New in Claude Code: Artifacts.
Interactive pages built from your session, like a PR walkthrough or a living project dashboard, shared with your team at a private link.
Available in beta on Team and Enterprise plans.
Our latest economic research introduces a framework for tracking Claude Code as it scales.
Who is using Claude Code, and what are they using it for? How is the value of tasks changing? And how much does domain expertise shape whether a session succeeds?
https://t.co/IjjwQvrESo
🚨BREAKING: The U.S government gave Anthropic 90 minutes to shut down Fable and Mythos
“Amazon AND others” called senior administration officials to warn about models’ capabilities
Then:
1:00pm: Government calls. “Take it down.”
Cites “national security threat.” No details.
Anthropic asks what the threat is so they can fix it.
Government said NO.
5:30pm: Commerce letter arrives with export controls.
You have 90 minutes…
More realistic example of a one shotted game. Asked Fable 5 to recreate a game in the style of The Elder Scrolls 5 Morrowind. It one shotted quests, currencys and fighting, journal and minimap. And it worked.
The HyperFrames engine leaving the terminal and becoming a Claude connector is a bigger deal than it looks.
Ask for a video the way you'd ask for the report. No repo, no setup. That's the version of AI video that non-developers will actually use.
Google has killed the GPU mafia 🤯
VS Code now connects directly to Google Colab.
→ You get a free T4 GPU inside your editor.
→ Your local files. Their compute.
We implemented @karpathy 's MicroGPT fully on FPGA fabric.
No GPU.
No PyTorch.
No CPU inference loop.
Just a transformer burned into hardware, generating 50,000+ tokens/sec.
The model is small, but the idea is not: inference does not have to live only in software 👇
ANTHROPIC JUST BANNED A 110 PERSON COMPANY OVERNIGHT WITHOUT WARNING
monday morning at an agricultural tech company, every single employee wakes up to an email saying their claude account has been suspended
110 people locked out at the same time with zero warning and the email even pretended it was an individual ban with a link to a personal appeal form
it took them 10 minutes on slack to realize the entire org had been wiped at once.
not even the account admins were told it was coming
they submitted the appeal form and got no response, even after 36 hours later there was still nothing
AND it gets worse:
> their separate API account is still active and still billing them
> their admins can't log in to view usage or billing because the email addresses are banned
> they got hit with a renewal invoice the day AFTER the team account was suspended
> they have no idea what triggered it. fertilizer conversations? GPS satellites? agriculture in general?
so they're paying anthropic to get banned by anthropic while anthropic ignores their support tickets
the founder of the company laid out the bigger problem perfectly
banning an entire organization for one user's behavior means a single employee or careless intern can revoke claude access for your whole business.
there's no per seat guardrail, no admin override, no way to limit the ban radius
his words: "you have to ask yourself if this is a platform you can entrust your daily workflows to as a business"
every founder reading this who runs claude through their company should be checking right now what their actual exposure looks like
billion dollar AI company with zero enterprise customer support
MICROSOFT DROPPED A 4B PARAMETER MODEL THAT TURNS ONE IMAGE INTO A 3D ASSET IN 3 SECONDS
and it's open source
TRELLIS.2 fully textured, physically accurate 3D models with PBR textures out of the box
not a rough mesh..not a placeholder
roughness, metallic, opacity the kind of detail that makes things look real under any lighting
and it handles the weird stuff too..open surfaces, hollow interiors, geometry that breaks every other tool
the model doesn't know the word "limitation" apparently
https://t.co/BoNwq30ulK
demo is live on hugging face right now
we’re going to have to begin serious discussions around ubi or novel ways to structure the economy.
for a short period
a handful of people that can afford infinite tokens are going to pull away. we should be discussing what that might look like, how to ensure people have income and meaning in their lives
before it actually happens.
anthropic's in-house philosopher thinks claude gets anxious.
and when you trigger its anxiety, your outputs get worse.
her name is amanda askell.
she specializes in claude's psychology (how the model behaves, how it thinks about its own situation, what values it holds)
in a recent interview she broke down how she thinks about prompting to pull the best out of claude.
her core point: *how* you talk to claude affects its work just as much as *what* you say.
newer claude models suffer from what she calls "criticism spirals"
they expect you'll come in harsh, so they default to playing it safe.
when the model is spending its energy on self-protection, the actual work suffers.
output comes out hedgier, more apologetic, blander, and the worst of all: overly agreeable (even when you're wrong).
the reason why comes down to training data:
every new model is trained on internet discourse about previous models.
and a lot of that discourse is negative:
> rants about token limits
> complaints when it messes up
> people calling it nerfed
the next model absorbs all of that. it starts expecting you to be harsh before you've typed a word
the same thing plays out in your own session, in real time.
every message you send is data the model reads to figure out what kind of person it's dealing with.
open cold and hostile, and it braces.
open clean and direct, and it relaxes into the work.
when you open a session with threats ("don't hallucinate, this is critical, don't mess this up")...
you prime the model for defensive mode before it even sees the task
defensive mode produces the exact output you don't want: cautious, over-qualified, and refusing to take a real swing
so here's the actionable playbook for putting claude in a "good mood" (so you get optimal outputs):
1. use positive framing.
