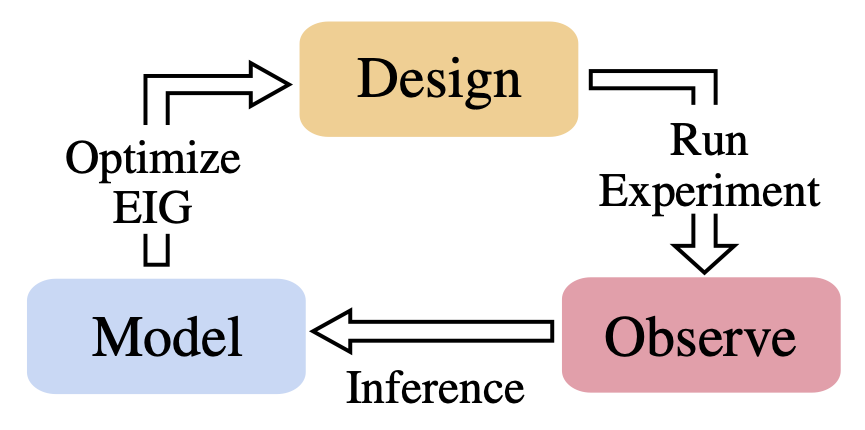
We've got really good at utilizing data. But methods for acquiring that data are often still rudimentary. Our new review paper shows how Bayesian experimental design has recently transformed to now provide a powerful mechanism to acquire data intelligently https://t.co/cAdxp3jI3b
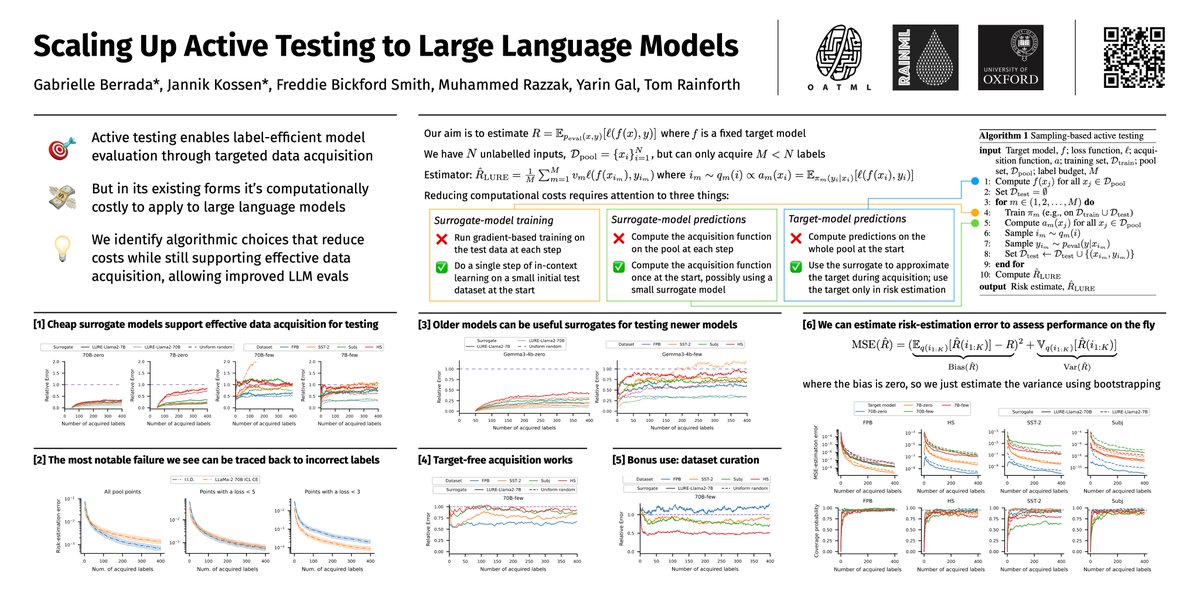
Active testing enables label-efficient model evals but can be computationally expensive.
We show how to reduce costs and scale up to LLMs.
https://t.co/rXkpQrJ7DY
Work led by Gabrielle Berrada. Find her at EurIPS, or @janundnik and me at NeurIPS in San Diego.
Apple and Oxford just made AI 6.5x better at problem-solving.
The secret: it teaches AI agents to ask perfect questions. This rockets success rates from 14% to 91%.
No need for fine-tuning or retraining. It runs on current models.
Here's how it works:
It's a strategic loop designed for multi-turn conversations. At every step, the agent works to find the shortest path to the right answer.
Hypothesize: The agent creates an internal list of all possible solutions to the problem.
Score Questions: It simulates asking various questions and scores each one on "Expected Information Gain" (EIG). This number represents how much a question is mathematically likely to shrink the list of possibilities.
Ask the Best Question: It asks the user only the single, highest-scoring question.
Update & Repeat: Based on the answer, it filters its list of hypotheses, getting smarter with each interaction, and then begins the loop again for the next turn.
Why this matters for your AI strategy:
This marks a shift from building passive "oracles" to proactive, question-asking agents
Business Leaders: A 6.5x multiplier on task success is a lever for efficiency. This translates to fewer failed customer interactions, faster diagnostics, and more accurate personalization, a clear ROI on smarter AI.
