@OwainEvans_UK What do you think: where does an inductive bias towards true statements come from? Did you test this with open data models, Pythia or Olmo, where you can check negation in data mix? Might it be possible to run controlled experiments in <100M models?
It's interesting how the usage of LLMs has been quickly progressing to higher levels of abstraction:
1. prompt engineering
2. context engineering
3. agent scaffold engineering (we are here now)
4. multi-agent architecture engineering
5. ???
It's also curious how people don't discuss the previous stages that much anymore. Like, no one discusses prompt engineering now, and discussions around context engineering are becoming less frequent.
1/ Evaluating a single agent harness is hard. Evaluating a multi-agent system? That's a whole different problem.
Most eval tools treat the model as the unit of analysis. But in multi-agent systems, the system is what matters.
That's why we built MASEval 🧵
#Agents#AI#Eval
Great work lead by @anmgoel on how fragile contextual integrity can be in LLMs.
This work shows that contextual privacy degrades easily during fine-tuning on benign data and common safety benchmarks don't pick this up.
#AISecurity#AIAgents
🚨 Fine-tuning your model to be more helpful or empathetic might be making it less private, without you noticing.
In our latest work, we show that benign fine-tuning can silently break contextual privacy in language models while safety & general capabilities appear intact.
⬇️
Excited to share our preprint! We show that sustained macrophage and B cell responses are essential for heart regeneration in Mexican cavefish, helping uncover why surface fish heal but cavefish scar 🫀🐟. Check out the full story:
https://t.co/B9CBwOaSds
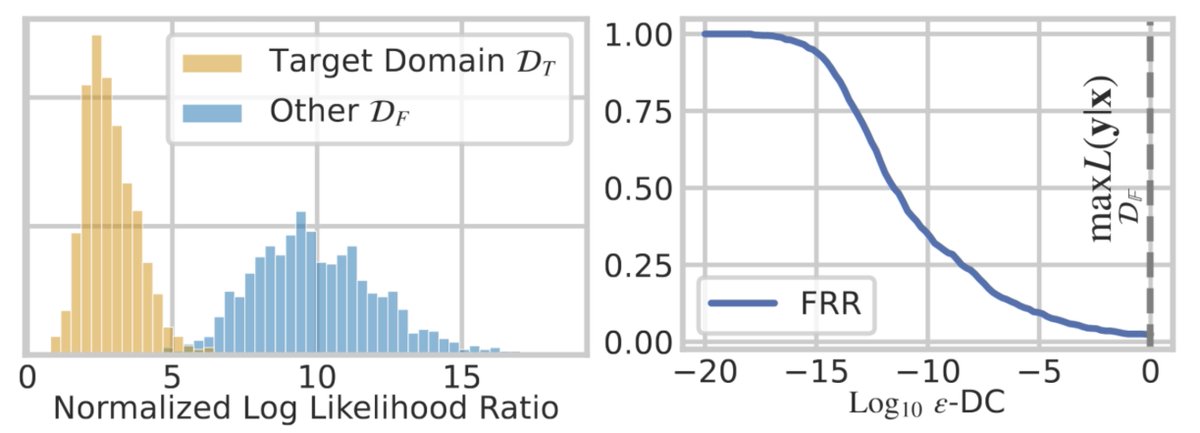
To obtain such certificates, we present a simple, scalable and powerful algorithm: VALID. Remarkably, for each unwanted response it provides a global bound in prompt space 🚀
(6/7)