🎥🪄 What should happen when you remove an object from a video?
Example 1:
A domino chain is falling → remove the middle blocks → the last block should remain standing
Example 2:
Two cars are about to crash → remove one car → the other should drive away 🚙
Current video object removal models fail at these dynamic scenarios.
We introduce VOID: a model that removes objects and updates the scene as if they were never there.
🏆 Preferred 64.8% of the time vs Runway Aleph, Gen-Omnimatte, ProPainter, and more.
🌐 Project page: https://t.co/PBAWjuwUea
💻 GitHub: https://t.co/nYTv4miPSt
🤗 Demo: https://t.co/9DZpYCBUeN
📄 arXiv: https://t.co/UymkQC6Yku
w/ @willarvey@ZhuoningYuan@ChengTim0708 and collaborators at @NetflixResearch and @INSAITinstitute
This was a lot of fun to work on! And works well with test-time guidance: we can train on varying-length RoboDesk videos and then, at test-time, fix the first and last frames and automatically figure out how far apart they are - i.e. how long the robot needs to move between them!
How can we apply diffusion models to data with varying dimensionality? We use jump diffusions to simultaneously generate the size and state values for varying size data e.g. molecules
https://t.co/99SvKR0NZs
w/ @willarvey@wh1lo@ValentinDeBort1@tom_rainforth@ArnaudDoucet1
This paper is a goldmine for anyone training diffusion models, carefully picking apart theory and practice and showing which choices really matter.
I was quite excited to see the authors of the StyleGAN series of papers tackle this topic, and boy do they deliver!
@sirbayes@frankdonaldwood@sama@demishassabis@ylecun We know :) We cite Video Diffusion Models heavily in the paper (https://t.co/HYAJs6UKT7) but focus on long-term coherence, jointly generating frames up to 1000 timesteps apart (instead of 64 like the Google work). Anyone at google looking into scaling that model to longer videos?
Thanks for the shout out @frankdonaldwood - the videos still have occasional glitches but are much better after scaling from training on 1 GPU to 4 GPUs. Simply scaling further might be the right direction to take
I think, much more than large language models, this work might be the first glimpse of what the foundation model for vision-based planning for embodied real-world AGI might look like. @sama, @demishassabis, @ylecun who is going to scale this first?
https://t.co/jzkoU8l6Tx
@tejasdkulkarni@frankdonaldwood@sama@demishassabis@ylecun Maybe we can improve object/landmark permanence by conditioning frames on e.g. the corresponding camera position similar to GQN. But I sense that pixel-level models with lots of compute are likely to win out over anything much more structured than that
Flexible Diffusion Modeling of Long Videos
abs: https://t.co/Cx1BUqA7zM
demonstrate improved video modeling over prior work on a number of datasets and sample temporally coherent videos over 25 minutes in length
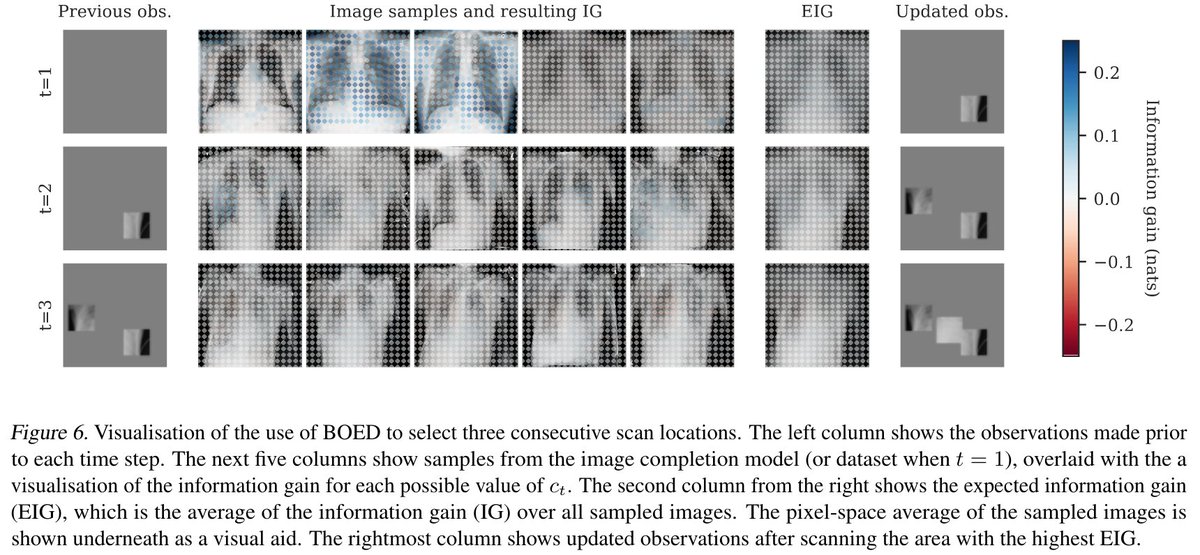
Our results suggest a possible future application of such high-fidelity image completion tools: they could be used to select maximally informative sequences of small field of view x-ray scans.
Excited to announce our work (https://t.co/2MYYfJ6Qyp) with hierarchical variational autoencoders - we found that they're ideal for making into realistic image completion models (with @saeidnaderip and @frankdonaldwood)