This idea that intelligence is solely a function of what you've observed since birth and not also a function of the 500 million years of evolution that preceded your birth is surprisingly sticky despite being demonstrably untrue.
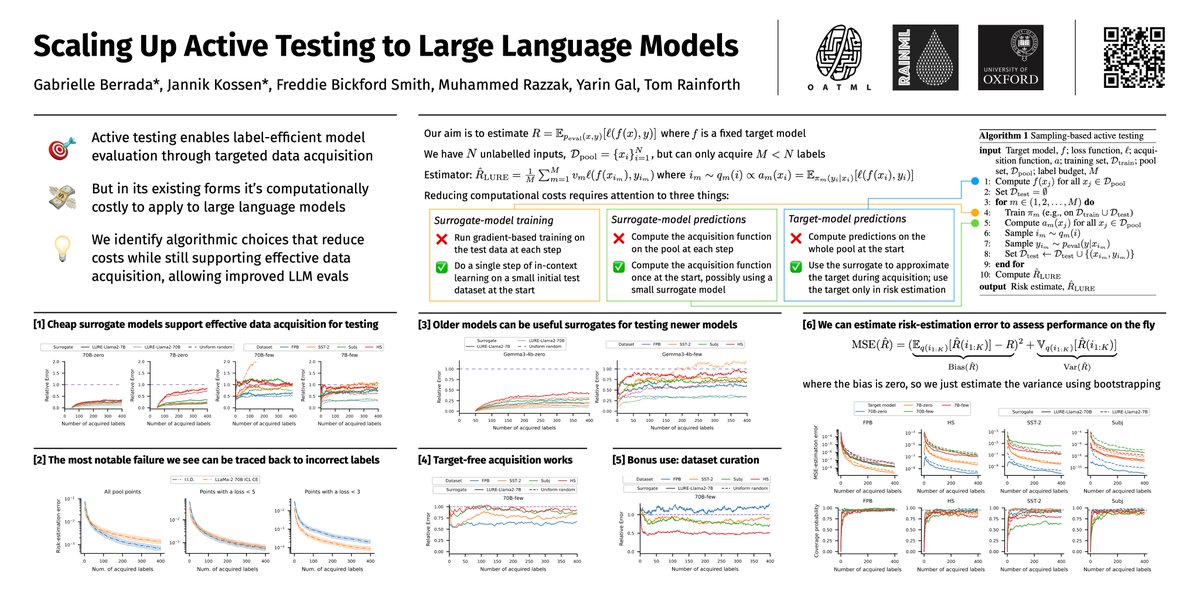
Active testing enables label-efficient model evals but can be computationally expensive.
We show how to reduce costs and scale up to LLMs.
https://t.co/rXkpQrJ7DY
Work led by Gabrielle Berrada. Find her at EurIPS, or @janundnik and me at NeurIPS in San Diego.
Come and check out our work on how to evaluate LLMs with less compute and fewer labels!
Find first author Gabrielle at EurIPS or Freddie and I at poster 110 at the 11 AM session on Friday.
