Thrilled to see this recognition! 🚀 The optimizations are the result of excellent teamwork with our @radixark@nvidia and @lmsysorg collaborators. Huge thanks to the entire team! 🙏
Amazing work from the @sgl_project and @radixark team for their work optimizing DeepSeek V4 inference on B200, B300, and the recent 4x iso-interactivity throughput improvements on GB300 by @ChengWan17! As @elonmusk said, The GB300 is the best AI computer, and software optimizations like this show its true potential!
Career update: I resigned from the inference team at @xai and joined @radixark last month.
Excited to build open and efficient AI infra — making frontier-grade training & serving accessible to everyone. The SGLang/Miles momentum is unreal, and the team is shipping fast. 🚀
Today, we are thrilled to officially launch RadixArk with $100M in Seed funding at a $400M valuation. The round was led by @Accel and co-led by @sparkcapital.
RadixArk exists to make frontier AI infrastructure open and accessible to everyone. Today, the systems behind the most capable AI models are concentrated in a small number of companies. As a result, most AI teams are forced to rebuild training and inference stacks from scratch, duplicating the same infrastructure work instead of focusing on new models, products, and ideas.
RadixArk was founded to change that. We are building an AI platform that makes it easier for teams to train and serve the best models at scale.
RadixArk comes from the open-source community. We started with SGLang, where many of us are core developers and maintainers, and expanded our work to Miles for large-scale RL and post-training. We will continue contributing to both projects and working with the community to make them the strongest open-source infrastructure foundations for frontier AI.
We would like to thank our long-term partners, contributors, and the broader SGLang community for believing in this mission. We're also grateful to @Accel and @sparkcapital, NVentures (Venture capital arm of @nvidia), Salience Capital, A&E Investment, @HOFCapital, @walden_catalyst, @AMD, LDVP, WTT Fubon Family, @MediaTek, Vocal Ventures, @Sky9Capital and our angel investors @ibab, @LipBuTan1, Hock Tan, @johnschulman2, @soumithchintala, @lilianweng, @oliveur, @Thom_Wolf, @LiamFedus, @robertnishihara, @ericzelikman, @OfficialLoganK, and @multiply_matrix among others.
Thanks for the exclusive interview with @MeghanBobrowsky at @WSJ about our vision.
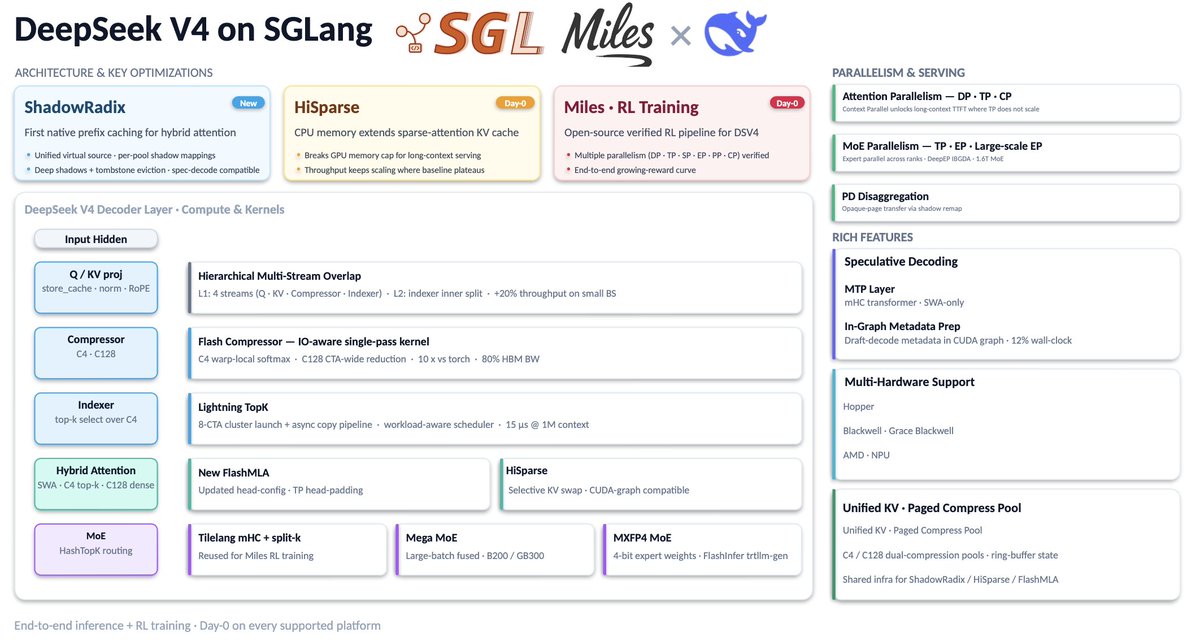
DeepSeek V4 by @deepseek_ai just dropped! SGLang is ready on Day 0 with a full stack of optimizations from architectures to low-level kernels. We also deliver a verified RL training pipeline in Miles (by @radixark) for V4 at launch:
1️⃣ Native "ShadowRadix" Design: DeepSeek V4's hybrid attention is complex. Our new ShadowRadix engine is the first to provide native prefix caching for SWA and compressed KV pools, making 1M+ context retrieval seamless and memory-efficient.
2️⃣ High-Performance Kernels:
- Flash Compressor: IO-aware fused kernels, 10x faster than naive implementations.
- Lightning TopK: High-speed indexing for 1M context in just 15µs.
- Integrate FlashInfer trtllm-gen MoE, FlashMLA, and MegaMoE kernels
3️⃣ Rich Features: Speculative decoding, HiSparse, Attention DP/TP/CP and MoE TP/EP, and multi-platform support
4️⃣ Verified RL: The open-source RL pipeline: full parallelism (DP/TP/EP/PP/CP), tilelang kernels, tensor-level checked precision, verified with growing reward.
Get started immediately with our out-of-the-box Cookbook 👇
Enjoy! #DeepSeekV4 #SGLang #LLM
🎉 Congrats to the DeepSeek team on the amazing release of Sparse Attention (DSA) in V3.2! This fine-grained design sets a new bar for long-context efficiency 🚀
We’re proud that SGLang is an official inference framework for DeepSeek-V3.2 — with optimized sparse attention kernels, dynamic KV cache, and seamless scaling to 128K tokens.
Try it out today and feel the speed of SGLang ⚡ 👉
Deployment guide: https://t.co/vdhVvhNrkI
DeepSeek tech report: https://t.co/XsPeYJtIba
HuggingFace page: https://t.co/n7ScTsyDGL