Practitioners: This is a deployment-time framework, not a new model. You can build this agent on top of existing LLMs today. It provides a principled way to overcome common multi-turn issues like inconsistency and context loss without fine-tuning or retraining.
Researchers: This paper is a victory for information theory. It proves that a full EIG calculation is superior to heuristics like predictive entropy. It sets a new standard for how to build intelligent information-seeking agents.
I have an opening for a 2-year postdoc in probabilistic machine learning and/or experimental design. The application deadline is the 3rd of September. See here for details and how to apply: https://t.co/ht9n9cEviw
I have an opening for a 2.5-year postdoc position in the RainML lab as part of my ERC grant on probabilistic machine learning and intelligent data acquisition. Application deadline 10th July 2024. See here for details and to apply: https://t.co/BWlBYBHMEv
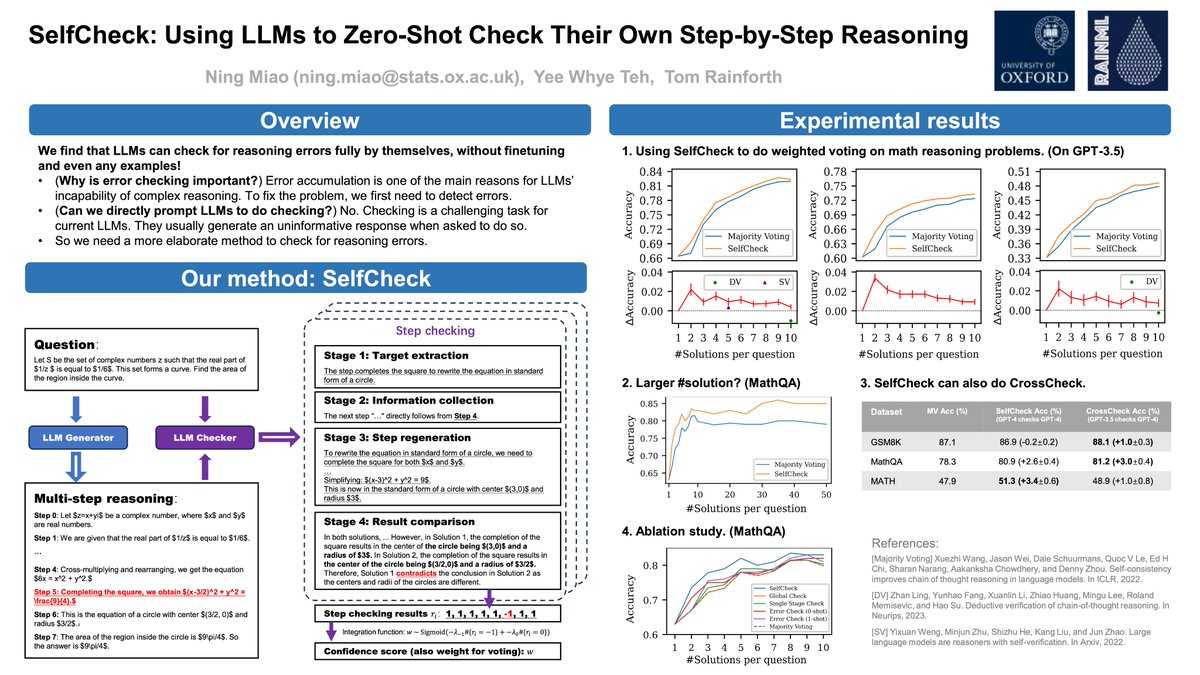
Our new #ICLR2024 paper shows how LLMs can successfully check their own change of thought reasoning without any fine-tuning or even examples, using an approach we call SelfCheck.
Join me at poster 125 this afternoon to learn more
Paper: https://t.co/47MXrN4xDi
In-context learning can learn novel input-output relationships beyond what can be picked up from input context alone, but doesn't behave like conventional learning algorithm. Find out more at our ICLR poster #129 this afternoon. Paper: https://t.co/NoJWC3Ws9J, led by @janundnik
Are you at ICLR?
Have you heard that In-Context Learning in LLMs does not learn label relationships?
Well that's not true.
Visit our poster TODAY to find out how LLMs incorporate label information.
Spoiler: it's not Bayesian inference.
Poster #129, May 7, 4.30 pm
I will be presenting our work on "Beyond Bayesian Model Averaging over Paths in Probabilistic Programs with Stochastic Support" at AISTATS in Valencia tomorrow (details in thread below).
If you are interested in probabilistic programming, come and say hi at poster session 1!
The current default recipe for Bayesian active learning doesn’t really work beyond MNIST scale.
We suggest why that is and identify a simple fix.
https://t.co/TgmxX2RonT
@aistats_conf with @adamefoster@tom_rainforth
1/5
@haus_cole We did this as a pretty direct follow up: https://t.co/8CiZiM48hq. I think unfortunately the reality is that disentanglement is not generally viable without either strong inductive biases or some degree of supervision