I crossed an interesting threshold yesterday, which I think many other mathematicians have been crossing recently as well. In the middle of trying to prove a result, I identified a statement that looked true and that would, if true, be useful to me. 1/3
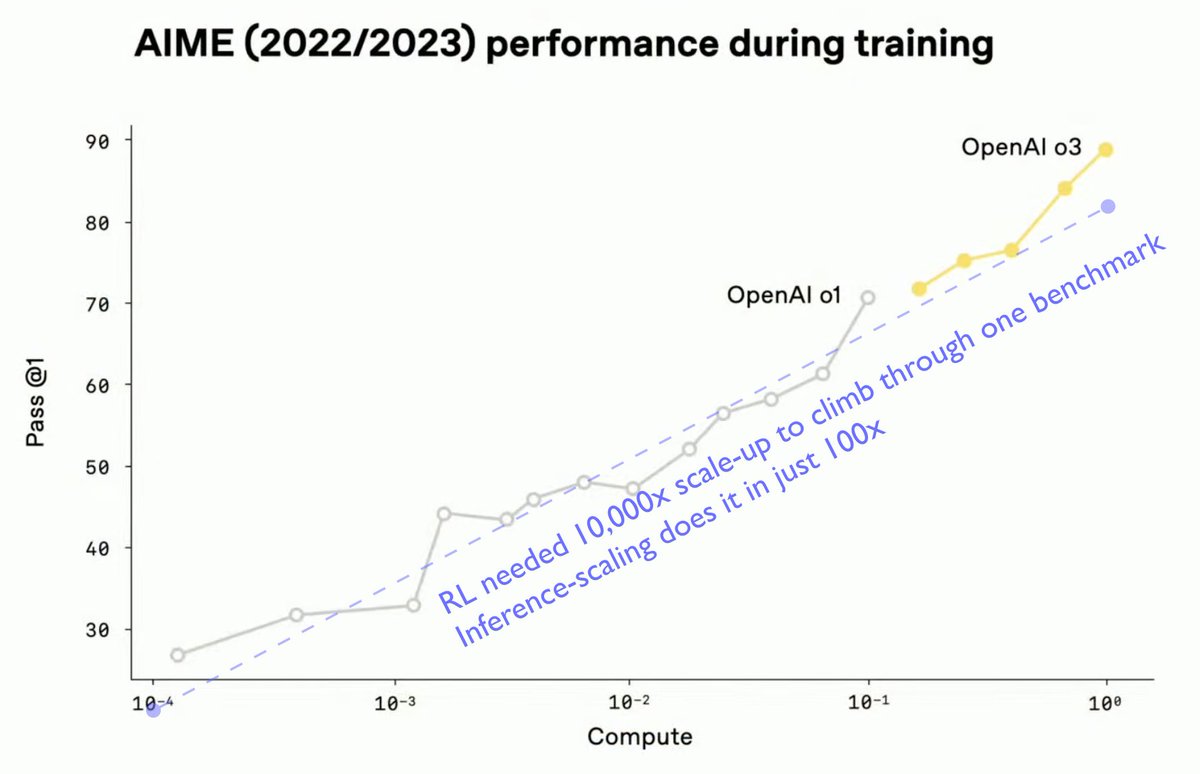
New post on RL scaling:
Careful analysis of OpenAI’s public benchmarks reveals RL scales far worse than inference: to match each 10x scale-up of inference compute, you need 100x the RL-training compute. The only reason it has been cost-effective is starting from a tiny base.
🧵
Every so often, OpenAI employees ask me how I see the co now.
It's always tough to give a simple answer. Some things they're doing, eg on CoT monitoring or building out system cards, are great.
But the dishonesty & intimidation tactics in their policy work are really not. E.g:
With @JesusOxford we are looking for a Professor of Statistics.
Become part of a historic institution and a community focused on academic excellence, innovative thinking, and significant practical application.
About the role: https://t.co/mzBacAoCiv
Deadline: 15 September
Research on AI "sandbagging" is getting more popular recently. In this 🧵, I'll give some reasons that I think it's not a useful research paradigm.
TL;DR, I think it's a confusing reframing of fairly well studied and previously solved problems.
It's great the governments (and others) continue to demonstrate that the models companies release are incredibly insecure.
It's terrible that governments aren't penalizing companies for releasing such insecure models, and instead just help them patch them.
@_rockt@andrewgwils More like (1) the future resembles the past and (2) you can capture the resemblances in your model, right? The existence of the future doesn’t imply you can predict it.
Just two years ago, our smartest models could barely solve the easiest competitive programming problems. Last week, our latest reasoning models achieved a gold medal score at the International Olympiads of Informatics. Competitive programming is one of the cleanest examples of scaling up RL training for LLMs. Soon, with experimental approaches like the one used for IMO, we might see similar scaling on real-world coding problems.
Today I’m releasing an essay series called Better Futures.
It’s been something like eight years in the making, so I’m pretty happy it’s finally out!
It asks: when looking to the future, should we focus on surviving, or on flourishing?
I have an opening for a 2-year postdoc in probabilistic machine learning and/or experimental design. The application deadline is the 3rd of September. See here for details and how to apply: https://t.co/ht9n9cEviw
I'm looking for talented and ambitious PhD students to join me at Nanyang Technological University Singapore to work on safe and robust AI systems!
Full scholarships covering tuition and a stipend are available, and are open to local and international students alike.
In a new paper, we examine recent claims that AI systems have been observed ‘scheming’, or making strategic attempts to mislead humans. We argue that to test these claims properly, more rigorous methods are needed.