pro..!
❗️❗️ Can MLLMs understand scenes from multiple camera viewpoints — like humans?
🧭 We introduce All-Angles Bench — 2,100+ QA pairs on multi-view scenes.
📊 We evaluate 27 top MLLMs, including Gemini-2.0-Flash, Claude-3.7-Sonnet, and GPT-4o.
🌐 Project: https://t.co/yT9aHD3fwm
BREAKING NEWS
The Royal Swedish Academy of Sciences has decided to award the 2024 #NobelPrize in Physics to John J. Hopfield and Geoffrey E. Hinton “for foundational discoveries and inventions that enable machine learning with artificial neural networks.”
🎥 Today we’re premiering Meta Movie Gen: the most advanced media foundation models to-date.
Developed by AI research teams at Meta, Movie Gen delivers state-of-the-art results across a range of capabilities. We’re excited for the potential of this line of research to usher in entirely new possibilities for casual creators and creative professionals alike.
More details and examples of what Movie Gen can do ➡️ https://t.co/M19x2ndwnr
🛠️ Movie Gen models and capabilities
Movie Gen Video: 30B parameter transformer model that can generate high-quality and high-definition images and videos from a single text prompt.
Movie Gen Audio: A 13B parameter transformer model that can take a video input along with optional text prompts for controllability to generate high-fidelity audio synced to the video. It can generate ambient sound, instrumental background music and foley sound — delivering state-of-the-art results in audio quality, video-to-audio alignment and text-to-audio alignment.
Precise video editing: Using a generated or existing video and accompanying text instructions as an input it can perform localized edits such as adding, removing or replacing elements — or global changes like background or style changes.
Personalized videos: Using an image of a person and a text prompt, the model can generate a video with state-of-the-art results on character preservation and natural movement in video.
We’re continuing to work closely with creative professionals from across the field to integrate their feedback as we work towards a potential release. We look forward to sharing more on this work and the creative possibilities it will enable in the future.
#NeurIPS#NeurIPSConf
Thrilled to share that our paper SpatialPIN has been accepted at #NeurIPS2024!
We introduce a modular plug-and-play framework that progressively enhances VLMs' 3D reasoning by prompting and interacting with 3D foundational models.
(1/8)