@DHolzmueller@BlackHC The way I see it, there's only one true AU and that does not depend on the epistemic state of the learner (i.e., that it's a Dirac mixture). The *estimate* of AU does, and it will be 0 for x=0, but is that reliable in this situation of utter conflict?
If we understand your criticism correctly, it boils down to a concept of disagreement rather than ignorance and lack of knowledge, which is what epistemic uncertainty is actually supposed to capture. Please note that your suggestion of a second-order distribution ...
Reading "Quantifying Aleatoric and Epistemic Uncertainty in Machine Learning: Are Conditional Entropy and Mutual Information Appropriate Measures?" and not as impressed I had hoped to be.
I think it is a good example for why descriptive/axiomatic approaches to uncertainty can be wrong/not helpful.
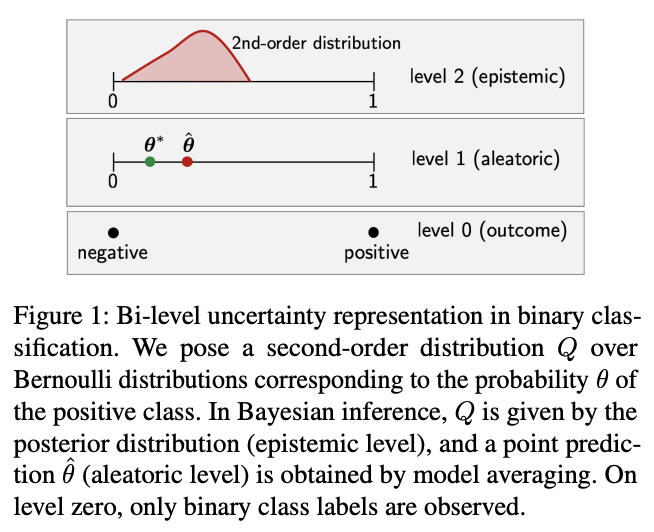
The paper looks at second-order distributions: when our model provides a distribution of distributions.
E.g. a Dirichlet distribution (below) is a distribution over the simplex which can be seen as the probabilities of a categorical distribution (here for 3 classes).
For example, we have a deep ensemble and each ensemble member predicts a categorical distributions. Then the set of all predictions is an empirical distribution of distributions, and we can define uncertainty measures on it.
In particular:
- aleatoric uncertainty: (predicted) irreducible observation noise,
- epistemic uncertainty: (predicted) reducible noise - if we had more data, the model might give us better predictions,
- total uncertainty: something that measures both of the above together.
Epistemic uncertainty can be connected to prediction disagreement between ensemble members. The more different ensemble members disagree on a given sample, the more we would learn if we had more data (as we can cull more of the hypothesis space, or redistribute more probability mass in our parameter distribution).
Let's assume we look at classification.
The paper proposes the following properties (that partially mostly make no sense to) and then examines whether the common EU/AU/TU decomposition satisifes them:
A0 TU, AU, and EU are non-negative.
A1 EU vanishes for Dirac measures Q=\delta_\theta.
A2 EU and TU are maximal for Q being the uniform distribution on \Delta_K^{(2)}.
A3 If Q' is a mean-preserving spread of Q, then EU(Q') >= EU(Q) (weak version) or EU(Q') > EU(Q) (strict version); the same holds for TU.
A4 If Q' is a center-shift of Q, then AU(Q') >= AU(Q) (weak version) or AU(Q') > AU(Q) (strict version); the same holds for TU.
A5 If Q' is a spread-preserving location shift of Q, then EU(Q')=EU(Q).
A0 might be sensible --- or if uncertainty was in -\inf, +inf, we could always use exp(.) to make it non-negative.
A1 makes sense: if all models output the same distribution, we won't have any epistemic uncertainty.
A2 is already wrong, however:
Predictions from different ensemble members should have the highest epistemic uncertainty, when they disagree the most with each other. That is the case, when every ensemble member predicts a different class with 100% confidence. In the image above, this would mean that our second-order distribution is concentrated in the corners.
But this is not a uniform distribution in the space of second order distributions.
Otoh if any ensemble member had shared class predictions (conf > 0 for a class) with another member, obv, their disagreement wouldn't be maximal already.
So A2 is wrong (imo).
But this also takes down A3: A3 says that if we "spread" out the distributions in the second-order space, EU has to increase (or at least not decrease). But this is not true: if our second-order distribution is concentrated in the corners (EU is maximal), spreading it out can only decrease EU. Hence, a contradiction to A3.
A5 is similarly flawed then. It says that if we move our concentration around (but preserve "everything else"), EU has to stay constant.
However, let's imagine we have 2 ensemble members predict in a 3-class case, with predictions (0, 1/2, 1/2), and (1/3, 1/3, 1/3), resp (in Dirichlet plot this would be the middle of the x3 edge and the center) . Now let's imagine we shift everything up: to (1/3, 1/3, 1/3) and (1, 0, 0) (in the plot center and upper corner). Again, the disagreement (and EU) is stronger in the latter configuration than in the former, so A5 does not make sense either.
Obviously, one could equally argue that my takes on disagreement do not make sense.
However, I believe that epistemic uncertainty via disagreement is empirically grounded in the expected information gain (via lots of evidence). (There is more to be said at which information gain we want to look at exactly, but that is for a different post.)
But maybe the more acceptable challenge is to why the proposed properties in this paper should be considered natural.
@DHolzmueller@BlackHC That illustrates the point quite well, I guess - the reported AU is 0, but should we trust this estimate? The answer is no, I think, because disagreement (or indeed, EU, according to Andreas :)) is high, so there's good reason to be wary
@BlackHC@DHolzmueller That point kind of echoes our discussion in the paper: at least, we can only hope to get a reasonable estimate of AU when EU is low; otherwise, the estimate will not be trustworthy
@DHolzmueller@BlackHC I guess that by definition, these 2 must be the same - if we're willing to accept that total = aleatoric + epistemic uncertainty, and the aleatoric component is non-reducible, right?
@BlackHC I'm not saying disagreement shouldn't be part of the story, just not all of it :) but how does "ignorant about the truth" become manifest here? the learners don't *signal* ignorance, quite the opposite. plus imo: max reduction = max concentration potential, so back to uniform 🙃
It is also commonly taken as "noninformative" prior in Bayesian inference (where your model would cause an inconsistency as soon as the data contains observations from both classes).
Happy to discuss further! 🙌
We agree that the uniform distribution can also be questioned as a model a complete ignorance, but as long as knowledge must be represented in terms of probability, is is commonly accepted as a best choice (justified, e.g., by the max entropy principle).
📢The 2023 Best Paper Award for the Research Track goes to "Towards Efficient MCMC Sampling in Bayesian Neural Networks by Exploiting Symmetry" by Jonas Gregor Wiese, Lisa Wimmer, Theodore Papamarkou, Bernd Bischl, Stephan Günnemann, David Rügamer 🥳 congrats to the authors!
Great insights about multi-source uncertainty based on a recent preprint by my wonderful colleague @CoGruber 🔥 read for a truly holistic story, made in Statistics, that starts with the data https://t.co/TCjy8Ai32q
If I say that there is irreducible (aleatoric) uncertainty in every ML task, that doesn't mean I don't believe in determinism of the physical world. Here's why: 🧵1/9