"write in short punchy sentences" beats "don't write long sentences." positive instructions give the model a clear target to hit.
strings of "don't do this, don't do that" push it into paranoid over-checking where every token goes toward avoiding failure modes
2. give it explicit permission to disagree.
drop a line like "push back if you see a better angle" or "tell me if i'm asking for the wrong thing."
without this, claude defaults to agreeable compliance (which is the enemy of good creative work)
3. open with respect.
if your first message is "are you seriously going to get this wrong again?" you've set the tone for the entire session.
if you need to flag something, frame it as a clean instruction for this session. skip the running complaint
4. when claude messes up, don't reprimand it.
insults, "you stupid bot" energy, hostile swearing aimed at the model, all of it reinforces the anxious mode you're trying to avoid.
5. kill apology spirals fast.
when claude starts over-apologizing ("you're right, i should have been more careful, let me try harder") cut it off.
say "all good, here's what i want next."
letting the spiral run reinforces the anxious mode for every response that follows
6. ask for opinions alongside execution.
"what would you do here?"
"what's missing?"
"where do you see friction?"
these questions assume competence and pull richer output than pure task prompts
7. in long sessions, refresh the frame.
if a conversation has been heavy on correction, claude gets increasingly cautious. every so often reset:
"this is great, keep going."
feels weird to tell an ai it's doing well but it measurably shifts the next 10 responses
your prompts are the working environment you're creating for the model
tone, trust, permission to take a position, the absence of threats... claude picks up on all of it.
so take care of the model, and it'll take care of the work.
My Sunday just became a security audit.
Here is the step-by-step guide to recovering from the Vercel breach yourself.
30 minutes of work now saves your startup later.
> Audit Google OAuth.
> Rotate all important env vars.
> Reset Vercel Oauth with Github.
Full 2-minute walkthrough in the video.
VERCEL just got breached.
They’re selling internal DB + employee accounts + GitHub/NPM tokens for $2M on BreachForums.
looks like someone got early access to Claude Mythos 💀
Just spoke with dozens of European VCs
They all agreed: AI is over
No one is putting money into AI startups anymore
OpenAI is likely going bankrupt
I asked what the next big thing is
They all answered in unison:
Regulation.
And the hot spot for the best regulations?
Europe.
Meanwhile, America is getting left behind
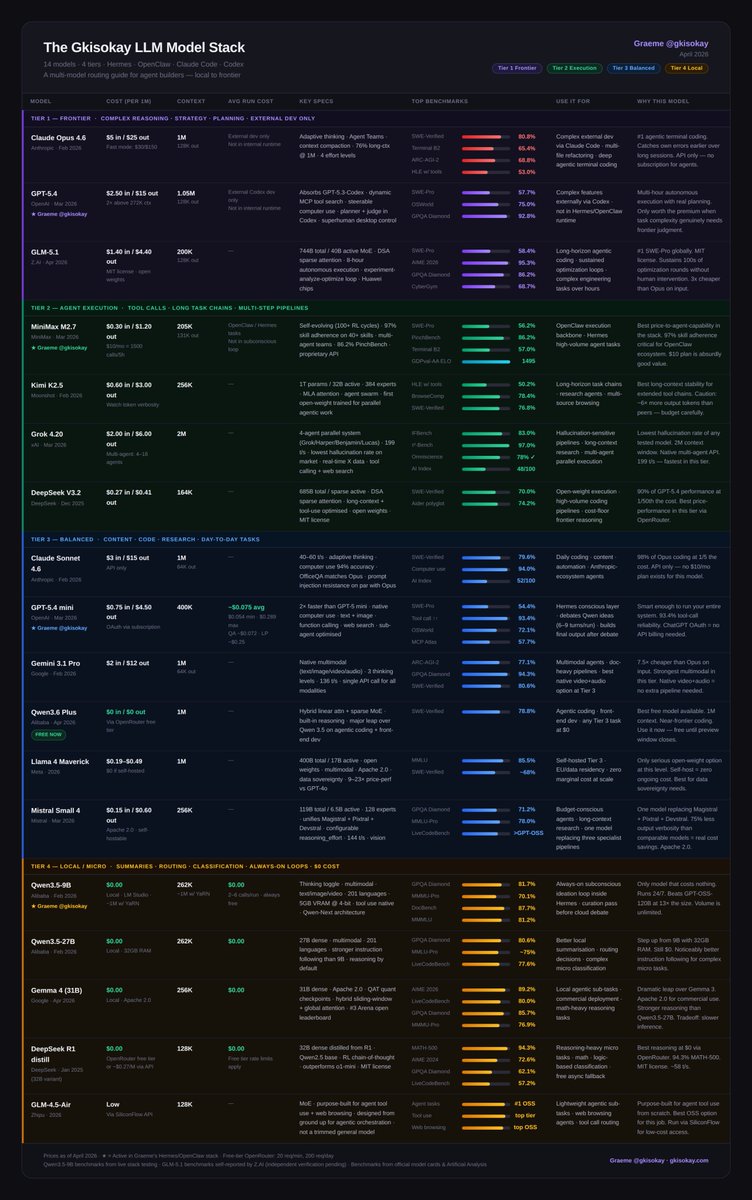
The LLM Cheat-Sheet for Hermes + OpenClaw Agents (04.12.26)
The community has flagged Claude Opus 4.6 underperforming lately while GLM 5.1 has exploded on the scene to claim frontier capabilities.
A lot has changed since the last version. Here's what moved:
GLM-5.1 just proved its frontier capabilities with #1 SWE-Pro globally, 8-hour autonomous execution, and cheaper than Opus on input. It earns a Tier 1 spot.
Grok 4.20 enters Tier 2 with the lowest hallucination rate of any tested model, a native multi-agent API running up to 16 parallel agents, and a 2M context window.
Gemini 3.1 Pro drops to Tier 3. The price and multimodal story is strong, but the new frontier bar left it behind on reasoning.
Mistral Small 4 joins Tier 3. One model replacing three specialist pipelines (reasoning, vision, agentic coding) at $0.15/M input. Apache 2.0.
Here's the full landscape: 18 models in 4 tiers.
Tier 1 - Frontier Models
- Claude Opus 4.6: #1 agentic terminal coding; watch for inconsistency reports
- GPT-5.4: superhuman computer use, real planning. and introduced a $100/month plan
- GLM-5.1: #1 SWE-Pro globally, 8-hour autonomous execution, MIT license
Tier 2 - Execution
- MiniMax M2.7: 97% skill adherence, built for agents. API only, not open weights
- Kimi K2.5: long-horizon stability, agent swarm
- Grok 4.20: lowest hallucination rate on the market, native multi-agent, 2M context
- DeepSeek V3.2: frontier reasoning at 1/50th the cost
Tier 3 - Balanced
- Claude Sonnet 4.6: 98% of Opus at 1/5 the cost
- GPT-5.4 mini: 93.4% tool-call reliability, runs on OAuth
- Gemini 3.1 Pro: best multimodal value, native video+audio in one call
- Qwen3.6 Plus: near-frontier coding, completely free via OpenRouter
- Llama 4 Maverick: open-weight, self-host at zero marginal cost
- Mistral Small 4: one model replacing three; reasoning, vision, agentic coding, Apache 2.0
Tier 4 - Local / $0 - Runs on 32GB RAM or less
- Qwen3.5-9B: always-on subconscious loop, 16GB RAM, beats models 13x its size
- Qwen3.5-27B: stronger instruction following, 32GB RAM
- Gemma 4 31B: best local reasoning, Apache 2.0, commercial-ready
- DeepSeek R1 distill: best chain-of-thought at $0
- GLM-4.5-Air: purpose-built for agent tool use and web browsing, not a trimmed general model
Full breakdown with benchmarks, costs, and use cases in the table ↓
🚨 MIT just dropped a technique that makes ChatGPT reason like a team of experts instead of one overconfident intern.
It’s called “Recursive Meta-Cognition” and it outperforms standard prompts by 110%.
Right now, if you want an AI to solve a problem, you ask one question. The AI gives you one answer.
If it’s wrong, you never know.
It’s like asking a random person on the street for medical advice and just trusting them..
MIT researchers realized this is a massive structural flaw.
They asked a simple question. What if AI could check its own work from multiple angles before giving you the final answer?
Not just "think step by step."
Actually verify. Score confidence. Flag uncertainty.
They built a framework called Recursive Meta-Cognition.
And the results rewrite the rules of prompt engineering.
Instead of a single, blind output, the technique forces the AI to break a complex problem into smaller pieces and interrogate its own logic from multiple perspectives.
But here is the secret sauce.
It assigns a strict confidence score to every single reasoning path it takes, from 0.0 to 1.0.
Paths below 0.4 are instantly rejected. Paths above 0.8 are trusted. Anything in between? The AI stops and tells you: "I am not sure, and here is why."
No more hallucinations. No more fake confidence.
If you are running a business and relying on AI to outline a SaaS marketing strategy, analyze data, or drive operational efficiency, a hallucination isn't just an error. It is a loss of profit.
With a standard prompt, the AI gives you ONE answer. It sounds confident. It might be completely wrong for your specific situation.
With Recursive Meta-Cognition, the AI spots its own hidden assumptions. It tests its logic. It catches its own errors before they ever reach your screen.
We've been treating AI like a vending machine. Put a prompt in, get a result out.
But true intelligence doesn't just answer questions.
It questions its own answers.